






grafana查询csv
下载安装插件
csv-datasource插件
下载对应操作系统版本的插件
解压至grafana的plugin目录
unzip marcusolsson-csv-datasource-0.6.18.linux_amd64.zip
修改grafana.ini配置,添加以下内容,以允许访问本地文件,否则在添加数据源时会报错
[plugin.marcusolsson-csv-datasource]
allow_local_mode = true
重启grafana,我这用的docker启动的服务,根据情况来
docker restart grafana
配置数据源如下,注意如果是容器启动的grafana,请将需要展示的csv文件存放到容器挂载路径,并在配置中配置容器内对应路径
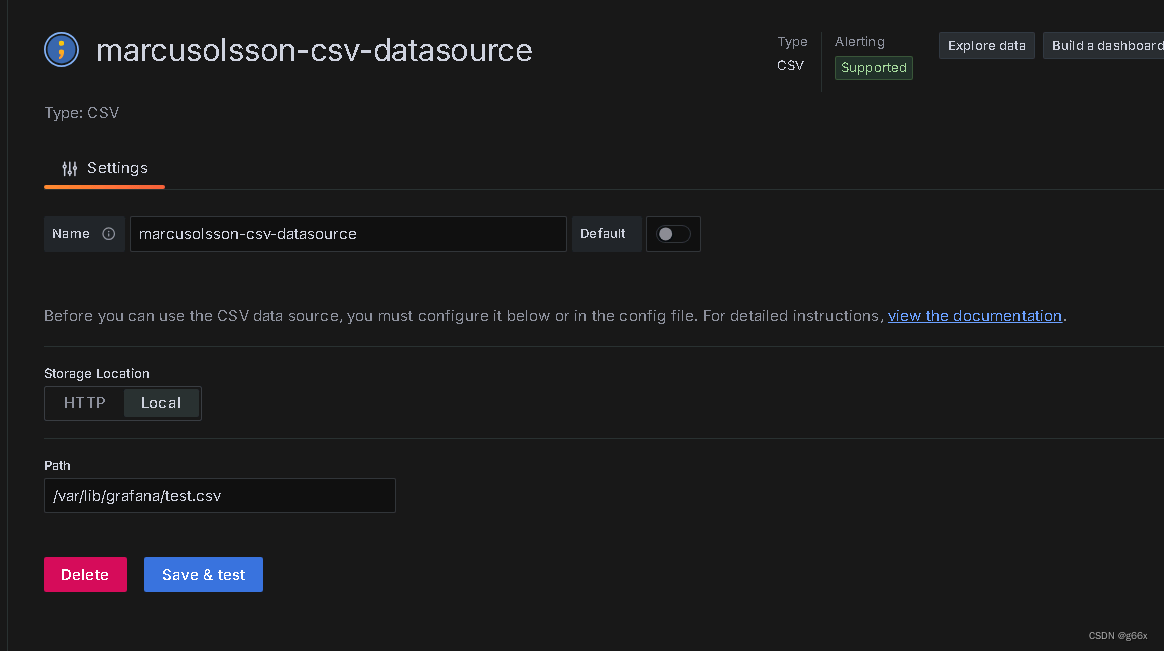
点击 Save & test
创建dashboard
test.csv内容如下
x,y
k,g
展示如下
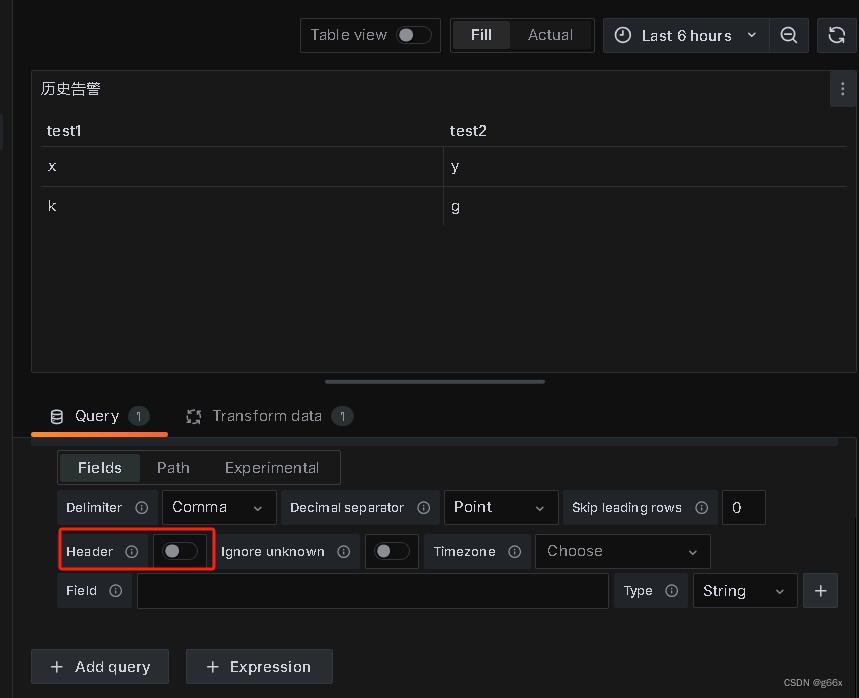
视情况配置,可以指定分隔符,字段类型等
如果你的csv的第一列不是列的名称,可以取消选择Header按钮并自定义,否则会自动将csv文件的第一行视为header

















 632
632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









