







视频教程
https://www.bilibili.com/video/BV186tjeZE3C/
下载代码
代码地址:https://github.com/voxelmorph/voxelmorph
拉取代码
git clone https://github.com/voxelmorph/voxelmorph
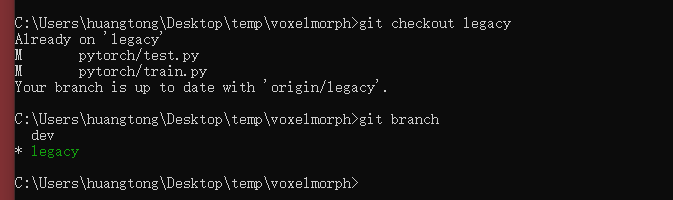
进入到voxelmorch文件夹,切换到legacy分支,pytorch版本放在pytorch文件夹中
# 切换分支(我已经切换了,所以它提示我已经是这个分支了)
git checkout legacy
# 查看当前分支
git branch
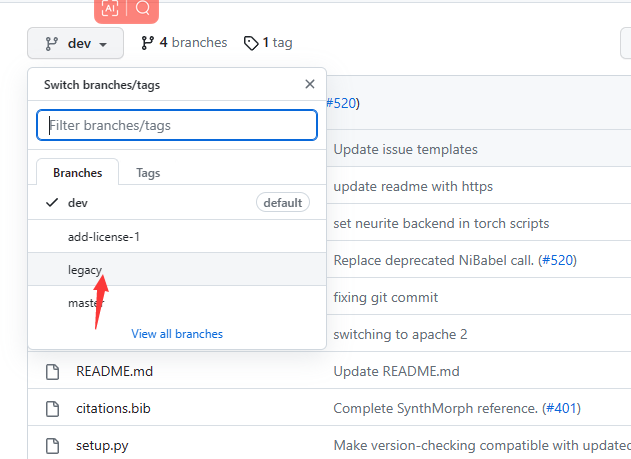
如果不习惯用命令,可以在PyCharm中进行操作,比较方便。
配置环境
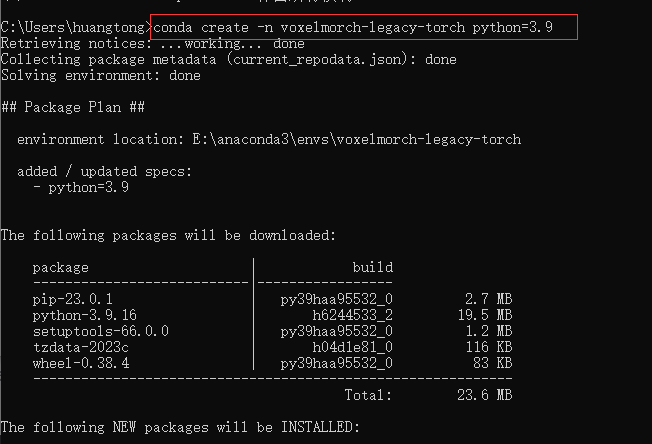
创建虚拟环境
# 我这python使用的是3.9
conda create -n voxelmorch-legacy-torch python=3.9
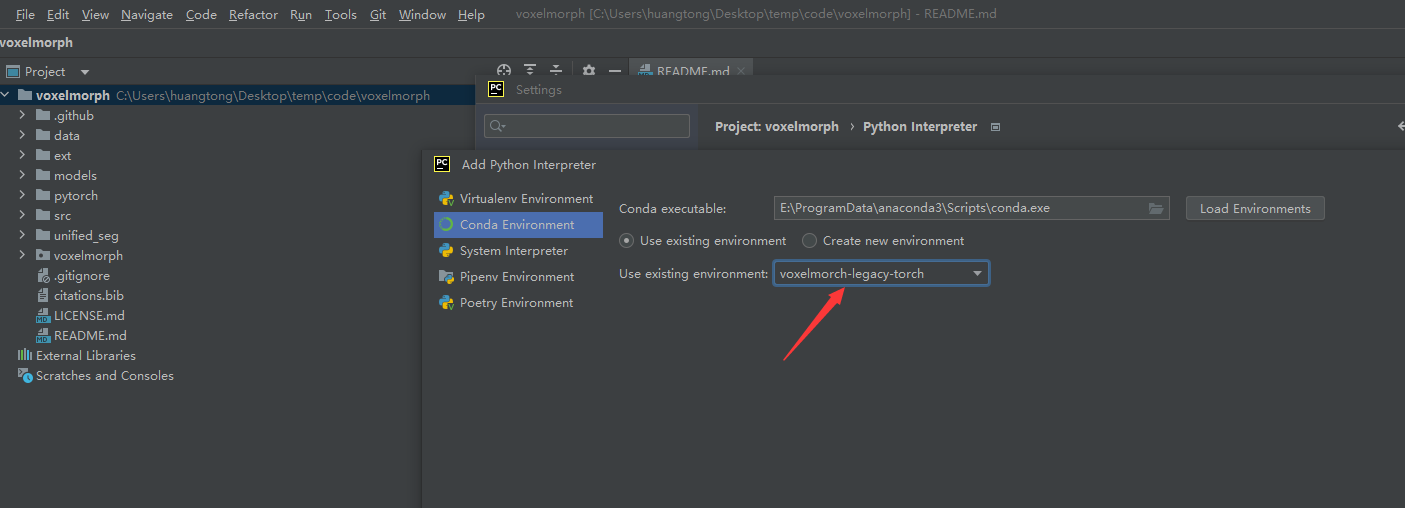
配置代码环境
使用pycharm打开项目,给项目配置 之前创建的虚拟环境
安装pytorch
在控制台 激活创建好的 虚拟环境
conda activate voxelmorch-legacy-torch
# 我的cuda版本是11.7 具体可以查看官网
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
这个torch有2个多G

安装项目依赖
# 直接安装
pip install scipy SimpleITK nibabel==3.0.0 numpy==1.23.5 tensorboardX
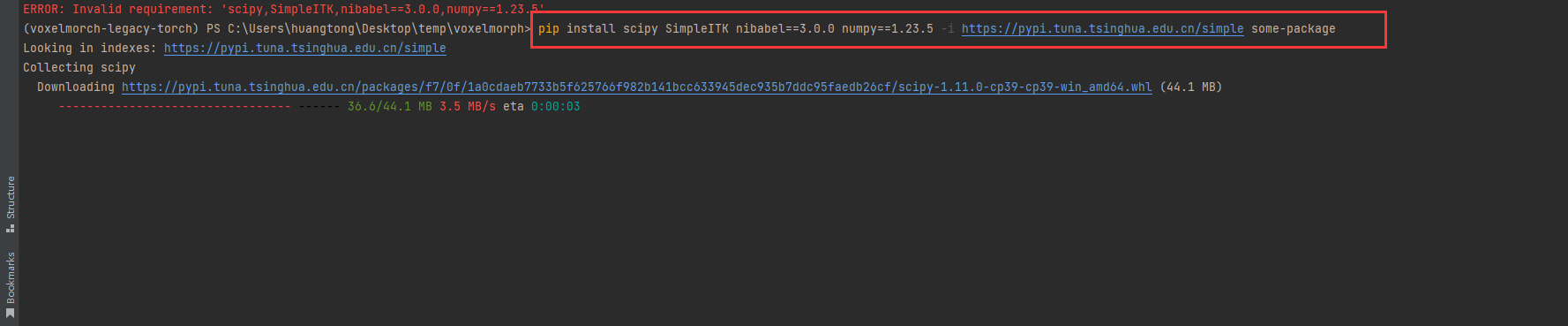
# 使用清华源镜像安装 下载速度快
pip install scipy SimpleITK nibabel==3.0.0 numpy==1.23.5 tensorboardX -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
使用清华源地址 下载 截图
数据集
数据集使用的是 Neurite OASIS Sample Data
该数据集中aligned_norm.nii.gz文件已经预处理好了,详情可以见官网地址。
我使用的是aligned_norm.nii.gz文件作为训练和测试文件,效果挺好。
官方地址:https://github.com/adalca/medical-datasets/blob/master/neurite-oasis.md
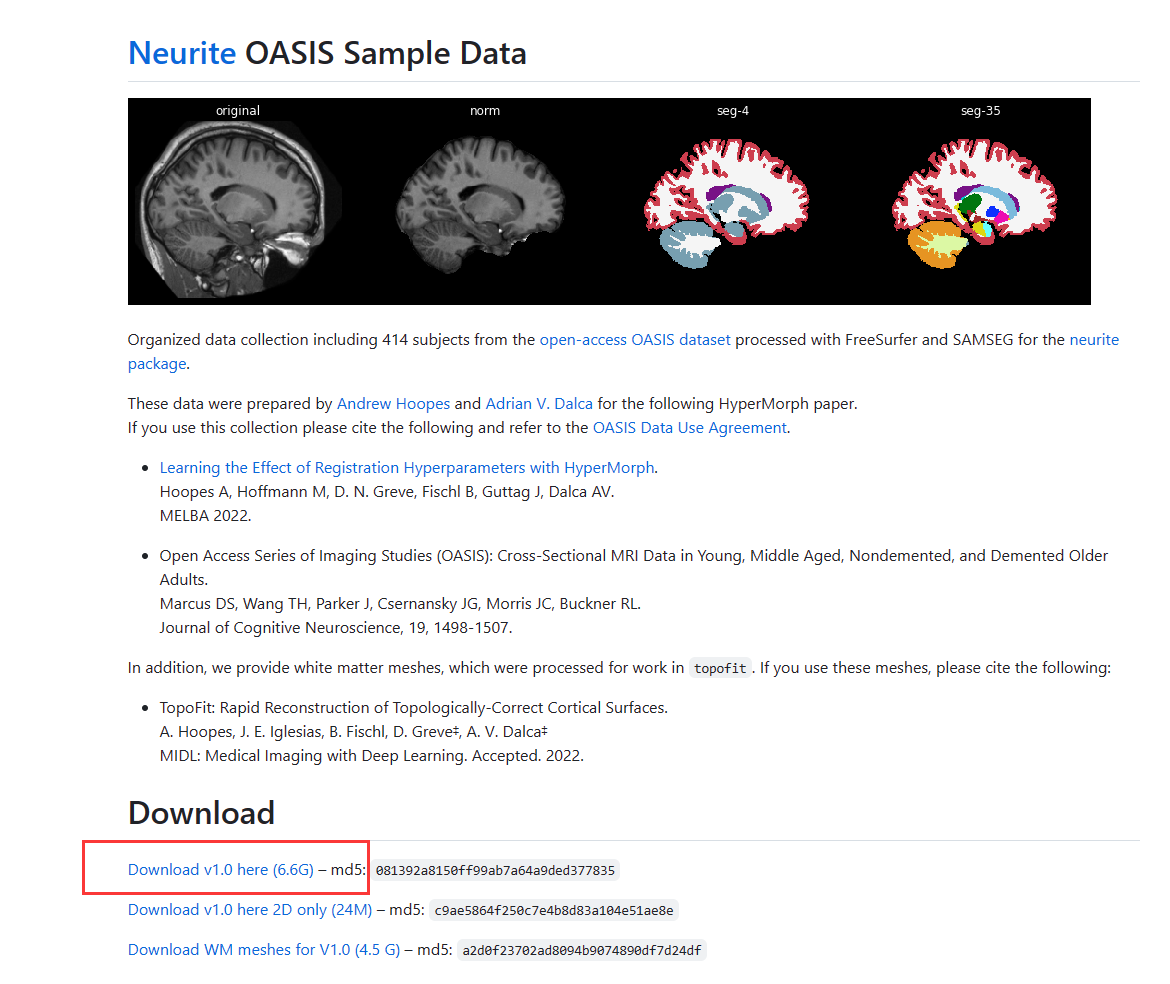
下载并且解压(根据实际情况存放,我这放在D盘)
修改测试代码
修改测试的代码,以便于测试自己的测试集。
我下载的数据集路径是D:/code/cv/datasets/original/neurite-oasis.v1.0 ,实际上要改成自己电脑上的路径。
修改后的代码
"""
*Preliminary* pytorch implementation.
VoxelMorph testing
"""
# python imports
import os
import glob
from argparse import ArgumentParser
import numpy as np
import torch
from model import cvpr2018_net, SpatialTransformer
import datagenerators
# 需要计算的标签类别
good_labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29, 30, 31, 32, 33, 34, 35]
# 计算dice的函数
def dice(vol1, vol2, labels=None, nargout=1):
if labels is None:
labels = np.unique(np.concatenate((vol1, vol2)))
labels = np.delete(labels, np.where(labels == 0)) # remove background
dicem = np.zeros(len(labels))
for idx, lab in enumerate(labels):
vol1l = vol1 == lab
vol2l = vol2 == lab
top = 2 * np.sum(np.logical_and(vol1l, vol2l))
bottom = np.sum(vol1l) + np.sum(vol2l)
bottom = np.maximum(bottom, np.finfo(float).eps) # add epsilon.
dicem[idx] = top / bottom
if nargout == 1:
return dicem
else:
return (dicem, labels)
def test(gpu,
atlas_file,
atlas_label,
test_dir,
label_dir,
model,
init_model_file):
"""
参数
gpu: 指定使用的gpu 默认为 0
atlas_file: 固定图像文件
atlas_label: 固定图像的标签 文件
test_dir: 测试文件路径
label_dir: 测试文件的标签路径
model:vm1或者vm2 默认 vm2
init_model_file:加载的模型文件
"""
os.environ["CUDA_VISIBLE_DEVICES"] = gpu
device = "cuda"
# 加载固定图像
atlas_vol = datagenerators.load_volfile(atlas_file)
input_fixed = torch.from_numpy(atlas_vol).to(device).float()[np.newaxis, np.newaxis, ...]
# 固定图像对应的label
fixed_label = datagenerators.load_volfile(atlas_label)
vol_size = atlas_vol.shape
# 测试文件 选择260到265为测试文件
test_file_lst = sorted(glob.glob(test_dir + '/OASIS_OAS1_*_MR1/aligned_norm.nii.gz'))[260:265]
# Prepare the vm1 or vm2 model and send to device
nf_enc = [16, 32, 32, 32]
if model == "vm1":
nf_dec = [32, 32, 32, 32, 8, 8]
elif model == "vm2":
nf_dec = [32, 32, 32, 32, 32, 16, 16]
# 加载模型
model = cvpr2018_net(vol_size, nf_enc, nf_dec)
model.to(device)
model.load_state_dict(torch.load(init_model_file, map_location=lambda storage, loc: storage))
# Use this to warp segments
trf = SpatialTransformer(atlas_vol.shape, mode='nearest')
trf.to(device)
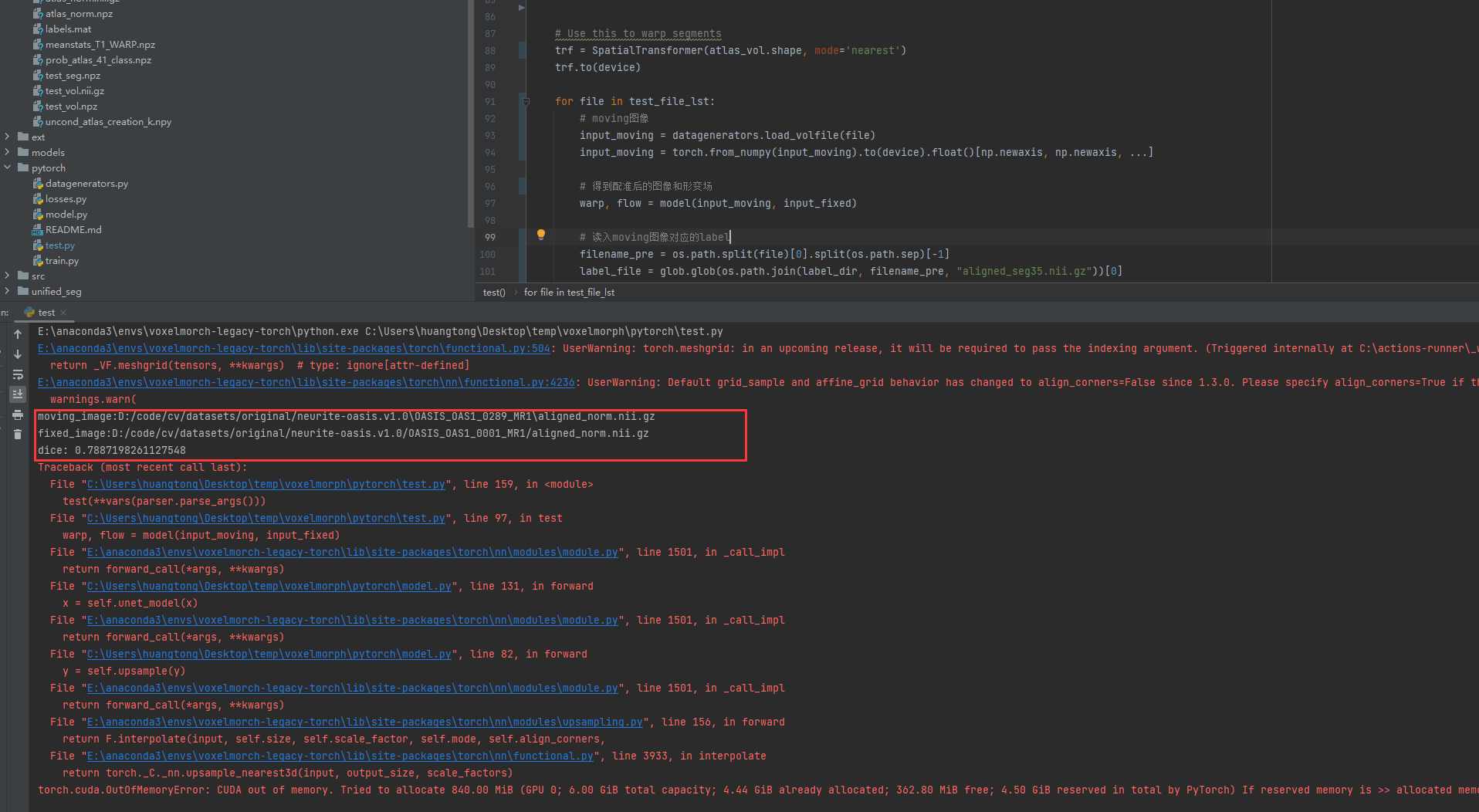
for file in test_file_lst:
# moving图像
input_moving = datagenerators.load_volfile(file)
input_moving = torch.from_numpy(input_moving).to(device).float()[np.newaxis, np.newaxis, ...]
# 得到配准后的图像和形变场
warp, flow = model(input_moving, input_fixed)
# 读入moving图像对应的label
filename_pre = os.path.split(file)[0].split(os.path.sep)[-1]
label_file = glob.glob(os.path.join(label_dir, filename_pre, "aligned_seg35.nii.gz"))[0]
moving_seg = datagenerators.load_volfile(label_file)
moving_seg = torch.from_numpy(moving_seg).to(device).float()[np.newaxis, np.newaxis, ...]
warp_seg = trf(moving_seg, flow).detach().cpu().numpy()
# 计算dice
vals, labels = dice(warp_seg, fixed_label, labels=good_labels, nargout=2)
#dice_vals[:, k] = vals
#print(np.mean(dice_vals[:, k]))
print("moving_image:"+file)
print("fixed_image:"+atlas_file)
print("dice:",np.mean(vals))
#return
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("--gpu",
type=str,
default='0',
help="gpu id")
parser.add_argument("--atlas_file",
type=str,
dest="atlas_file",
default='D:/code/cv/datasets/original/neurite-oasis.v1.0/OASIS_OAS1_0001_MR1/aligned_norm.nii.gz',
help="gpu id number")
parser.add_argument("--atlas_label",
type=str,
dest="atlas_label",
default='D:/code/cv/datasets/original/neurite-oasis.v1.0/OASIS_OAS1_0001_MR1/aligned_seg35.nii.gz',
help="gpu id number")
parser.add_argument("--model",
type=str,
dest="model",
choices=['vm1', 'vm2'],
default='vm2',
help="voxelmorph 1 or 2")
parser.add_argument("--init_model_file",
type=str,
default="../models/cvpr2018_vm2_l2_pytorch.ckpt",
dest="init_model_file",
help="model weight file")
parser.add_argument("--test_dir",
type=str,
dest="test_dir",
default="D:/code/cv/datasets/original/neurite-oasis.v1.0",
help="test data directory")
parser.add_argument("--label_dir",
type=str,
dest="label_dir",
default="D:/code/cv/datasets/original/neurite-oasis.v1.0",
help="label data directory")
test(**vars(parser.parse_args()))
测试运行
参数都写了默认参数,直接运行test.py就可以了。模型使用的官网预训练好的。
运行可以看到第一个dice值为 0.7887198261127548 。效果还是不错的
由于我的显存只有6个G,运行到第一个就显存不足了。后面就看不到了。
修改训练代码
训练的代码改动不是很大。详情可以仔细看看代码。
"""
*Preliminary* pytorch implementation.
VoxelMorph training.
"""
# python imports
import os
import glob
import random
import warnings
from argparse import ArgumentParser
# external imports
import numpy as np
import torch
from torch.optim import Adam
# internal imports
from model import cvpr2018_net
import datagenerators
import losses
def train(gpu,
data_dir,
atlas_file,
lr,
n_iter,
data_loss,
model,
reg_param,
batch_size,
n_save_iter,
model_dir):
"""
model training function
:param gpu: integer specifying the gpu to use
:param data_dir: folder with npz files for each subject.
:param atlas_file: atlas filename. So far we support npz file with a 'vol' variable
:param lr: learning rate
:param n_iter: number of training iterations
:param data_loss: data_loss: 'mse' or 'ncc
:param model: either vm1 or vm2 (based on CVPR 2018 paper)
:param reg_param: the smoothness/reconstruction tradeoff parameter (lambda in CVPR paper)
:param batch_size: Optional, default of 1. can be larger, depends on GPU memory and volume size
:param n_save_iter: Optional, default of 500. Determines how many epochs before saving model version.
:param model_dir: the model directory to save to
"""
os.environ["CUDA_VISIBLE_DEVICES"] = gpu
device = "cuda"
# Produce the loaded atlas with dims.:160x192x224.
atlas_vol = datagenerators.load_volfile(atlas_file)
vol_size = atlas_vol.shape
# Get all the names of the training data
# 训练文件使用1到255的文件 第0个文件已经作为固定图像(参数中的atlas_file)
train_vol_names = sorted(glob.glob(data_dir + '/OASIS_OAS1_*_MR1/aligned_norm.nii.gz'))[1:255]
# random.shuffle(train_vol_names)
# Prepare the vm1 or vm2 model and send to device
nf_enc = [16, 32, 32, 32]
if model == "vm1":
nf_dec = [32, 32, 32, 32, 8, 8]
elif model == "vm2":
nf_dec = [32, 32, 32, 32, 32, 16, 16]
else:
raise ValueError("Not yet implemented!")
model = cvpr2018_net(vol_size, nf_enc, nf_dec)
model.to(device)
# Set optimizer and losses
opt = Adam(model.parameters(), lr=lr)
sim_loss_fn = losses.ncc_loss if data_loss == "ncc" else losses.mse_loss
grad_loss_fn = losses.gradient_loss
# data generator
train_example_gen = datagenerators.example_gen(train_vol_names, batch_size)
# set up atlas tensor
input_fixed = torch.from_numpy(atlas_vol).to(device).float()[np.newaxis, np.newaxis, ...,]
# Training loop.
for i in range(n_iter):
# Save model checkpoint
if i % n_save_iter == 0:
if not os.path.exists(model_dir):
os.makedirs(model_dir)
save_file_name = os.path.join(model_dir, '%d.ckpt' % i)
torch.save(model.state_dict(), save_file_name)
# Generate the moving images and convert them to tensors.
moving_image = next(train_example_gen)[0]
input_moving = torch.from_numpy(moving_image).to(device).float()
input_moving = input_moving.permute(0, 4, 1, 2, 3)
# Run the data through the model to produce warp and flow field
warp, flow = model(input_moving, input_fixed)
# Calculate loss
recon_loss = sim_loss_fn(warp, input_fixed)
grad_loss = grad_loss_fn(flow)
loss = recon_loss + reg_param * grad_loss
print("%d,%f,%f,%f" % (i, loss.item(), recon_loss.item(), grad_loss.item()), flush=True)
# Backwards and optimize
opt.zero_grad()
loss.backward()
opt.step()
if __name__ == "__main__":
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category=DeprecationWarning)
parser = ArgumentParser()
parser.add_argument("--gpu",
type=str,
default='0',
help="gpu id")
parser.add_argument("--data_dir",
type=str,
default='D:/code/cv/datasets/original/neurite-oasis.v1.0',
help="data folder with training vols")
parser.add_argument("--atlas_file",
type=str,
dest="atlas_file",
default='D:/code/cv/datasets/original/neurite-oasis.v1.0/OASIS_OAS1_0001_MR1/aligned_norm.nii.gz',
help="gpu id number")
parser.add_argument("--lr",
type=float,
dest="lr",
default=1e-4,
help="learning rate")
parser.add_argument("--n_iter",
type=int,
dest="n_iter",
default=150000,
help="number of iterations")
parser.add_argument("--data_loss",
type=str,
dest="data_loss",
default='ncc',
help="data_loss: mse of ncc")
parser.add_argument("--model",
type=str,
dest="model",
choices=['vm1', 'vm2'],
default='vm2',
help="voxelmorph 1 or 2")
parser.add_argument("--lambda",
type=float,
dest="reg_param",
default=0.01, # recommend 1.0 for ncc, 0.01 for mse
help="regularization parameter")
parser.add_argument("--batch_size",
type=int,
dest="batch_size",
default=1,
help="batch_size")
parser.add_argument("--n_save_iter",
type=int,
dest="n_save_iter",
default=500,
help="frequency of model saves")
parser.add_argument("--model_dir",
type=str,
dest="model_dir",
default='./models/',
help="models folder")
train(**vars(parser.parse_args()))
训练运行
运行成功
完整代码
我对整个项目结构进行了调整,精简了代码。有需要的可以看看。
代码我已上传至github:
htwin/voxelmorph_torch: voxelmorch pythorch 精简版本 (github.com)
















 6421
6421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











