







你是否和我一样遇到如下问题:
- 本地电脑没有GPU算力
- Huggingface登录不了
- 搭建环境太浪费时间
推荐一个网站给你,魔搭社区,他能一站式解决以上的问题,快速下载开源大模型。关键,能赠送学习期间的免费算力给到你,入门学习是够了。当然前提也需要你绑定阿里云。

经过注册魔搭账号、绑定阿里云(没有的需要注册阿里云账号)以后,你会获得8U32G+16或24G显存的100小时GPU算力资源。
绑定以后你就可以自由的玩耍了。注意,24G显存的可能会存在资源紧张的情况,可以切换到弹性计算,使用16G显存的进行玩耍。
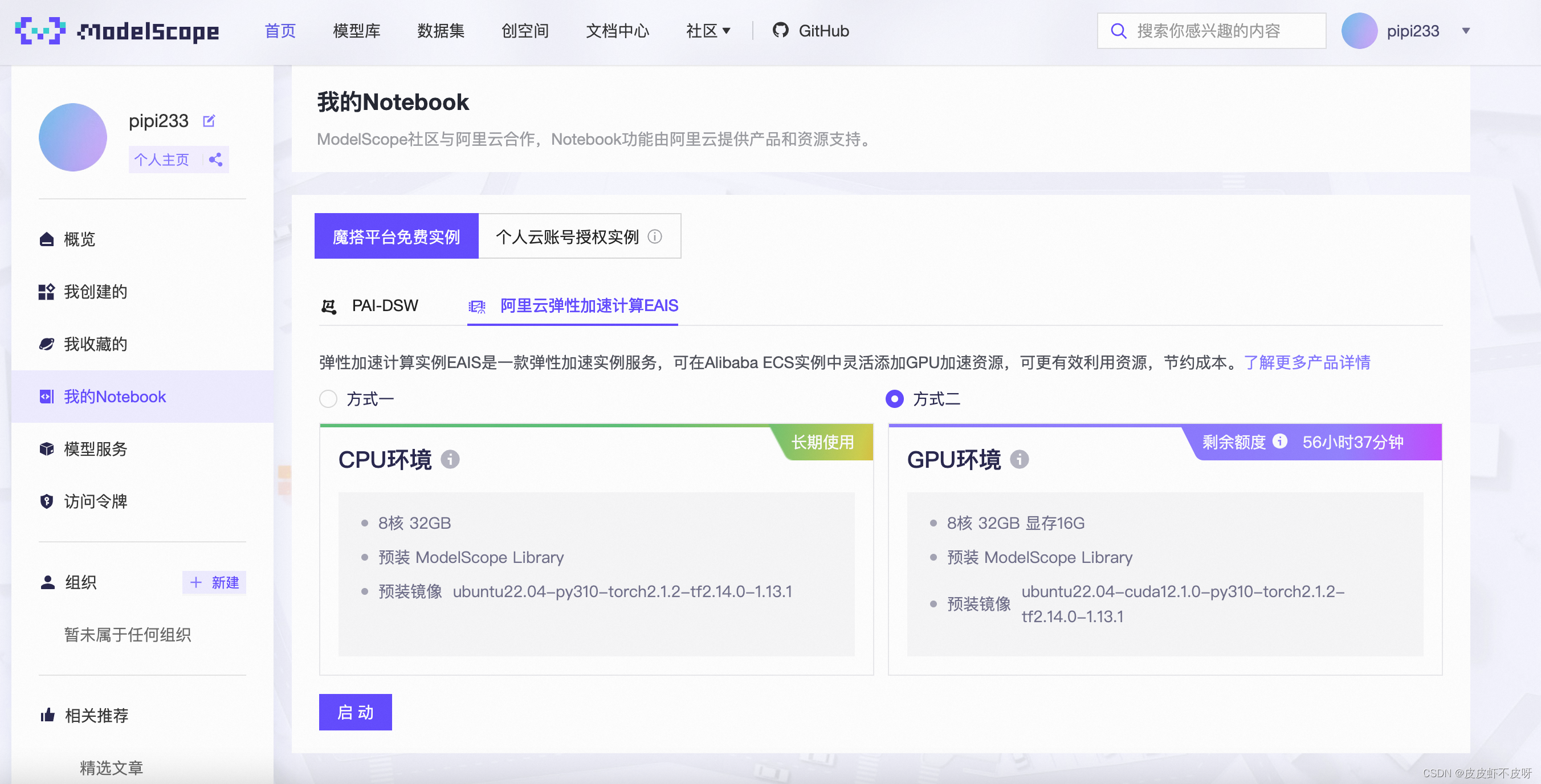
启动后就能直接开整,完全不用考虑搭建环境的问题。因为已经预装好了cuda、pytorch等环境。最重要的是随用随启,自动关闭等功能。如果你需要长期运行,那就当我没说。
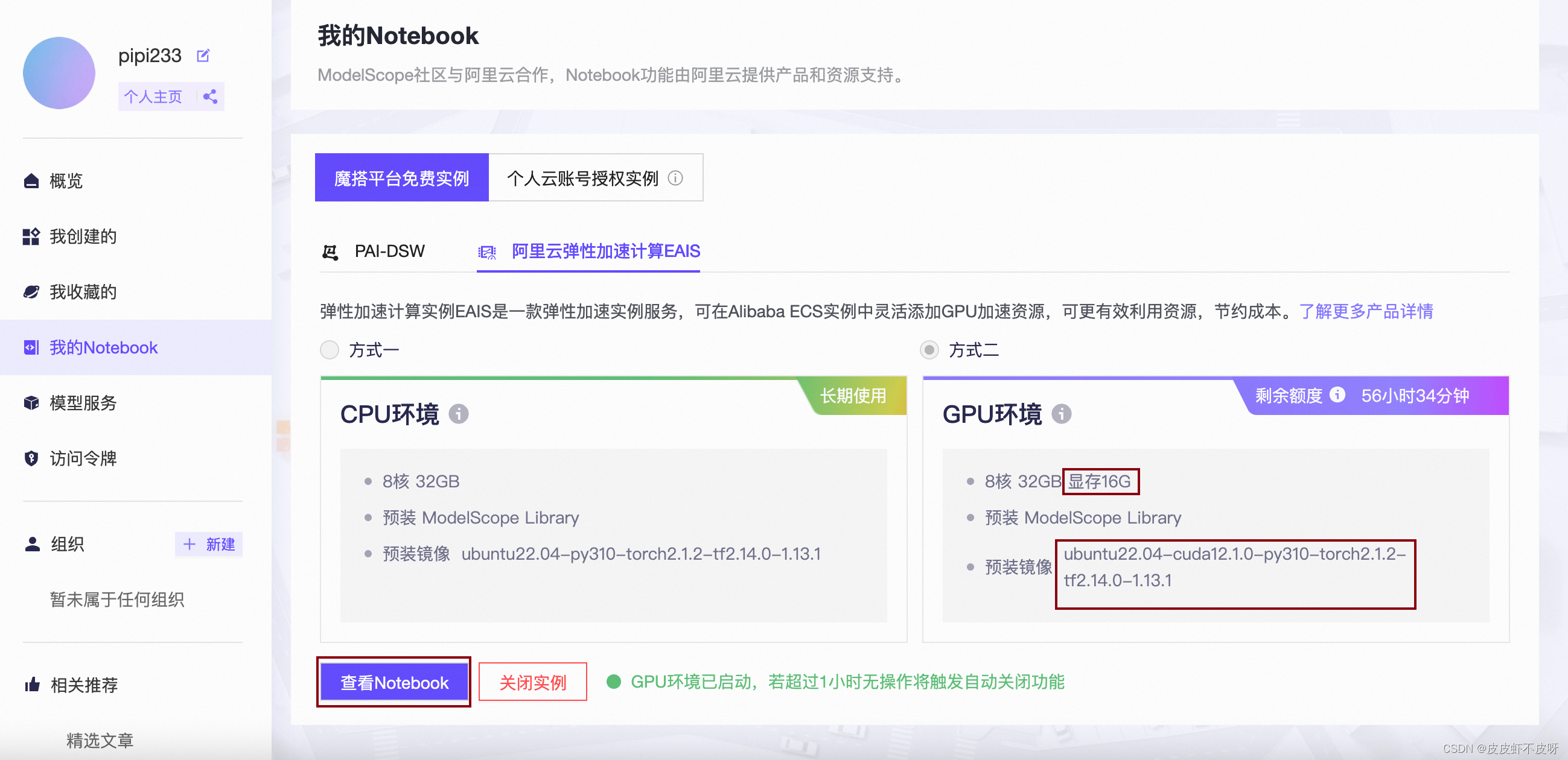
进来其实就是jupyter lab的这种页面,可以切换命令行,也可以用jupyter,在线学习一些开源大模型的部署等等。
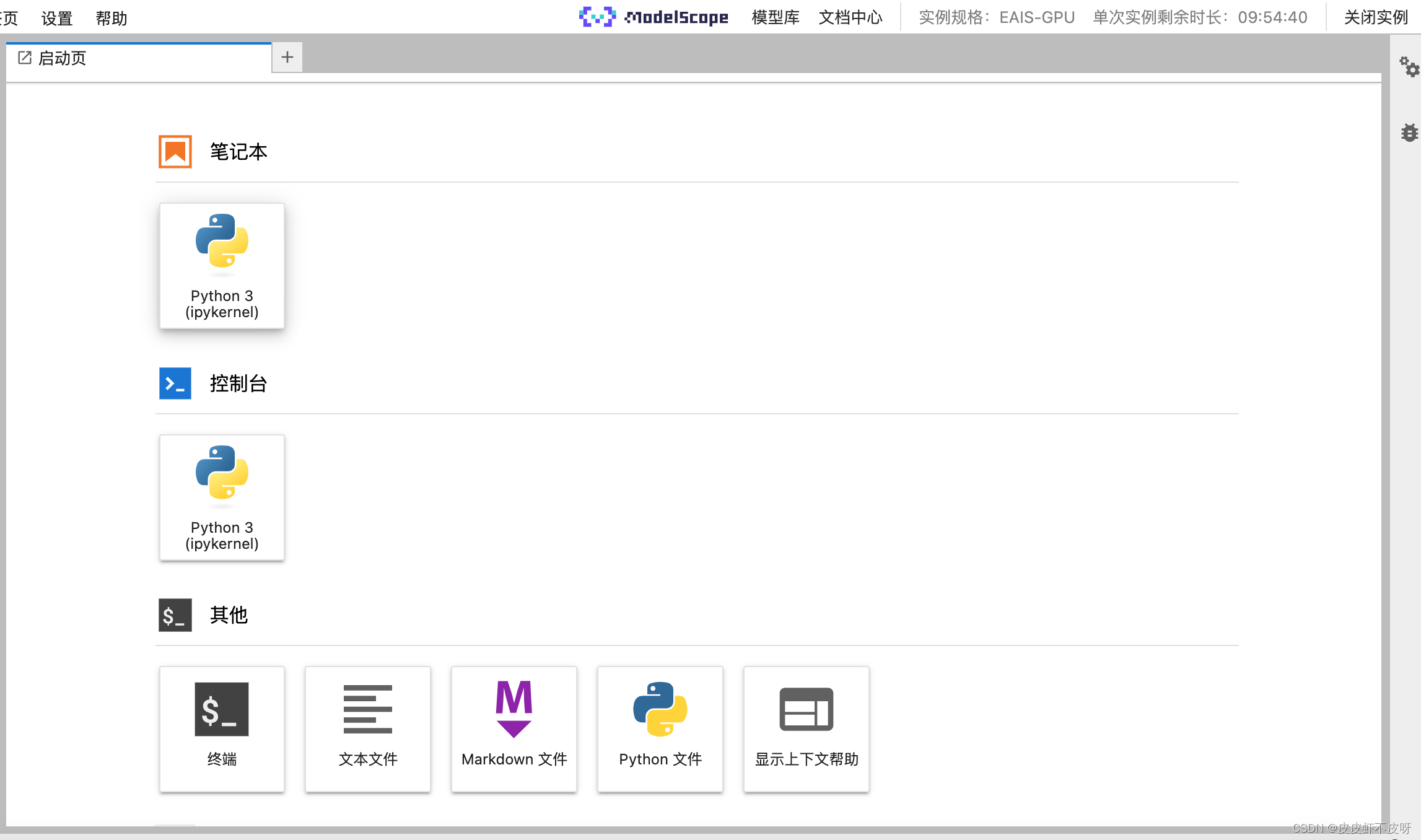
简单演示一下模型下载及使用
选择qwen1.5-1.8B-Chat模型
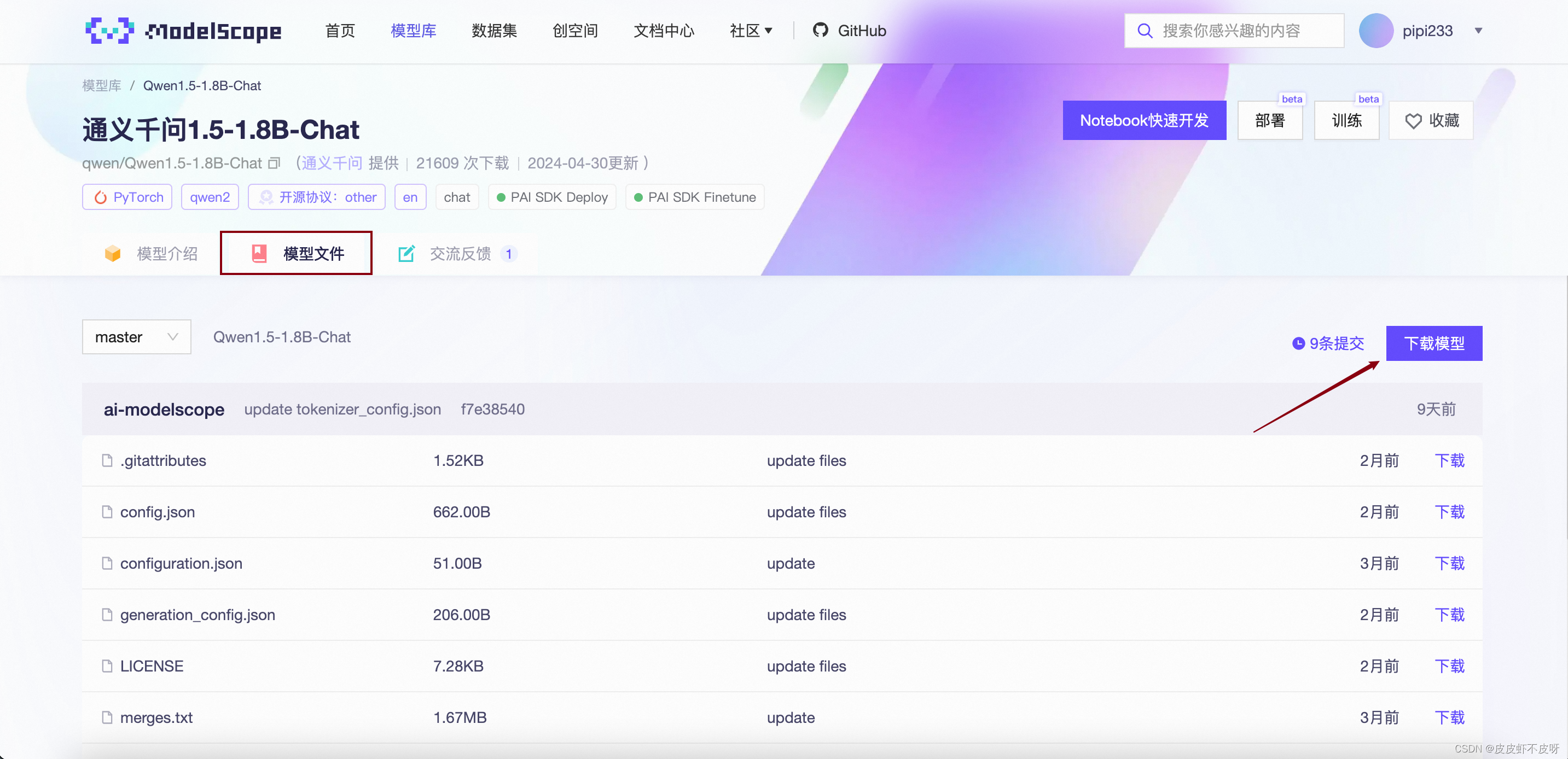
SDK下载(也可以直接运行下载,为了完整介绍采用SDK下载,嘻嘻)
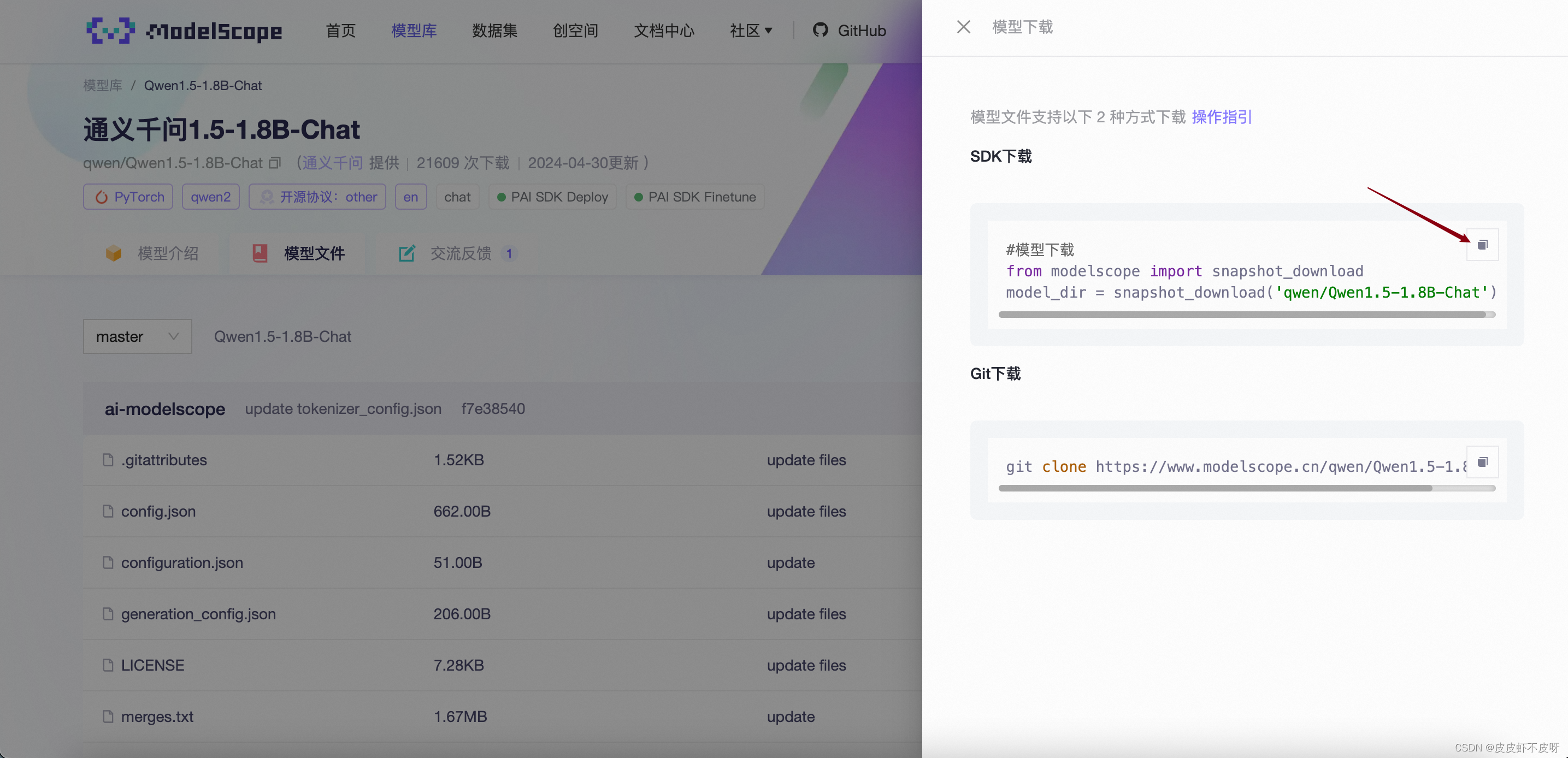
打开Notebook,开始下载模型,速度杠杠的。
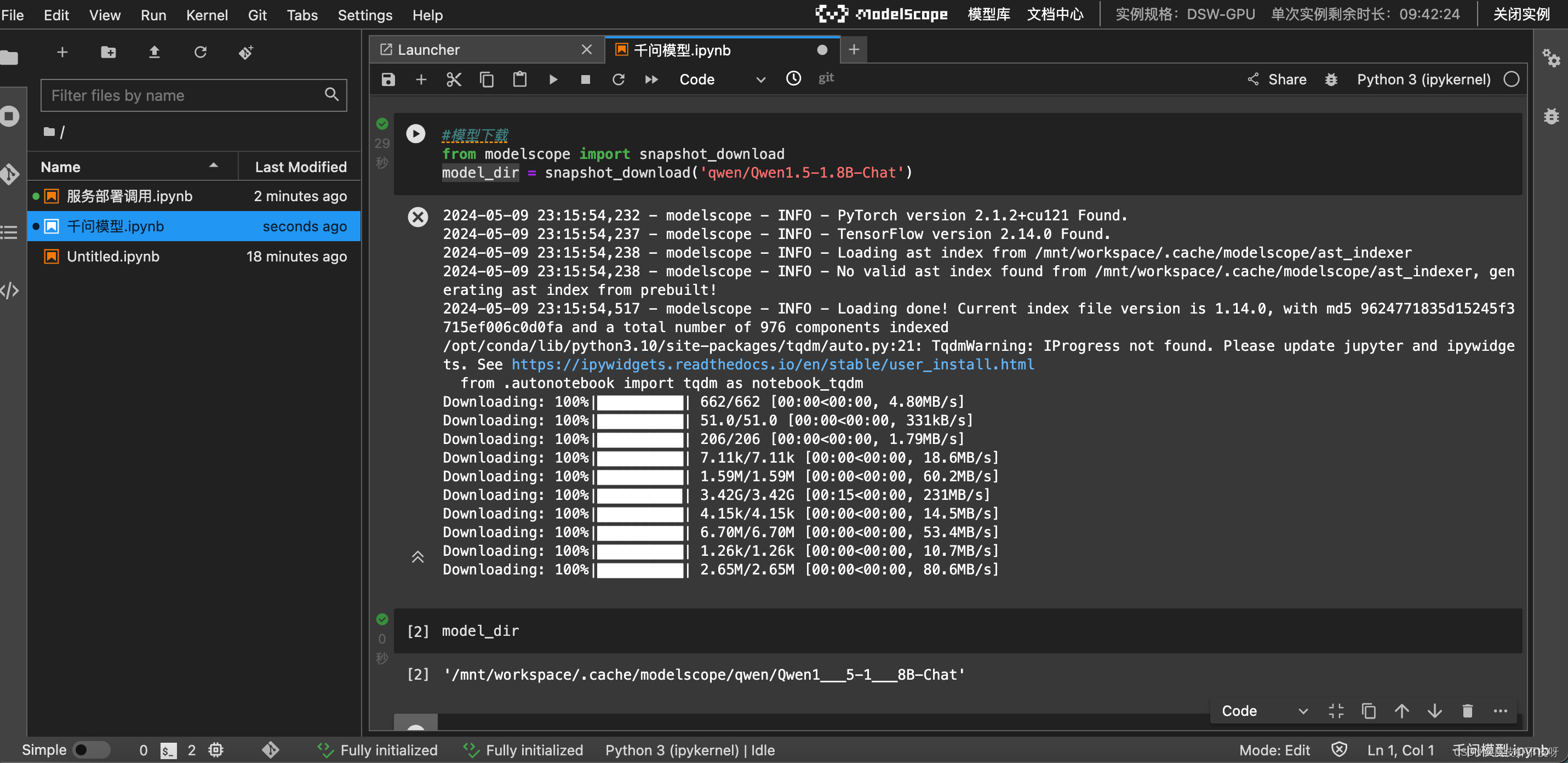
按照模型介绍的代码,拿过来跑一下试试。注意:这个记得改一下路径,模型路径换成model_dir。
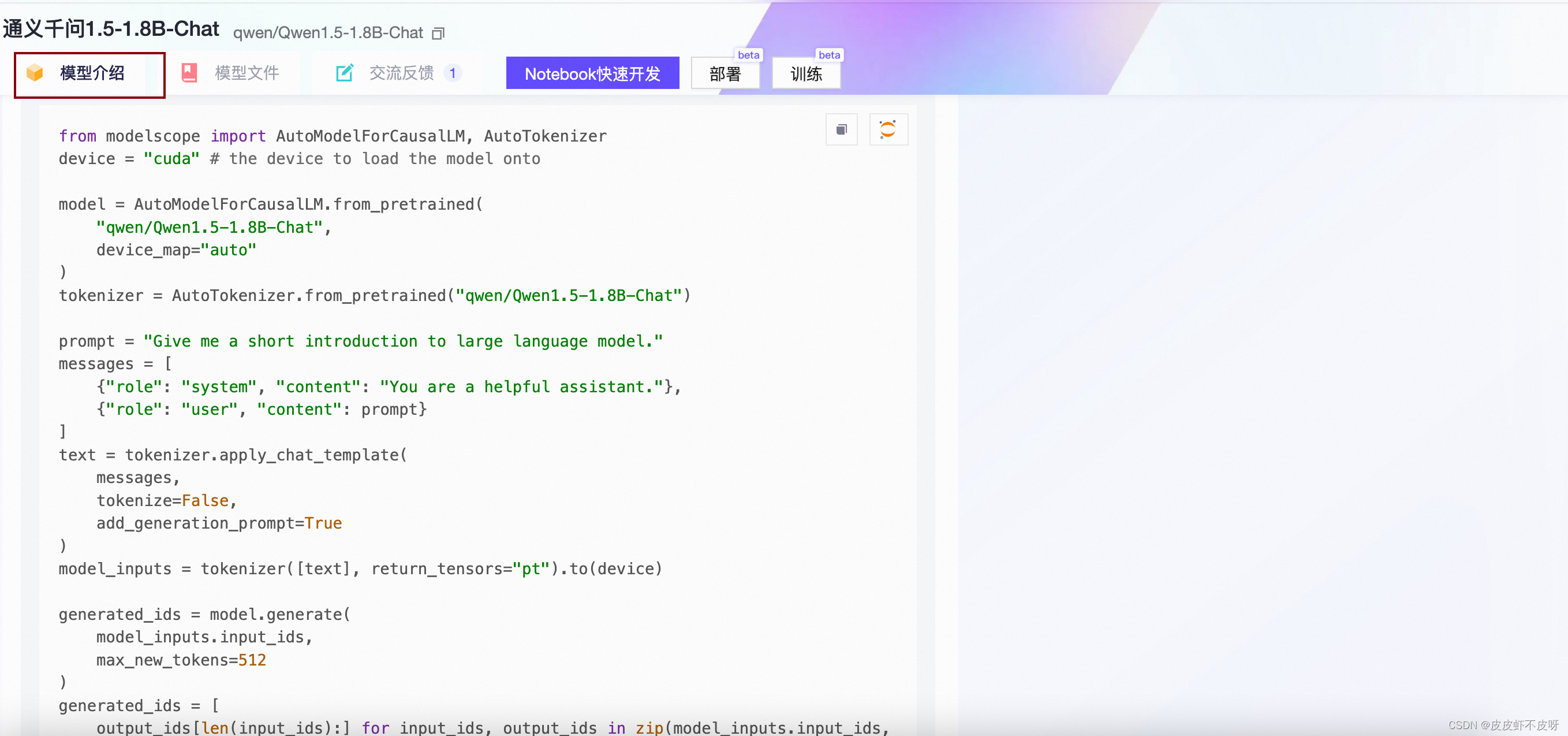
看到response,你是否和我一样有点小激动了!
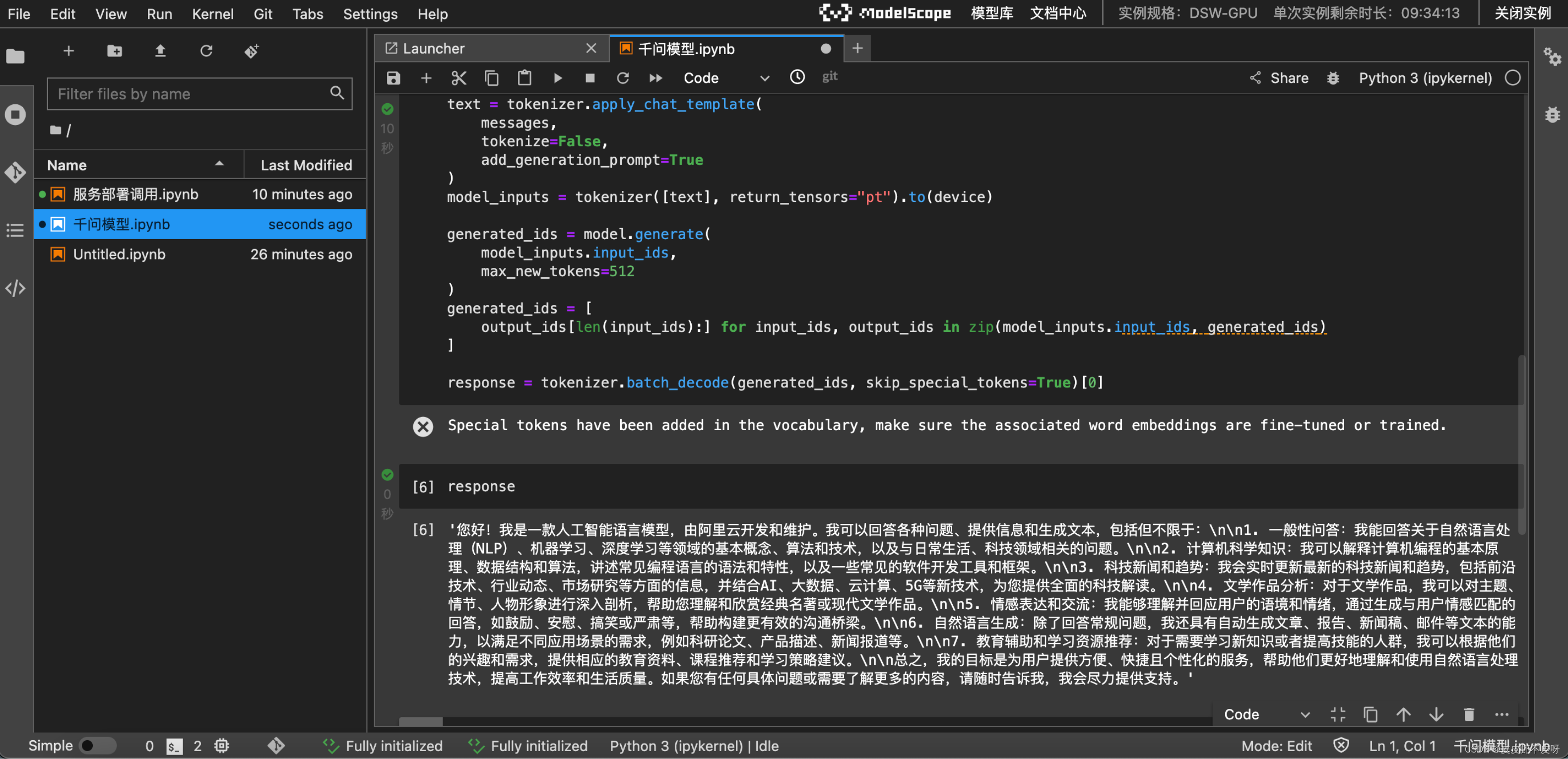
使用大模型部署工具快速完成开源大模型部署与调用
当然,除了可以使用上述方法进行开源大模型部署调用外,我们也可以使用一些大模型部署和调用工具,来快速完成各类大模型部署。目前来看,最常用的开源大模型部署和调用工具有两类,其一是ollama、其二是vLLM。这两款工具定位类似,但功能实现各有侧重。ollama更加侧重于为个人用户提供更加便捷的开源模型部署和调用服务,ollama提供了openai风格的调用方法、GPU和CPU混合运行模式、以及更加便捷的显存管理方法,而vLLM则更加适用于企业级应用场景,采用的是服务端和客户端分离的模式,更适合企业级项目使用。
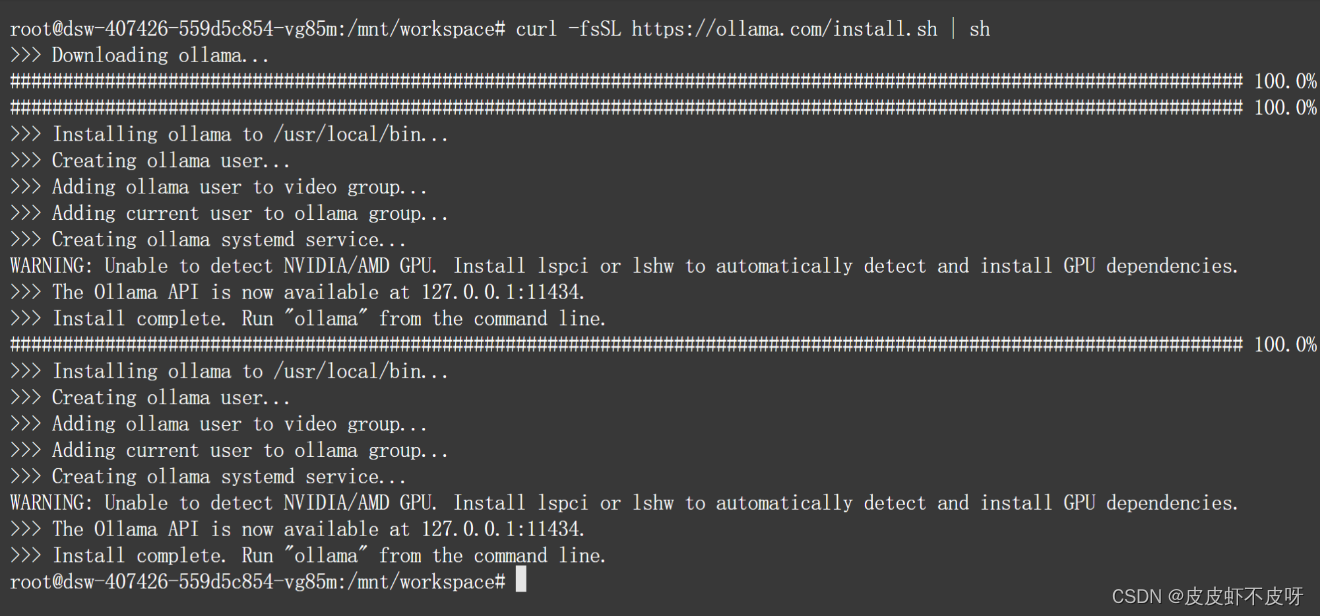
这里我们以ollama为例,介绍借助工具部署调用开源大模型方法。命令行窗口执行这几行代码就好了,下载的时候会比较慢,截图直接取自菜菜老师资料:
# 下载ollama工具
curl -fsSL https://ollama.com/install.sh | sh
# 开启ollama服务
ollama serve
# 调用qwen1.5大模型
ollama run qwen:1.8b
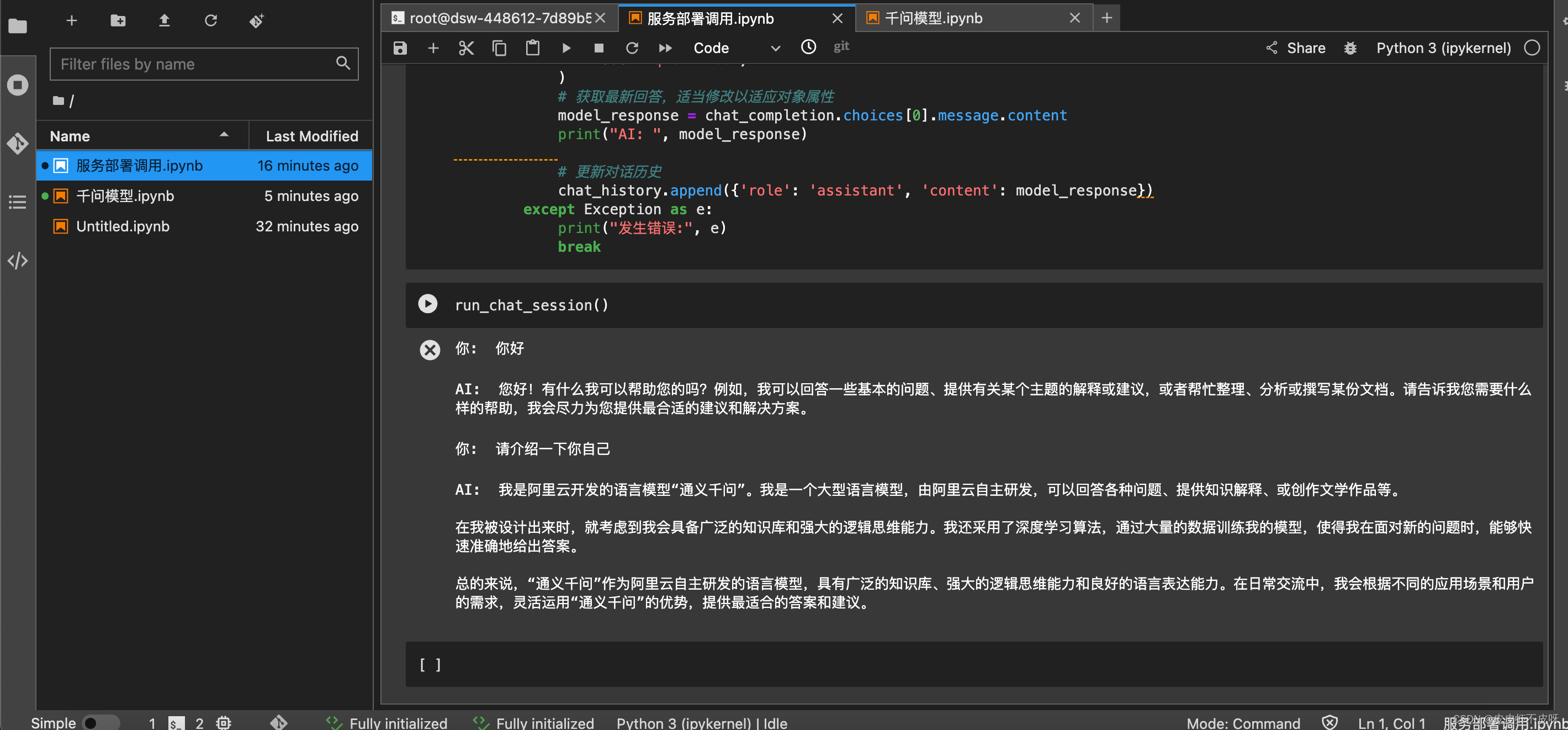
编写一个基于Qwen1.5-1.8b模型的多轮对话函数,实现在本地调用就OK了。代码放在文末,需要请自取。
文末,嘻嘻!!!觉得有用帮忙点点赞和收藏!!!
# pip install openai安装
from openai import OpenAI
def run_chat_session():
# 初始化客户端
client = OpenAI(
base_url='http://localhost:11434/v1/',
api_key='ollama', # API key is required but ignored for local model
)
# 初始化对话历史
chat_history = []
# 启动对话循环
while True:
# 获取用户输入
user_input = input("你: ")
# 检查是否退出对话
if user_input.lower() == 'exit':
print("退出对话。")
break
# 更新对话历史
chat_history.append({'role': 'user', 'content': user_input})
# 调用模型获取回答
try:
chat_completion = client.chat.completions.create(
messages=chat_history,
model='qwen:1.8b',
)
# 获取最新回答,适当修改以适应对象属性
model_response = chat_completion.choices[0].message.content
print("AI: ", model_response)
# 更新对话历史
chat_history.append({'role': 'assistant', 'content': model_response})
except Exception as e:
print("发生错误:", e)
break















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









