






排序适用情况
时间复杂度分析
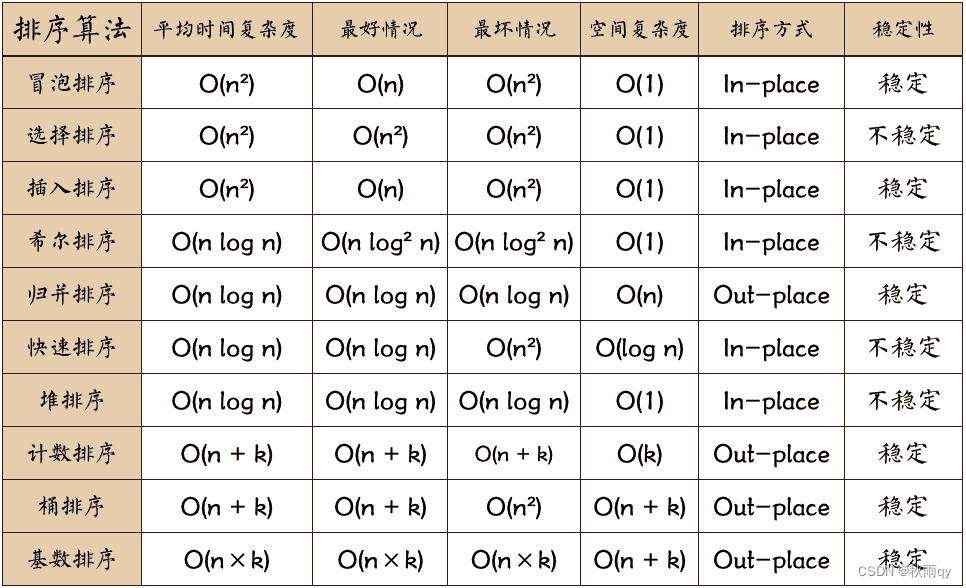
(1)当数据规模较小时,可以使用简单的插入排序或者选择排序。
(2)当文件的初态已经基本有序,可以用插入排序和冒泡排序。
(3)当数据规模较大时,应用速度最快的排序算法,可以考虑使用快速排序。当记录随机分布的时候,快速排序平均时间最短,但是出现最坏的情况,这个时候的时间复杂度是O(n^2),且递归深度为n,所需的占空间为O(n)。
(4)堆排序不会出现快排那样最坏情况,且堆排序所需的辅助空间比快排要少,但是这两种算法都不是稳定的,要求排序时是稳定的,可以考虑用归并排序。
(5)归并排序可以用于内部排序,也可以使用于外部排序。在外部排序时,通常采用多路归并,并且通过解决长顺串的合并,缠上长的初始串,提高主机与外设并行能力等,以减少访问外存额外次数,提高外排的效率。
从小到大排序
1 冒泡排序

被动的将最大值送到最右边
1、比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2、对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
3、针对所有的元素重复以上的步骤,除了最后一个。
4、持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
原地修改数组:
void bubbleSort(vector<int>& nums) {
int len = nums.size();
for (int i = 0; i < len - 1; ++i) { // 外层只需n-1
for (int j = 0; j < len - 1 - i; ++j) {
if (nums[j] > nums[j + 1]) // 最大的放在数组最右
swap(nums[j], nums[j + 1]);
}
}
}
优化:算是一种剪枝
假如从开始的第一对到结尾的最后一对,相邻的元素之间都没有发生交换的操作,这意味着右边的元素总是大于等于左边的元素,此时的数组已经是有序的了,我们无需再对剩余的元素重复比较下去了。
void bubbleSort2(vector<int>& nums) {
int len = nums.size();
bool flag = false;
for (int i = 0; i < len - 1; ++i) {
flag = false;
for (int j = 0; j < len - 1 - i; ++j) {
if (nums[j] > nums[j + 1]) {
flag = true;
swap(nums[j], nums[j + 1]);
}
}
if (!flag)//说明没有交换,则表明[0,len-i-1]已经是有序的了
break;
}
}
2 选择排序

主动将最小值送到最左边
void selectSort(vector<int>& nums) {
int len = nums.size();
int minIndex = 0;
for (int i = 0; i < len; ++i) {
minIndex = i;
for (int j = i + 1; j < len; ++j) {
if (nums[j] < nums[minIndex]) minIndex = j;
}
swap(nums[i], nums[minIndex]);
}
}
3 插入排序

与选择排序思路一致,从左到右排序
void insertionSort(vector<int>& nums) {
int len = nums.size();
for (int i = 1; i < len; ++i) {
int n = i;
while(n > 0){
if(nums[n-1] > nums[n])
swap(nums[n], nums[n-1]);
else
break; // 左边的数组都是有序的了
n--;
}
}
}
4 快速排序
时间复杂度O(N*log(N))
nums = [15,19,2,18,24,4,20]
选择一个区间,将最左边的元素15作为中间点元素,然后将数组分成两个区间:
小于等于15的元素放其左侧,大于15的元素放其右侧
[2, 4],[15],[19, 18, 24, 20]。
然后将这两个区间[2, 4]与[19, 18, 24, 20]按照相同的步骤(选最左侧元素。。。)
退出条件:
如果区间长度为1,直接归位
双指针递归法
1、输入输出
void quickSort(vector<int>& nums, int global_left, int global_right)
2、退出条件
if(global_left > global_right) return;
3、单层逻辑
首先存储这个区间的left和right指针,找到最左边元素nums[left]
int left = global_left;
int right = global_right;
int key = nums[global_left];
然后根据key值放元素。
首先,right从右往左走,选比key小的移到前面
// 直到选出一个不符合要求的
while(left != right && nums[right] > key) right--;
if(left != right){
nums[left] = nums[right];
left++;
}
然后,left从左往右走, 将比key大的移到后面
// 直到选出一个不符合要求的
while(left != right && nums[left] < key) left++;
if(left != right){
nums[right] = nums[left];
right--;
}
最后,循环这两步
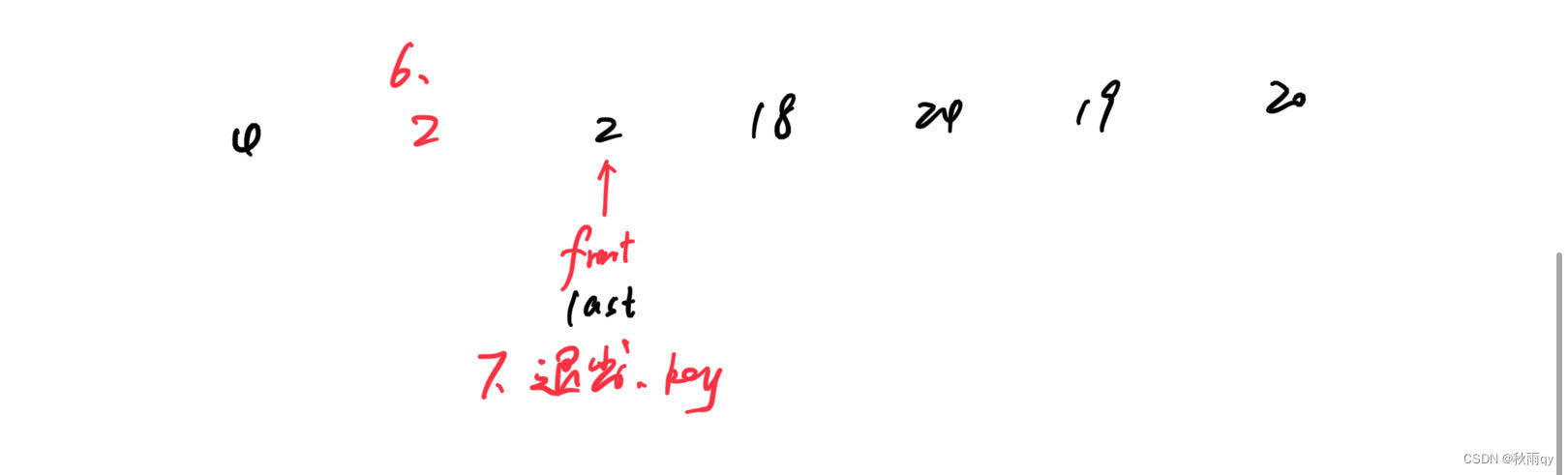
while(front < last){
从后往前走
从前往后走
}
nums[last] = key;
最后left和right应该重合
放完元素后进行递归,以key值的索引为两个区间的分界线
quickSort(nums, left, last - 1);
quickSort(nums, last + 1, right);

整合代码
// front 和 last 代表区间
void quickSort(vector<int>& nums, int global_left, int global_right) {
if(global_left >= global_right) return;
int left = global_left;
int right = global_right;
int key = nums[global_left];
while(left != right){
while(left != right && nums[right] > key) right--;
if(left != right){
nums[left] = nums[right];
left++;
}
while(left != right && nums[left] < key) left++;
if(left != right){
nums[right] = nums[left];
right--;
}
}
nums[left] = key;
quickSort(nums, global_left, right - 1);
quickSort(nums, right + 1, global_right);
}
5 堆排序
1

2


堆是一种完全二叉树的数据结构,分为和小根堆
大根堆:每个节点的值都大于或等于其左右孩子节点的值。注意:没有要求节点的左孩子的值和右孩子的值的大小关系。
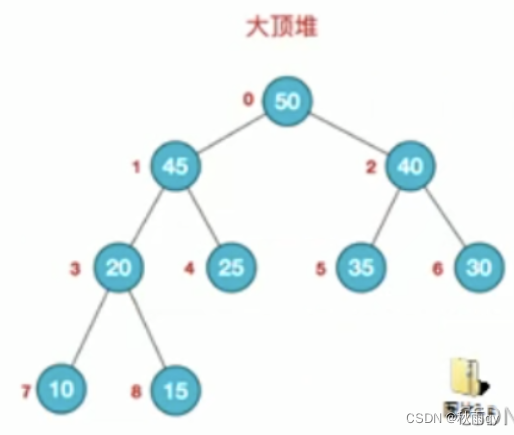
小根堆:每个节点的值都小于或等于其左右孩子节点的值
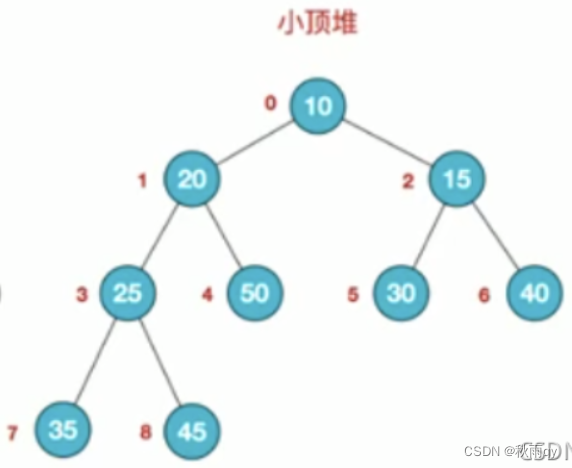
基本思想:
- 将待排序序列构造成一个大顶堆;
- 此时整个序列的最大值就是顶堆的根节点;
- 将其与末尾元素进行交换,此时末尾就为最大值;(数组前后两个元素交换)
- 然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。
反复执行1-4,便能得到一个有序序列了。
可以看到在构建大顶堆的过程中,元素的个数逐渐减少,最后就得到一个有序序列了。
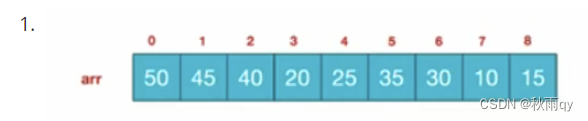
难点:如何将一个二叉树(顺序遍历为一个数组)转换为大根堆?
// 堆的下沉调整 大根堆
void siftDown(vector<int>& arr, int i, int size) {
int val = arr[i];
while (i < size / 2) { // i <= (size - 2) / 2 = size / 2 - 1 等价于 i < size / 2
int child = 2 * i + 1; //左孩子
if (child + 1 < size && arr[child + 1] > arr[child]) {
child = child + 1; // 记录值比较大的孩子
}
if (arr[child] > val) {
arr[i] = arr[child];
i = child; // i继续指向它的孩子,继续调整,一直调整到最后有孩子的节点处
} else {
break;
}
arr[i] = val;
}
}
void buildMaxHeap(vector<int>& arr, int len) {
// 这儿i=(len-1-1)/2,i=(len-1)/2,i=len/2,其中len减1减2不减都可以
for (int i = (len - 1 - 1) / 2; i >= 0; i--)
{
siftDown(arr, i, len);
}
}
void heapSort(vector<int>& arr) {
int len = arr.size();
// 从第一个非叶子节点 成为大根堆
buildMaxHeap(arr, len);
//把堆顶元素和末尾元素进行交换,从堆顶进行下沉操作 只是大根堆 并非升序
for (int i = len - 1; i >= 0; i--) {
int tmp = arr[0];
arr[0] = arr[i];
arr[i] = tmp;
siftDown(arr, 0, i); //第三个参数表示参与调整元素的个数
}
}
6 归并排序
1

2

申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
设定两个指针,最初位置分别为两个已经排序序列的起始位置;
比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
重复步骤 3 直到某一指针达到序列尾;
将另一序列剩下的所有元素直接复制到合并序列尾。
递归版
void mergeSortCore(vector<int>& data, vector<int>& dataTemp, int low, int high) {
if (low >= high) return;
int len = high - low, mid = low + len / 2;
int start1 = low, end1 = mid, start2 = mid + 1, end2 = high;
mergeSortCore(data, dataTemp, start1, end1);
mergeSortCore(data, dataTemp, start2, end2);
int index = low;
while (start1 <= end1 && start2 <= end2) {
dataTemp[index++] = data[start1] < data[start2] ? data[start1++] : data[start2++];
}
while (start1 <= end1) {
dataTemp[index++] = data[start1++];
}
while (start2 <= end2) {
dataTemp[index++] = data[start2++];
}
for (index = low; index <= high; ++index) {
data[index] = dataTemp[index];
}
}
void mergeSort(vector<int>& data) {
int len = data.size();
vector<int> dataTemp(len, 0);
mergeSortCore(data, dataTemp, 0, len - 1);
}
7 希尔排序

8 sort(nums.begin(), nums.end())
STL里sort算法用的是什么排序算法?
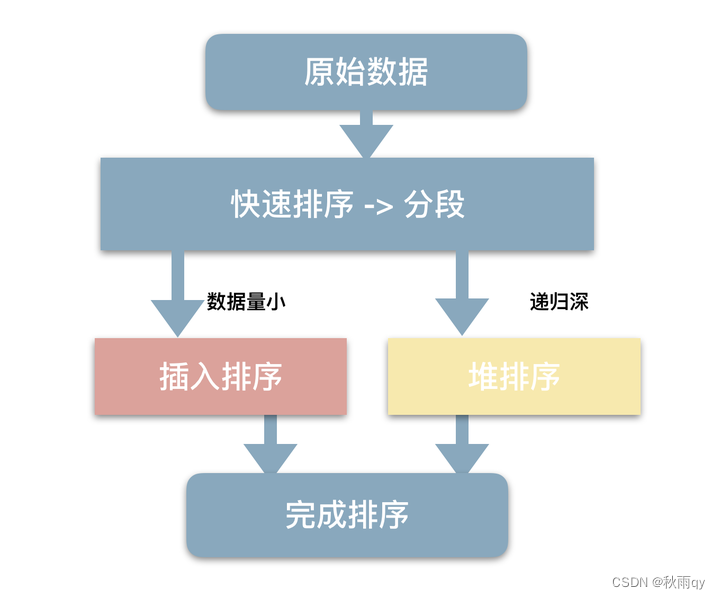
毫无疑问是用到了快速排序,但不仅仅只用了快速排序,还结合了插入排序和堆排序。
结合 快-插-堆 三种排序算法。
问题轰炸:
- 数据量大和数据量小都适合用快速排序吗?
- 快速排序的时间复杂度不是稳定的nlogn,最坏情况会变成n^2,怎么解决复杂度恶化问题?
- 快速排序递归实现时,怎么解决递归层次过深的问题?
- 递归过深会引发什么问题?
- 怎么控制递归深度?如果达到递归深度了还没排完序怎么办?
适用对象
序列式容器中的stack、queue和priority-queue都有特定的出入口,不允许用户对元素排序。
只有vector、deque,适用sort算法。
实现逻辑
STL的sort算法,数据量大时采用QuickSort快排算法,分段排序。分段大于16才递归。
一旦分段后的数据量小于某个门槛(16),为避免QuickSort快排的递归调用带来过大的额外负荷,就改用插入排序。
如果递归层次过深,还会改用HeapSort堆排序。
总结:数据量大快排,区间小于16的采用插排,快排递归深度恶化改用堆排
具体代码
源文件:/usr/include/c++/4.2.1/bits/stl_algo.h
template<typename _RandomAccessIterator>
inline void
sort(_RandomAccessIterator __first, _RandomAccessIterator __last)
{
typedef typename iterator_traits<_RandomAccessIterator>::value_type
_ValueType;
// concept requirements
__glibcxx_function_requires(_Mutable_RandomAccessIteratorConcept<
_RandomAccessIterator>)
__glibcxx_function_requires(_LessThanComparableConcept<_ValueType>)
__glibcxx_requires_valid_range(__first, __last);
if (__first != __last)
{
//快速排序+插入排序
std::__introsort_loop(__first, __last,
std::__lg(__last - __first) * 2);
//插入排序
std::__final_insertion_sort(__first, __last);
}
}
其中__lg函数是计算递归深度,用来控制分割恶化,当递归深度达到该值改用堆排序,因为堆排序是时间复杂度恒定为nlogn:
template<typename _Size>
inline _Size
__lg(_Size __n)
{
_Size __k;
for (__k = 0; __n != 1; __n >>= 1)
++__k;
return __k;
}
先来看,__introsort_loop 快排实现部分:对于区间大于16的继续递归,如果递归深度恶化改用堆排。
template<typename _RandomAccessIterator, typename _Size>
void
__introsort_loop(_RandomAccessIterator __first,
_RandomAccessIterator __last,
_Size __depth_limit)
{
typedef typename iterator_traits<_RandomAccessIterator>::value_type
_ValueType;
//_S_threshold=16,每个区间必须大于16才递归
while (__last - __first > int(_S_threshold))
{
//达到指定递归深度,改用堆排序
if (__depth_limit == 0)
{
std::partial_sort(__first, __last, __last);
return;
}
--__depth_limit;
_RandomAccessIterator __cut =
std::__unguarded_partition(__first, __last,
_ValueType(std::__median(*__first,
*(__first
+ (__last
- __first)
/ 2),
*(__last
- 1))));
std::__introsort_loop(__cut, __last, __depth_limit);
__last = __cut;
}
}
插排
template<typename _RandomAccessIterator>
void
__final_insertion_sort(_RandomAccessIterator __first,
_RandomAccessIterator __last)
{
if (__last - __first > int(_S_threshold))
{
//先排前16个
std::__insertion_sort(__first, __first + int(_S_threshold));
//后面元素遍历插入到前面有序的正确位置
std::__unguarded_insertion_sort(__first + int(_S_threshold), __last);
}
else
std::__insertion_sort(__first, __last);
}















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











