







词嵌入基本知识
维基百科中文语料分析(附实际评论案例)
https://blog.csdn.net/m0_58327216/article/details/124444990
阅读感想:
word2vec的输入是由多句话组成的语料。在使用word2vec必须要进行分词,分词之后才能得到词的向量,如果某个词,没有被正确分词出来,则不会有该的词向量。
为啥大家需要大的语料,因为要尽量包括中国所有汉字,还要尽可能地包括每个汉字的使用语法。

https://www.zhihu.com/question/357636409 词向量、词嵌入、词语的向量化表示、分词、词表、讲解的很详细。这就意味着可以输出已经训练得到的词表,以及对应的词向量。对于词表中没有出现的新词要赋予一个新的向量。
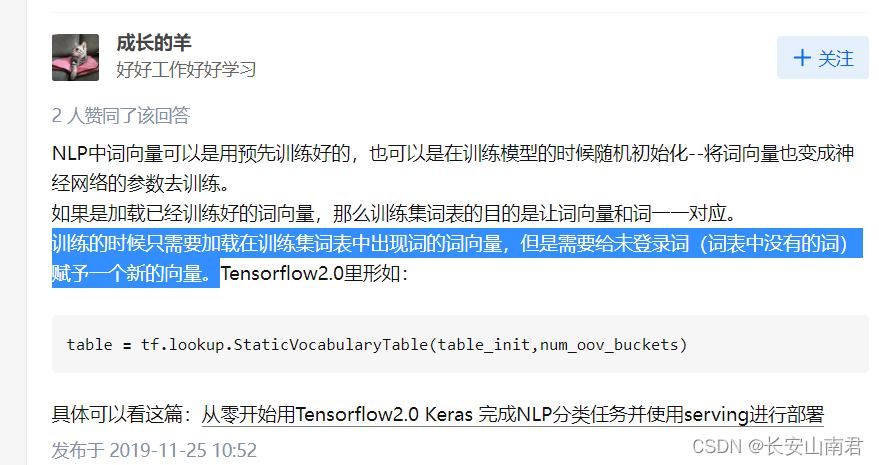

基于预训练模型的词嵌入
https://www.bilibili.com/video/BV1hZ4y1h7NQ/?spm_id_from=333.788 bert的词表
在BERT模型中添加自己的词汇(pytorch版)
https://zhuanlan.zhihu.com/p/391814780
中文BERT-base是以字为单位的,基本上已经涵盖了现代汉语所有的常用字。而且汉字是一个比较稳定的封闭集合,生活中不会随时造出新字来。
Bert系列一:词表示,从one-hot到transformer
https://zhuanlan.zhihu.com/p/365774595
依据以下文章的调研可知:可以使用谷歌官方发布的bert-base中文版本、哈工大讯飞实验室发布的bert-wwm、百度的ernie对某特定领域语料的词嵌入性能,再选择一个进行微调。近期腾讯提出的“神农”、澜舟科技提出的“孟子”及IDEA研究院提出的“二郎神”等轻量化模型,仅以十亿左右的参数量就在部分任务上达到了SO-TA结果,这些轻量化的预训练模型也可以尝试对比
[1]Zhe Zheng,Xin-Zheng Lu,Ke-Yin Chen, et al. Pretrained domain-specific language model for natural language processing tasks in the AEC domain[J]. Computers in Industry, 2022, 142: 103733.
[1]侯钰涛,阿布都克力木·阿布力孜,哈里旦木·阿布都克里木. 中文预训练模型研究进展[J]. 计算机科学, 2022, 49(7): 148-163.
bert预训练模型的
除了word2vec等常规的词嵌入方法,4年前出品的、大火的Bert,也必须要上马。。。 看起来也十分简单,注意测试 https://blog.csdn.net/qq_40887846/article/details/125161526
https://zhuanlan.zhihu.com/p/113639892
百度ERNIR3.0
PaddleHub实战篇{ERNIE实现文新闻本分类、ERNIE3.0 实现序列标注}【四】
https://blog.csdn.net/sinat_39620217/article/details/125071909
基于ERNIR3.0文本分类:(KUAKE-QIC)意图识别多分类(单标签)
https://blog.csdn.net/m0_63642362/article/details/126090938
PaddleNLP Embedding API
https://paddlenlp.readthedocs.io/zh/latest/model_zoo/embeddings.html#%E4%B8%AD%E6%96%87%E8%AF%8D%E5%90%91%E9%87%8F















 729
729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









