







数据简介
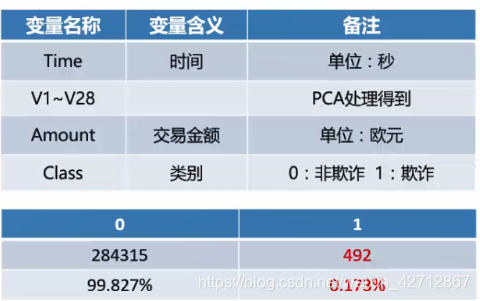
本次数据为欧洲的信用卡的持卡人在2013年9月某两天的交易数据,由于涉及到数据的敏感性问题其中V1~V28的变量都是进行了主成分分析后合成的脱敏的数据。
变量名称介绍
数据预处理
导入数据及数据初步展示
data <- read.csv("creditcard.csv")
head(data)
#导入数据还可以使用reader包中的read_csv()函数,它可以显示导入数据的进度。
library(readr)
data <- read_csv("creditcard.csv")
#把数据转换为数据框格式
data <- as.data.frame(data)
> #查看数据的基本结构和类型
> str(data)
Classes ‘spec_tbl_df’, ‘tbl_df’, ‘tbl’ and 'data.frame': 284807 obs. of 31 variables:
$ Time : num 0 0 1 1 2 2 4 7 7 9 ...
$ V1 : num -1.36 1.192 -1.358 -0.966 -1.158 ...
$ V2 : num -0.0728 0.2662 -1.3402 -0.1852 0.8777 ...
$ V3 : num 2.536 0.166 1.773 1.793 1.549 ...
$ V4 : num 1.378 0.448 0.38 -0.863 0.403 ...
$ V5 : num -0.3383 0.06 -0.5032 -0.0103 -0.4072 ...
$ V6 : num 0.4624 -0.0824 1.8005 1.2472 0.0959 ...
$ V7 : num 0.2396 -0.0788 0.7915 0.2376 0.5929 ...
$ V8 : num 0.0987 0.0851 0.2477 0.3774 -0.2705 ...
$ V9 : num 0.364 -0.255 -1.515 -1.387 0.818 ...
$ V10 : num 0.0908 -0.167 0.2076 -0.055 0.7531 ...
$ V11 : num -0.552 1.613 0.625 -0.226 -0.823 ...
$ V12 : num -0.6178 1.0652 0.0661 0.1782 0.5382 ...
$ V13 : num -0.991 0.489 0.717 0.508 1.346 ...
$ V14 : num -0.311 -0.144 -0.166 -0.288 -1.12 ...
$ V15 : num 1.468 0.636 2.346 -0.631 0.175 ...
$ V16 : num -0.47 0.464 -2.89 -1.06 -0.451 ...
$ V17 : num 0.208 -0.115 1.11 -0.684 -0.237 ...
$ V18 : num 0.0258 -0.1834 -0.1214 1.9658 -0.0382 ...
$ V19 : num 0.404 -0.146 -2.262 -1.233 0.803 ...
$ V20 : num 0.2514 -0.0691 0.525 -0.208 0.4085 ...
$ V21 : num -0.01831 -0.22578 0.248 -0.1083 -0.00943 ...
$ V22 : num 0.27784 -0.63867 0.77168 0.00527 0.79828 ...
$ V23 : num -0.11 0.101 0.909 -0.19 -0.137 ...
$ V24 : num 0.0669 -0.3398 -0.6893 -1.1756 0.1413 ...
$ V25 : num 0.129 0.167 -0.328 0.647 -0.206 ...
$ V26 : num -0.189 0.126 -0.139 -0.222 0.502 ...
$ V27 : num 0.13356 -0.00898 -0.05535 0.06272 0.21942 ...
$ V28 : num -0.0211 0.0147 -0.0598 0.0615 0.2152 ...
$ Amount: num 149.62 2.69 378.66 123.5 69.99 ...
$ Class : num 0 0 0 0 0 0 0 0 0 0 ...
- attr(*, "spec")=
.. cols(
.. Time = col_double(),
.. V1 = col_double(),
.. V2 = col_double(),
.. V3 = col_double(),
.. V4 = col_double(),
.. V5 = col_double(),
.. V6 = col_double(),
.. V7 = col_double(),
.. V8 = col_double(),
.. V9 = col_double(),
.. V10 = col_double(),
.. V11 = col_double(),
.. V12 = col_double(),
.. V13 = col_double(),
.. V14 = col_double(),
.. V15 = col_double(),
.. V16 = col_double(),
.. V17 = col_double(),
.. V18 = col_double(),
.. V19 = col_double(),
.. V20 = col_double(),
.. V21 = col_double(),
.. V22 = col_double(),
.. V23 = col_double(),
.. V24 = col_double(),
.. V25 = col_double(),
.. V26 = col_double(),
.. V27 = col_double(),
.. V28 = col_double(),
.. Amount = col_double(),
.. Class = col_double()
.. )
> summary(data)
Time V1 V2 V3 V4 V5 V6
Min. : 0 Min. :-56.40751 Min. :-72.71573 Min. :-48.3256 Min. :-5.68317 Min. :-113.74331 Min. :-26.1605
1st Qu.: 54202 1st Qu.: -0.92037 1st Qu.: -0.59855 1st Qu.: -0.8904 1st Qu.:-0.84864 1st Qu.: -0.69160 1st Qu.: -0.7683
Median : 84692 Median : 0.01811 Median : 0.06549 Median : 0.1799 Median :-0.01985 Median : -0.05434 Median : -0.2742
Mean : 94814 Mean : 0.00000 Mean : 0.00000 Mean : 0.0000 Mean : 0.00000 Mean : 0.00000 Mean : 0.0000
3rd Qu.:139321 3rd Qu.: 1.31564 3rd Qu.: 0.80372 3rd Qu.: 1.0272 3rd Qu.: 0.74334 3rd Qu.: 0.61193 3rd Qu.: 0.3986
Max. :172792 Max. : 2.45493 Max. : 22.05773 Max. : 9.3826 Max. :16.87534 Max. : 34.80167 Max. : 73.3016
V7 V8 V9 V10 V11 V12 V13
Min. :-43.5572 Min. :-73.21672 Min. :-13.43407 Min. :-24.58826 Min. :-4.79747 Min. :-18.6837 Min. :-5.79188
1st Qu.: -0.5541 1st Qu.: -0.20863 1st Qu.: -0.64310 1st Qu.: -0.53543 1st Qu.:-0.76249 1st Qu.: -0.4056 1st Qu.:-0.64854
Median : 0.0401 Median : 0.02236 Median : -0.05143 Median : -0.09292 Median :-0.03276 Median : 0.1400 Median :-0.01357
Mean : 0.0000 Mean : 0.00000 Mean : 0.00000 Mean : 0.00000 Mean : 0.00000 Mean : 0.0000 Mean : 0.00000
3rd Qu.: 0.5704 3rd Qu.: 0.32735 3rd Qu.: 0.59714 3rd Qu.: 0.45392 3rd Qu.: 0.73959 3rd Qu.: 0.6182 3rd Qu.: 0.66251
Max. :120.5895 Max. : 20.00721 Max. : 15.59500 Max. : 23.74514 Max. :12.01891 Max. : 7.8484 Max. : 7.12688
V14 V15 V16 V17 V18 V19 V20
Min. :-19.2143 Min. :-4.49894 Min. :-14.12985 Min. :-25.16280 Min. :-9.498746 Min. :-7.213527 Min. :-54.49772
1st Qu.: -0.4256 1st Qu.:-0.58288 1st Qu.: -0.46804 1st Qu.: -0.48375 1st Qu.:-0.498850 1st Qu.:-0.456299 1st Qu.: -0.21172
Median : 0.0506 Median : 0.04807 Median : 0.06641 Median : -0.06568 Median :-0.003636 Median : 0.003735 Median : -0.06248
Mean : 0.0000 Mean : 0.00000 Mean : 0.00000 Mean : 0.00000 Mean : 0.000000 Mean : 0.000000 Mean : 0.00000
3rd Qu.: 0.4931 3rd Qu.: 0.64882 3rd Qu.: 0.52330 3rd Qu.: 0.39968 3rd Qu.: 0.500807 3rd Qu.: 0.458949 3rd Qu.: 0.13304
Max. : 10.5268 Max. : 8.87774 Max. : 17.31511 Max. : 9.25353 Max. : 5.041069 Max. : 5.591971 Max. : 39.42090
V21 V22 V23 V24 V25 V26
Min. :-34.83038 Min. :-10.933144 Min. :-44.80774 Min. :-2.83663 Min. :-10.29540 Min. :-2.60455
1st Qu.: -0.22839 1st Qu.: -0.542350 1st Qu.: -0.16185 1st Qu.:-0.35459 1st Qu.: -0.31715 1st Qu.:-0.32698
Median : -0.02945 Median : 0.006782 Median : -0.01119 Median : 0.04098 Median : 0.01659 Median :-0.05214
Mean : 0.00000 Mean : 0.000000 Mean : 0.00000 Mean : 0.00000 Mean : 0.00000 Mean : 0.00000
3rd Qu.: 0.18638 3rd Qu.: 0.528554 3rd Qu.: 0.14764 3rd Qu.: 0.43953 3rd Qu.: 0.35072 3rd Qu.: 0.24095
Max. : 27.20284 Max. : 10.503090 Max. : 22.52841 Max. : 4.58455 Max. : 7.51959 Max. : 3.51735
V27 V28 Amount Class
Min. :-22.565679 Min. :-15.43008 Min. : 0.00 Min. :0.000000
1st Qu.: -0.070840 1st Qu.: -0.05296 1st Qu.: 5.60 1st Qu.:0.000000
Median : 0.001342 Median : 0.01124 Median : 22.00 Median :0.000000
Mean : 0.000000 Mean : 0.00000 Mean : 88.35 Mean :0.001728
3rd Qu.: 0.091045 3rd Qu.: 0.07828 3rd Qu.: 77.17 3rd Qu.:0.000000
Max. : 31.612198 Max. : 33.84781 Max. :25691.16 Max. :1.000000
> #查看样本类别比例
> table(data$Class)
0 1
284315 492
> prop.table(table(data$Class))
0 1
0.998272514 0.001727486
缺失值识别
#可视化展示缺失值情况
> #使用VIM包中的aggr函数画出缺失值的图
> library(VIM)
> aggr(data,prop=F,number=T)
> sum(!complete.cases(data))
[1] 0

从缺失值图形及缺失值计算结果看均为没有缺失值所以不需要处理。
分层抽样
处理类别不平衡问题
由于数据中类别为诈骗数据和非诈骗数据的样本数差距过大,会影响建模的准确性。
所以我们从类别为诈骗的样本数据中抽取和非诈骗数据的样本数一样的样本,然后合并在一起组成一个新的样本。
这样在新的样本中诈骗数据和非诈骗数据就一致了。这样就解决了类别不平衡的问题了。
#把时间这一列转换为小时
data$Time_Hour <- round(data$Time/3600,0)
#把class列转换为因子型
data$Class <- as.factor(data$Class)
#筛选出类别为诈骗的样本
data_1 <- data[data$Class==1,]
#筛选出类别为非诈骗的样本
data_0 <- data[data$Class==0,]
##随机抽样与诈骗样本个数相同的非诈骗样本,然后合并成新数据
#设定随机种子
set.seed(1234)
#从非诈骗数据中抽取与诈骗数据个数相同的非诈骗样本
index <- sample(1:length(rownames(data_0)),length(row.names(data_1)))
#合并成新数据
data_0_new <- data_0[index,]
data_end <- rbind(data_1,data_0_new)
#剔除Time 列,用Time_hour列代替,并且把Time_hour列放在第一列
data_end <- data.frame(data_end$Time_Hour,data_end[,2:31])
#变量的重命名
library(plyr)
data_end <- rename(data_end,c("data_end.Time_Hour"="Time_Hour"))
> #按照类别进行分层抽样,建立训练集和测试集
> set.seed(1234)
> index2 <- sample(1:nrow(data_end),0.8*nrow(data_end))
> train <- data_end[index2,]
> test <- data_end[-index2,]
> table(train$Class)
0 1
397 390
> table(test$Class)
0 1
95 102
数据的标准化
#使用函数scale进行数据的标准化
#scale的原理为每一列数据减去此列的平均值然后再除去标准差
#如果是只是减去列的平均值的话就是数据的中心话
#对data_end数据进行标准化处理
data_s <- data_end
data_s[,1:30] <- scale(data_s[,1:30])
#对train数据进行标准化处理
train2 <- train
train2[,1:30] <- scale(train2[,1:30])
#对test数据进行标准化处理
test2 <- test
test2[,1:30] <- scale(test2[,1:30])
描述性分析
绘制不同时间诈骗次数的条形图
library(ggplot2)
#把Time_Hour列转换为因子
data_1$Time_Hour <- as.factor(data_1$Time_Hour)
ggplot(data_1,aes(Time_Hour,fill=Time_Hour)) +
geom_bar()+
theme_minimal()+
theme(legend.position="none")

从图中可以发现诈骗最多的时候大多集中在凌晨的2点和上午的11点左右
绘制不同时间诈骗金额的箱线图
#绘制不同时间诈骗金额的箱线图
ggplot(data_1,aes(Time_Hour,Amount,fill=Time_Hour))+
geom_boxplot()+
theme_minimal()+
theme(legend.position = "none")

整体而言诈骗金额平均为125左右,但是诈骗金额波动性比较大,最大的有2000多。
绘制不同时间诈骗金额的条形图
#绘制不同时间诈骗金额的条形图
Time_Amount <- aggregate(data_1$Amount,by=list(Time = data_1$Time_Hour),mean)
ggplot(Time_Amount,aes(Time,x,fill=Time))+
geom_bar(stat = "identity")+
theme_minimal()+
theme(legend.position="none")

平均诈骗金额最高的是在第二天的12点,整体而言平均诈骗金额分布在125左右。
自动参数调整
使用caret包进行自动参数调整
参数调整是提升模型性能的一个重要过程,大多数机器学习算法都至少调整一个参数,而大多数复杂的模型都可以调整多个参数值来调整模型从而进行更好的拟合。
例如,寻找更适合的K值来调整K近邻模型,调节隐层层数和隐藏层的节点数等优化神经网络模型,支持向量机模型中调整核函数,“软边界”惩罚大小等进行优化。
虽然这可以让模型更适合数据,但是尝试所有可能的选项会非常复杂,所以需要一种更系统的方式。
使用iris数据介绍caret包中的自动调整参数的功能
> #自动参数调整
> #使用caret包进行自动参数调整
> #举例
> #使用决策树模型对iris数据进行建模,
> #使用caret包中的train函数进行建模并进行自动参数调整
>
> library(caret)
> set.seed(1234)
> m_C50 <- train(Species~., data=iris,method='C5.0')
There were 40 warnings (use warnings() to see them)
> m_C50
C5.0
150 samples
4 predictor
3 classes: 'setosa', 'versicolor', 'virginica'
No pre-processing
Resampling: Bootstrapped (25 reps)
Summary of sample sizes: 150, 150, 150, 150, 150, 150, ...
Resampling results across tuning parameters:
model winnow trials Accuracy Kappa
rules FALSE 1 0.9353579 0.9019696
rules FALSE 10 0.9370844 0.9045424
rules FALSE 20 0.9325835 0.8976068
rules TRUE 1 0.9382311 0.9062975
rules TRUE 10 0.9407392 0.9099910
rules TRUE 20 0.9385430 0.9066136
tree FALSE 1 0.9347127 0.9009924
tree FALSE 10 0.9369888 0.9044013
tree FALSE 20 0.9332286 0.8985820
tree TRUE 1 0.9375860 0.9053246
tree TRUE 10 0.9399845 0.9088007
tree TRUE 20 0.9392443 0.9076915
Accuracy was used to select the optimal model using the
largest value.
The final values used for the model were trials = 10, model =
rules and winnow = TRUE.
结果中包含候选模型的评估列表,可以发现共建立并测试了12个模型,基于3个C5.0调整参数的组合:model, trials和winnow。每个候选模型都给出了模型精度和Kappa统计量,最下方还展示了最佳后选模型所对应的参数值。
Kappa用来统计衡量模型的稳定性
很差的一致性: <0.2
尚可的一致性: 0.2~0.4
中等的一致性: 0.4~0.6
不错的一致性: 0.6~0.8
很好的饿一致性:0.8~1
定制调参数
定制调参需要时通过设置train中trControl及trGrid两个参数进行定制的。而设置这两个参数需要分别用到trainControl函数及expand.grid函数进行设置,参数trControl主要用来设置重抽样的方法例如设置使用五折交叉验证的方法,trGrid是用来指定可以调整哪些参数及调整的范围。
#定制调整参数
> #trainControl这个函数是为了设置train函数重采样的方式,例如这里就是使用五折交叉验证的方法
> trControl <- trainControl(method = 'cv',number = 5,selectionFunction = 'oneSE')
> #expand.grid是用来设置需要调整的参数及调整的范围,结果用在train函数中
> grid <- expand.grid(.model='tree',
+ .trials = c(1,3,5),
+ .winnow='FALSE')
> set.seed(1234)
>
> m_C502 <- train(Species~., data=iris, method="C5.0",
+ trControl=trControl,
+ tuneGrid=grid)
Warning message:
In Ops.factor(x$winnow) : ‘!’ not meaningful for factors
> m_C502
C5.0
150 samples
4 predictor
3 classes: 'setosa', 'versicolor', 'virginica'
No pre-processing
Resampling: Cross-Validated (5 fold)
Summary of sample sizes: 120, 120, 120, 120, 120
Resampling results across tuning parameters:
trials Accuracy Kappa
1 0.9266667 0.89
3 0.9333333 0.90
5 0.9333333 0.90
Tuning parameter 'model' was held constant at a value of tree
Tuning parameter 'winnow' was held constant at a value of FALSE
Accuracy was used to select the optimal model using the one SE rule.
The final values used for the model were trials = 1, model = tree and winnow = FALSE.
>
定制调参的过程
trainControl()函数用来创建一系列的配置选项,这些选项考虑到了诸如重抽样策略以及用于选择最佳模型的度量这些模型评价标准的管理。以上我们专注于两个主要参数:method和selectionFunction.
以上我们使用的是五折交叉验证的重抽样方法;
selectionFuncton参数可以设定一函数用来在各个候选者中选择特定的模型,共三个函数:
best函数简单地选择具有最好的某特定度量值的候选者,默认选项
oneSE函数选择最好性能标准差之内的最简单的候选者
Tolerance选择某个用户指定比例之内的最简单的候选者
train函数的介绍可以参考我的另一个文章
caret包介绍学习之train函数介绍
建模预测之随机森立
使用随机森立进行分建模并进行预测
# 建模与预测之随机森立 --------------------------------------------------------------
>
> #使用5折交叉验证的方法建立随机森林模型,并选取在最好性能标准差之内最简单的模型
> model_rf <- train(Class~.,data=train,mothed='rf', trControl=trainControl(method = 'cv',number = 5,selectionFunction = "oneSE"))
> model_rf
Random Forest
787 samples
30 predictor
2 classes: '0', '1'
No pre-processing
Resampling: Cross-Validated (5 fold)
Summary of sample sizes: 629, 630, 630, 629, 630
Resampling results across tuning parameters:
mtry Accuracy Kappa
2 0.9427961 0.8855125
16 0.9364589 0.8728728
30 0.9402725 0.8805043
Accuracy was used to select the optimal model using the one SE rule.
The final value used for the model was mtry = 2.
>
> #使用模型对test数据集进行预测
> pre <- predict(model_rf,test)
>
> #使用混淆矩阵查看预测效果
> table(pre,test$Class)
pre 0 1
0 88 13
1 7 89
>
> #查看各个变量对于模型的重要性
> plot(varImp(model_rf))
>

建模预测之KNN算法
首先介绍关于KNN算法的介绍可以参考文章:
深入浅出KNN算法(一) KNN算法原理
# 建模与预测之KNN建模 -------------------------------------------------------------
#调用knn的包class
library(class)
#knn预测
#Knn用的数据需要进行标准化,因为计算的是距离,所以需要消除量纲对距离的影响。
results=c()
for (i in 1:10) {
pred_knn <- knn(train2[-31],test2[-31],train2$Class,i)
Table <- table(pred_knn,test$Class)
acc <- sum(diag(Table))/sum(Table)
results <- c(results,acc)
}
plot(1:10,results,type="h",col="red",xlab="K值",ylab="准确率",pch=20)
text(1:10,results,labels = round(results,2),pos = 3)

> #结果显示K为3时模型准确率最高
>
> #建立模型
> #train:训练集(去除目标变量)
> #test: 测试集(去除目标变量)
> #cl:训练集的目标变量
> #k:邻居的数量
> pred_knn <- knn(train = train2[-31],test=test2[-31],
+ cl=train2$Class,k=3)
> table(pred_knn,test$Class)
pred_knn 0 1
0 91 12
1 4 90
>
模型评估
# 模型评估 --------------------------------------------------------------------
>
>
> #计算kappa值
> A <- as.matrix(table(pred_knn,test$Class))
> A
pred_knn 0 1
0 91 12
1 4 90
> x <- sum(diag(A))/sum(A)
> x
[1] 0.9187817
>
> y <- (sum(A[1,])*sum(A[,1]) + sum(A[2,])*sum(A[,2]))/(sum(A)*sum(A))
> y
[1] 0.4991883
>
> kappa <- (x-y)/(1-y)
>
>
>
>
> kappa <- function(pre,class){
+ A <- as.matrix(table(pre,class))
+
+ x <- sum(diag(A))/sum(A)
+
+
+ y <- (sum(A[1,])*sum(A[,1]) + sum(A[2,])*sum(A[,2]))/(sum(A)*sum(A))
+
+
+ k <- (x-y)/(1-y)
+ return(k)
+ }
>
> #计算准确率,查全率,及kappa值
>
> A <- as.matrix(table(pre,test$Class))
> A
pre 0 1
0 88 13
1 7 89
> P_zq <- sum(diag(A))/sum(A)
> P_zq
[1] 0.8984772
>
> p_cq <- A[2,2]/sum(A[,2])
>
> k <- kappa(pre,test$Class)
> results_rf <- c(P_zq,p_cq,k)
> names(results_rf) <- c("准确率","查全率","kappa值")
> results_rf
准确率 查全率 kappa值
0.8984772 0.8725490 0.7971373
>
> A <- as.matrix(table(pred_knn,test$Class))
> A
pred_knn 0 1
0 91 12
1 4 90
> P_zq <- sum(diag(A))/sum(A)
> P_zq
[1] 0.9187817
>
> p_cq <- A[2,2]/sum(A[,2])
>
> k <- kappa(pre,test$Class)
> results_knn <- c(P_zq,p_cq,k)
> names(results_knn) <- c("准确率","查全率","kappa值")
> results_knn
准确率 查全率 kappa值
0.9187817 0.8823529 0.7971373
>
> #从结果看knn的模型的准确率及查全率都要高一些所以knn模型的效果更好。
>















 6345
6345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









