






首先看一下LinkedList基本源码,基于jdk1.8
public class LinkedList extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable
{transient int size = 0;//指向第一个节点
transient Nodefirst;//指向最后一个节点
transient Nodelast;publicLinkedList() {
}public LinkedList(Collection extends E>c) {this();
addAll(c);
}private static class Node{
E item;
Nodenext;
Nodeprev;
Node(Node prev, E element, Nodenext) {this.item =element;this.next =next;this.prev =prev;
}
}
}
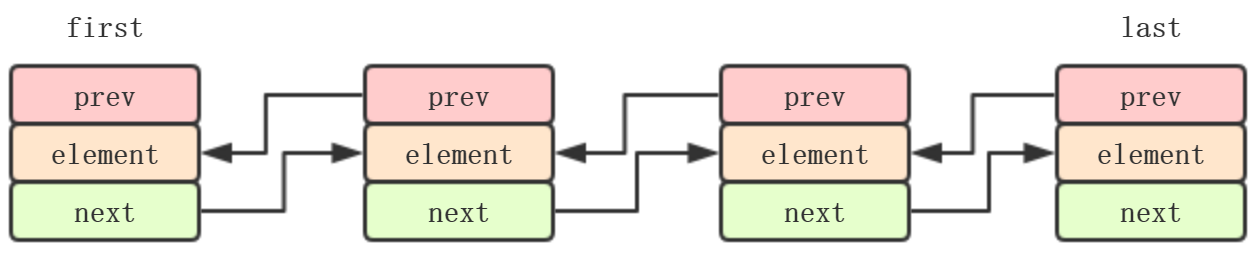
从LinkedList基本代码结构,可以看出来LinkedList本质上链表
链表一般分为:单向链表、单向循环链表、双向链表、双向循环链表
LinkedList就是一个双向链表,而且实现了Deque,也可以当做双端队列使用,使用方法比较丰富
PS:JDK1.6的LinkedList为双向循环链表,之后去掉header,通过双向链表实现
一、添加:
offer()、add()和linkLast():
public booleanadd(E e) {
linkLast(e);//添加到尾部
return true;
}voidlinkLast(E e) {final Node l = last; //最后一个节点
final Node newNode = new Node<>(l, e, null); //生成一个新节点,前置为last,数据为e,next为null
last = newNode; //将新节点赋值为last
if (l == null) //如果l为null,意味着链表为空,所以置为首节点
first =newNode;elsel.next= newNode; //否则将新节点置为l的next节点
size++;
modCount++; //修改次数modCount+1
}

addAll():
public boolean addAll(int index, Collection extends E> c) {
checkPositionIndex(index);//检查下标位置是否越界
Object[] a = c.toArray();//将Collection转换为数组
int numNew = a.length;//数组的长度numNew
if (numNew == 0)
return false;
Node pred, succ;//定义两个节点pred,succ。pred为插入集合的前一个节点,succ为插入集合的后一个节点
if (index == size) {//如果插入的位置等于size,将集合元素加到链表的尾部
succ = null;//succ赋值为null
pred = last;//pred赋值为last
} else {
succ = node(index);//succ赋值为index节点
pred = succ.prev;//succ的prev指向pred
}
for (Object o : a) {//遍历数组
@SuppressWarnings("unchecked") E e = (E) o;//元素转换为E
Node newNode = new Node<>(pred, e, null);//生成一个新节点,并且把prev指向pred
if (pred == null)//如果pred为null,newNode为首节点
first = newNode;
else
pred.next = newNode;//pred的next指向newNode
pred = newNode;//把newNode赋值为pred
}
if (succ == null) {//如果插入到尾部
last = pred;pred赋值为last,pred此时为数组中最后一个元素Node
} else {
pred.next = succ;//pred的next指向succ
succ.prev = pred;//succ的prev指向pred
}
size += numNew;//重新赋值size
modCount++;//修改次数增加一次
return true;
}
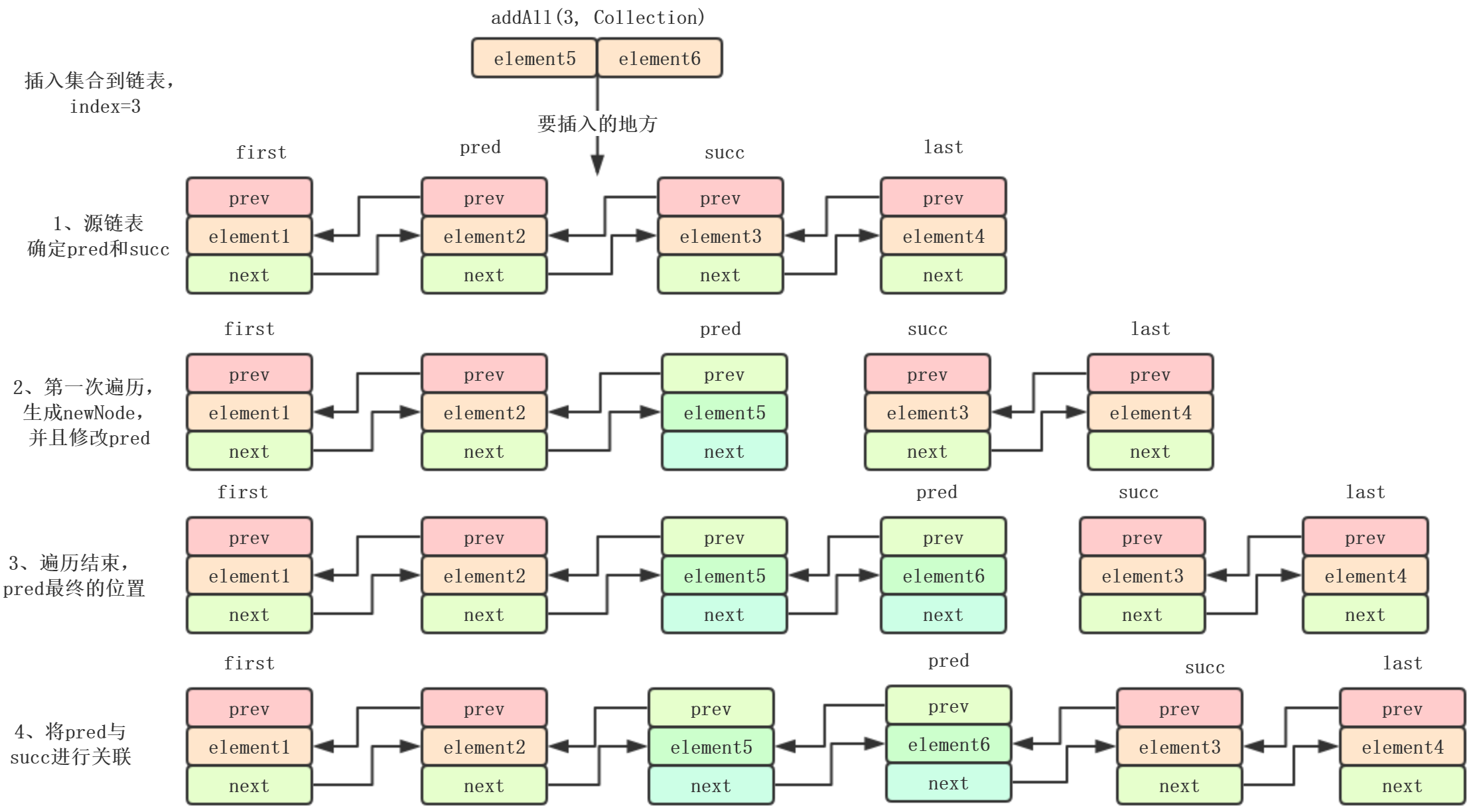
图中把每一步都表现出来了,不可能看不懂吧
PS:
把Collection转换为数组的目的:toArray()保证传进来的这个集合不会被任何地方引用,也保证这个集合不会有任何机会被修改,保证了数
据的安全性
offFirst()、offLast()、addLast()和addFirst()这里就不讲了,看了上面,这里就很容易理解
二、删除:
poll()、remove()、removeFirst()和unlinkFirst():
public E remove() {
return removeFirst();
}
public E removeFirst() {//删除first
final Node f = first;//得到first节点
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
private E unlinkFirst(Node f) {
// assert f == first && f != null;
final E element = f.item;//得到first节点的item
final Node next = f.next;//first节点的next
f.item = null;//item置为null
f.next = null; //first节点的next置为null
first = next;//将first节点的next置为首节点
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
pollLast()、removeLast()和unlinkLast():
public E removeLast() {
final Node l = last;//得到last节点
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
private E unlinkLast(Node l) {//释放last节点
// assert l == last && l != null;
final E element = l.item;
final Node prev = l.prev;
l.item = null;
l.prev = null;
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
比较简单,看下就明白了
remove(Object)和remove(index):
public boolean remove(Object o) {
if (o == null) {//如果o为null
for (Node x = first; x != null; x = x.next) {
if (x.item == null) {//遍历node直到找到第一个null的index
unlink(x);//删除index节点
return true;
}
}
} else {
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item)) {//遍历node直到找到第一个o的index
unlink(x);
return true;
}
}
}
return false;
}
E unlink(Node x) {
// assert x != null;
final E element = x.item;
final Node next = x.next;
final Node prev = x.prev;
if (prev == null) {//如果为上个节点prev等于null,直接把下个节点指向first
first = next;
} else {
prev.next = next;//prev的next赋值为下个node
x.prev = null;当前节点的上个节点置为null
}
if (next == null) {//如果删除last节点,直接把上个节点置为last节点
last = prev;
} else {
next.prev = prev;//next节点的prev指向prev节点
x.next = null;//当前节点的next置为null
}
x.item = null;//当前节点item置为null,size--
size--;
modCount++;
return element;
}
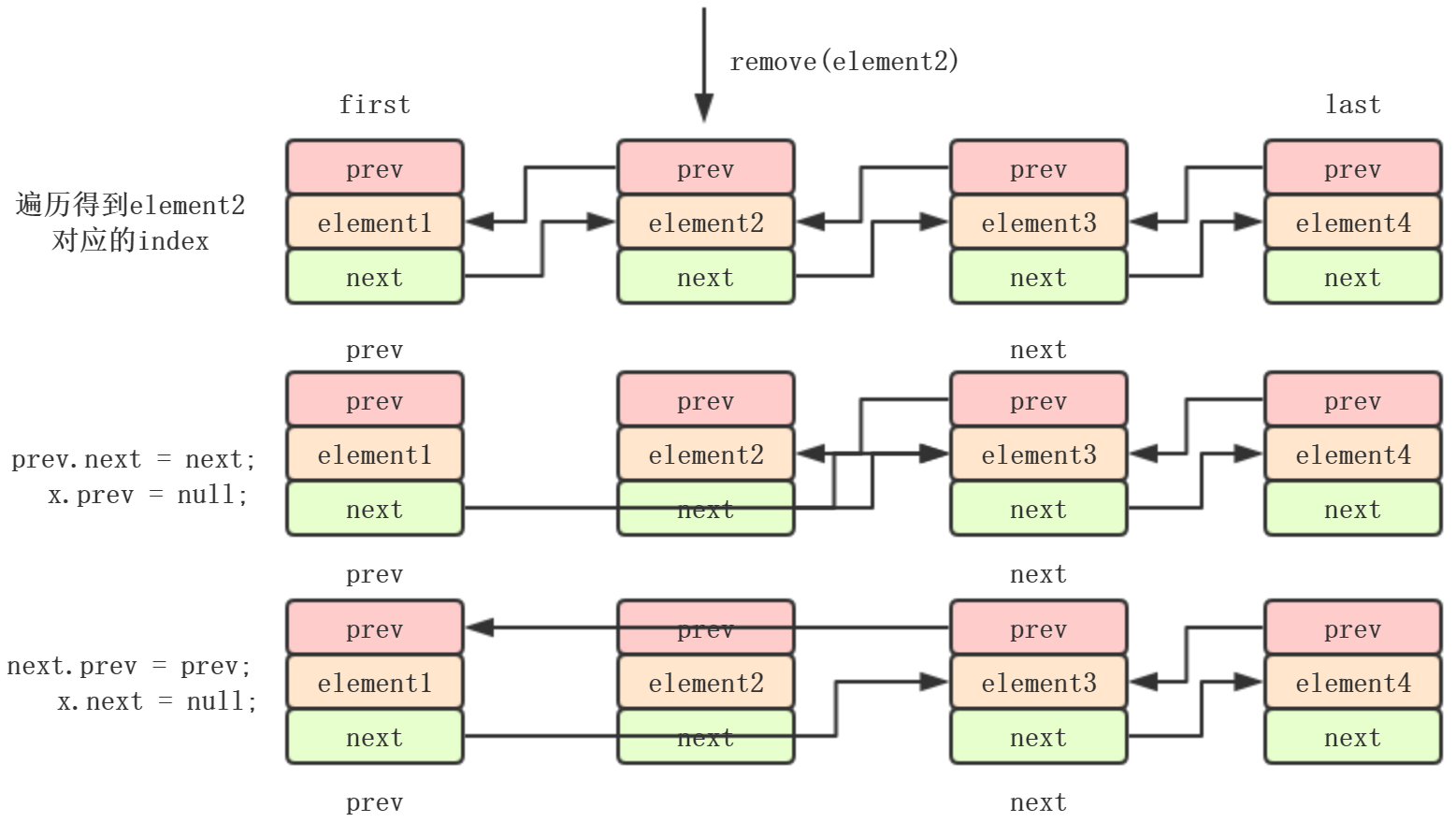
三、修改:set(index, element):
public E set(int index, E element) {
checkElementIndex(index);//检查index是否越界
Node x = node(index);//获取index对应的节点
E oldVal = x.item;//获取节点的item
x.item = element;//重新赋值节点的item
return oldVal;//返回oldVal
}
四、获取:
get(index)和node(index):
public E get(int index) {
checkElementIndex(index);//检查下标
return node(index).item;//返回index对应node的item
}
Node node(int index) {//使用二分法查找
if (index < (size >> 1)) {如果index小于size的一半
Node x = first;//获取first节点
for (int i = 0; i < index; i++)//因为链表不能随机访问,所以只能从0遍历到index,最终返回index对应的node
x = x.next;
return x;
} else {
Node x = last;//获取last节点
for (int i = size - 1; i > index; i--)//从size-1遍历到index,最终返回index对应的node
x = x.prev;
return x;
}
}
getFirst():
public E getFirst() {
final Node f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
getLast():
public E getLast() {
final Node l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
contains(Object)和indexOf(Object):
public int indexOf(Object o) {
int index = 0;
if (o == null) {//如果Object为null
for (Node x = first; x != null; x = x.next) {//遍历得到第一个null,返回index
if (x.item == null)
return index;
index++;
}
} else {
for (Node x = first; x != null; x = x.next) {//遍历得到第一个和object相等的node.item,返回index
if (o.equals(x.item))
return index;
index++;
}
}
return -1;//如果没有,返回-1
}
for循环效率:for、foreach、lambda表达式的foreach、Iterator
测试:
public static void main(String[] args) throws IOException {
LinkedList list = new LinkedList<>();
list.add("abc");
list.add("def");
for (int i = 0; i < 10000; i++) {
list.add("abc");
}
long startTime = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i) + " ");
}
System.out.println(" ");
System.out.println("普通for循环花费时间:" + (System.currentTimeMillis() - startTime));
long startTime1 = System.currentTimeMillis();
for (String s : list) {
System.out.print(s + " ");
}
System.out.println(" ");
System.out.println("foreach循环花费时间:" + (System.currentTimeMillis() - startTime1));
long startTime3 = System.currentTimeMillis();
list.forEach(s -> {
System.out.print(s + " ");
});
System.out.println(" ");
System.out.println("lambda表达式foreach循环花费时间:" + (System.currentTimeMillis() - startTime3));
long startTime2 = System.currentTimeMillis();
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
String s = (String)iterator.next();
System.out.print(s + " ");
}
System.out.println(" ");
System.out.println("Iterator循环花费时间:" + (System.currentTimeMillis() - startTime2));
}
为了结果的可信度,我们得到三次输出结果:
普通for循环花费时间:105
foreach循环花费时间:43
lambda表达式foreach循环花费时间:78
Iterator循环花费时间:31
普通for循环花费时间:97
foreach循环花费时间:47
lambda表达式foreach循环花费时间:79
Iterator循环花费时间:32
普通for循环花费时间:83
foreach循环花费时间:49
lambda表达式foreach循环花费时间:77
Iterator循环花费时间:34
普通for循环和lambda表达式foreach都很慢,Iterator最快
普通for循环最慢,应该是可以想象到的,因为LinkedList不能随机访问,每次获取都要从头到尾遍历,我们遍历10000次
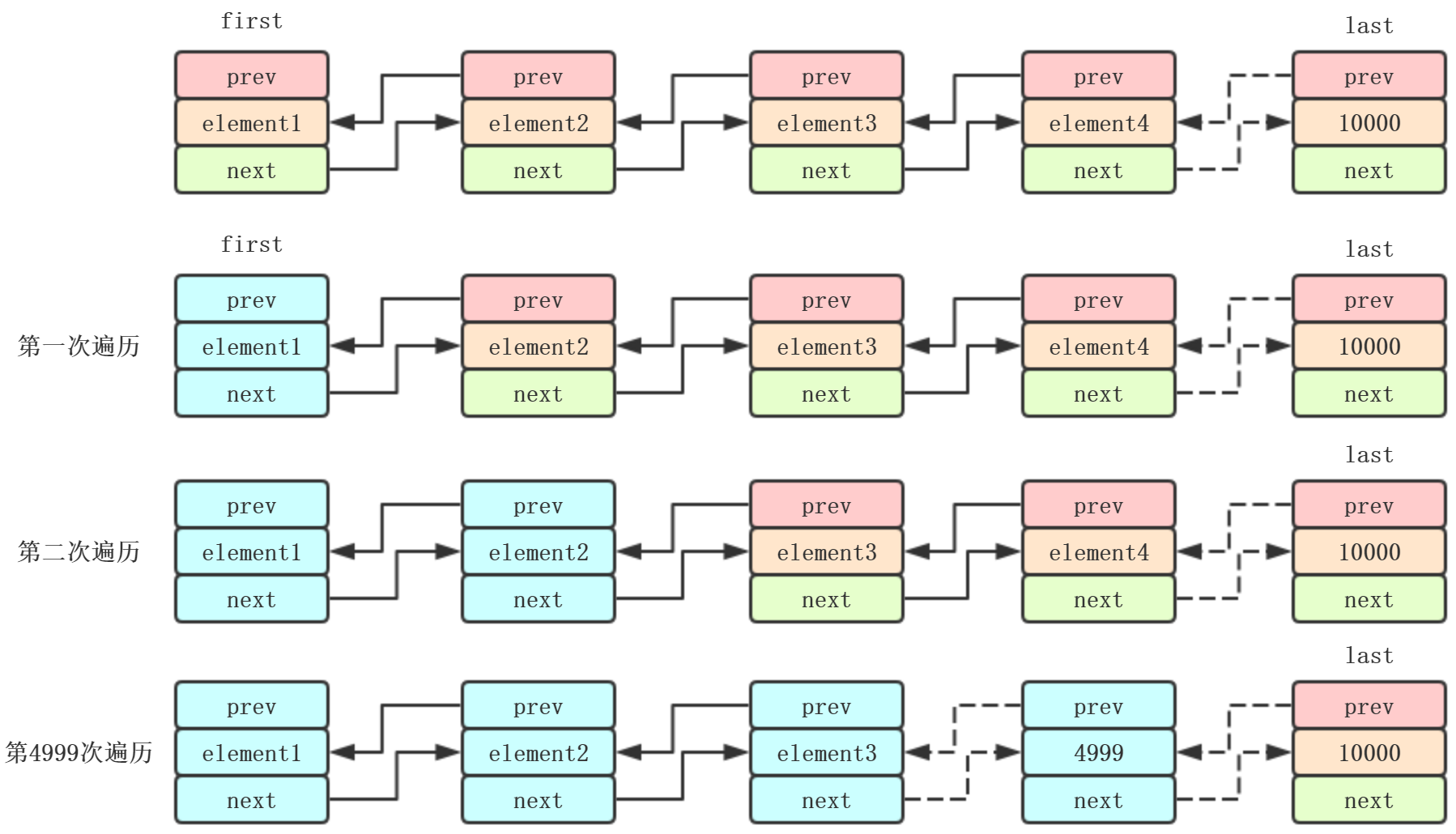
虽然使用二分法可以提高效率,靠近中间的index,效率真的很慢,例如4999,5000,5001
而Iterator通过ListItr实现:
private class ListItr implements ListIterator {
private Node lastReturned;//本次返回的node
private Node next;//本次返回的node的next节点
private int nextIndex;//下一个node对应的index
private int expectedModCount = modCount;
ListItr(int index) {
next = (index == size) ? null : node(index);
nextIndex = index;
}
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;//
next = next.next;
nextIndex++;
return lastReturned.item;
}
}
每次都会记录这次返回的node,下次遍历,直接取node.next,例如第4999次遍历的时候,直接返回element4998.next,而不需要像普通for循环
一样,先得到1,再是2,然后3,最后到4999
到这里,对LinkedList的了解已经差不多零,能得到的内容:
1、LinkedList由双向链表实现,add(index,element)的效率很高,只需要直接修改node的prev和next关系,但是需要new node
2、删除的时候也很快
3、不涉及到初始容量、加载因子、扩容等概念
4、不能随机访问,查询效率较慢相对于ArrayList差很多
总结:对链表的任意修改都可以归结:改变node的前后指向关系















 161
161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









