






由于项目中大量使用DoTween动画,在游戏进行到中后期,存在大量DoTween动画同时播放时会感到明显卡顿。故向上级汇报后,对DoTween做出单独优化
将Tween动画单独拎出来打一顿, 建立测试场景,输入gm即可调用3000次tween相关接口,放大Tween动画的性能消耗,将其它因素影响降到最低,发现以下性能优化点
1.减少DoKill的使用,优化424ms
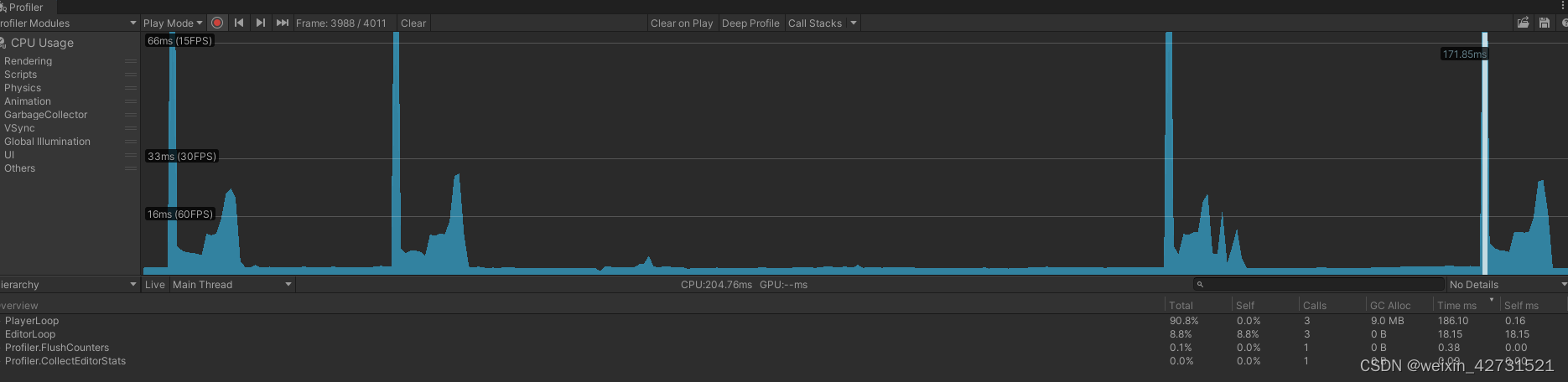
优化前

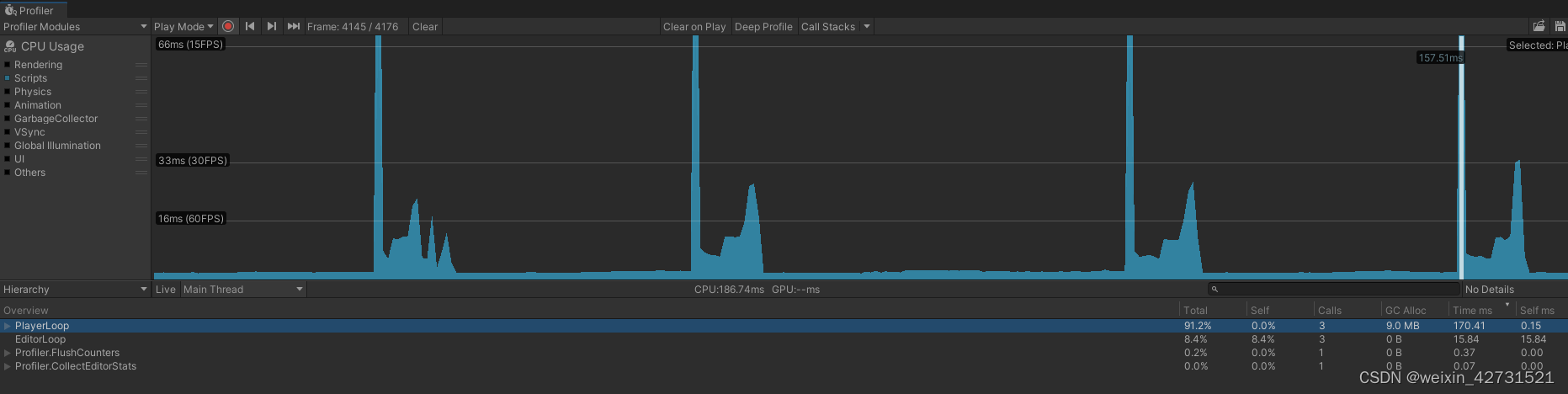
优化后


 从profile中可以发现, DoKill的性能消耗高达60%,超过一半的占比
从profile中可以发现, DoKill的性能消耗高达60%,超过一半的占比
观察源代码,TweenManager的FilteredOperation方法,其中这部分代码,每次调用都会遍历场上的所有正在播放的tween动画,找到与之相同的tween清除,最坏的情况下,需要遍历完整个数组,而绝大部分情况,是找不到与之对应的正在的tween动画的,因此就需要遍历完所有数组,也就是说大部分情况都是最坏的情况。在有大量tween执行的情况下,又执行大量DOKILL无疑是性能消耗的瓶颈。
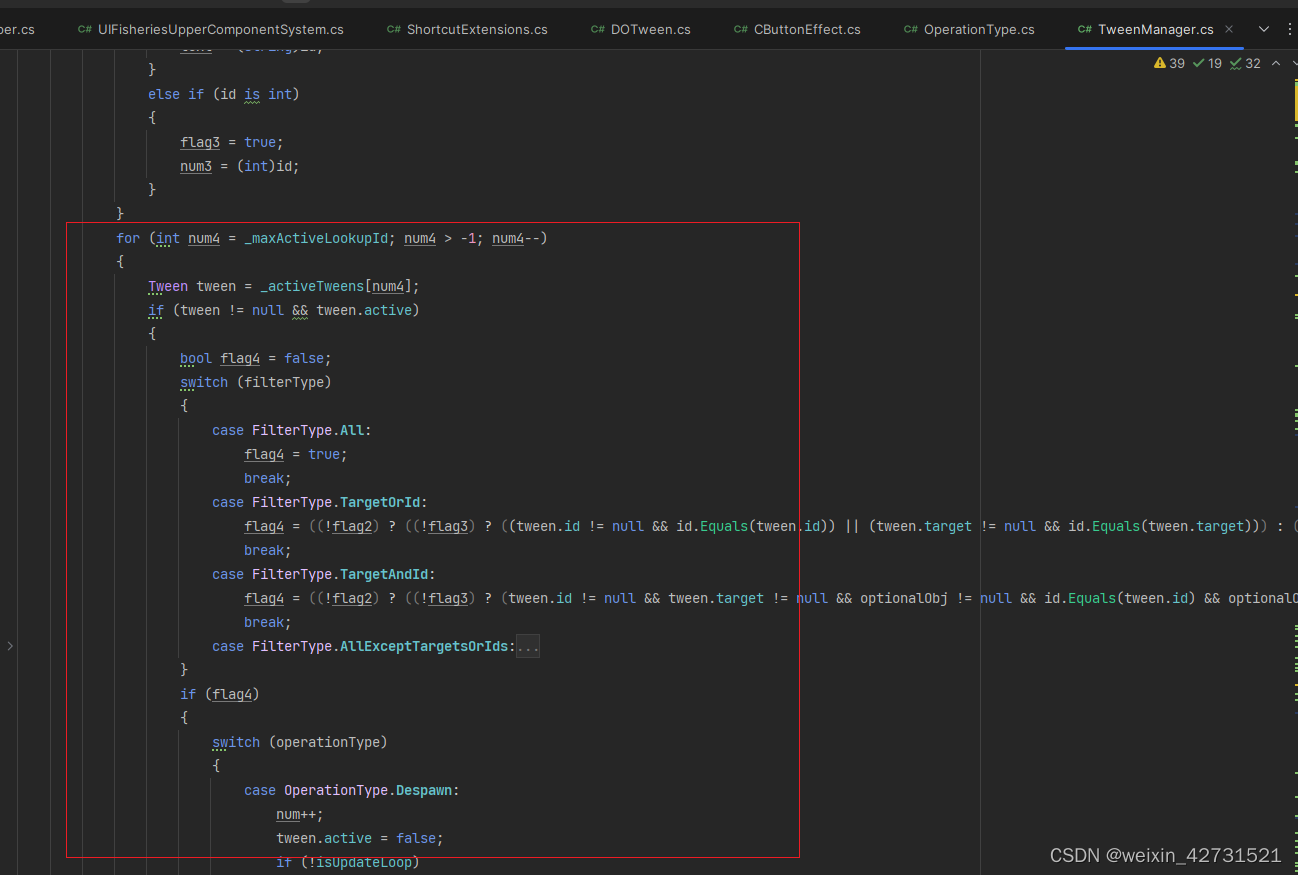
总结: 尽量不使用DoKill方法,或者可以使用Kill方法代替
优化:3000个实例 同时播放的情况下,将消耗从591ms变成167ms,优化424ms
2.重写Getweener 方法 优化50ms
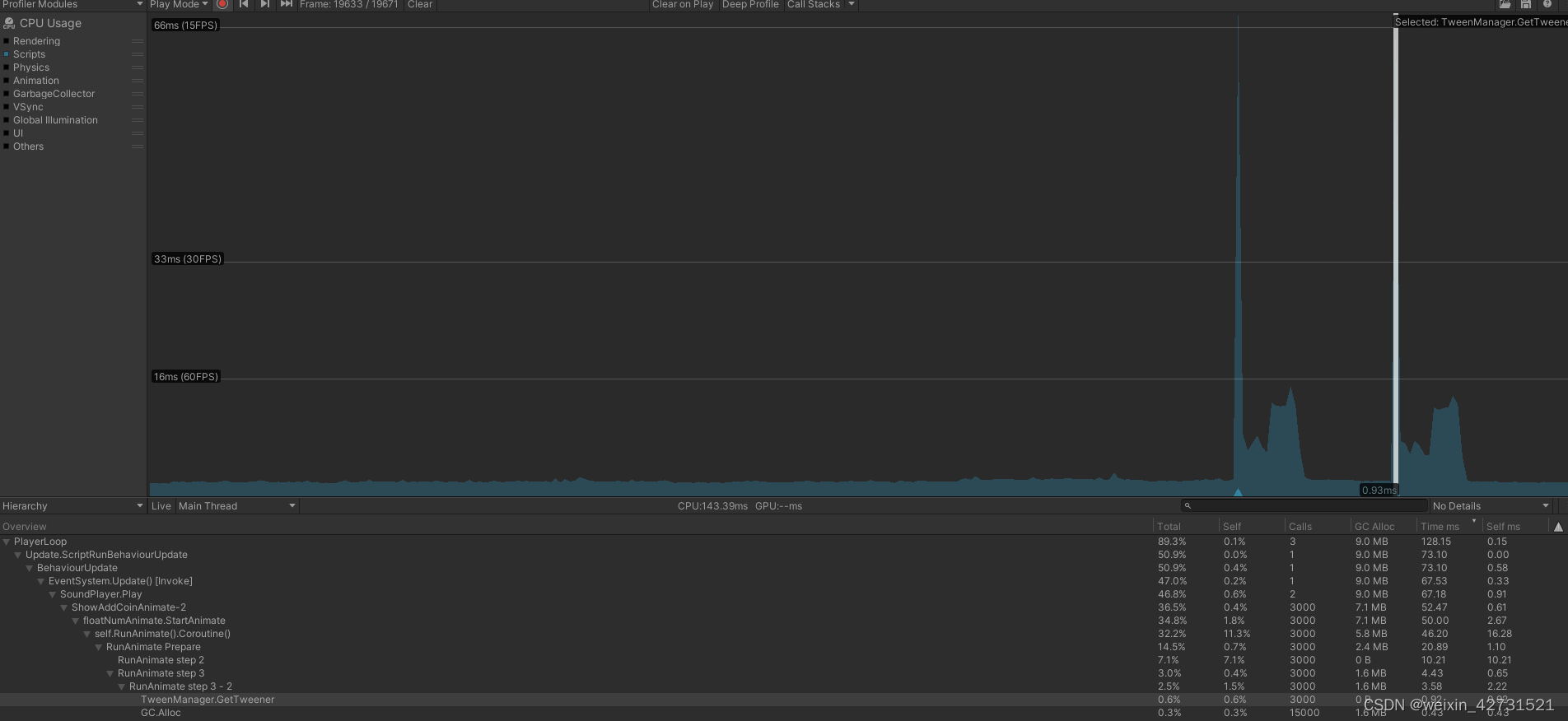
之前getween使用for在数组中查找tween动画,效率低下,改成字典查找后,耗时从180降低到130,减少50ms
优化前

优化后

internal static TweenerCore<T1, T2, TPlugOptions> GetTweener<T1, T2, TPlugOptions>(string key = null) where TPlugOptions : struct, IPlugOptions
{
if (key == null)
{
Type typeFromHandle = typeof(T1);
Type typeFromHandle2 = typeof(T2);
Type typeFromHandle3 = typeof(TPlugOptions);
key = string.Format("{0}{1}{2}",typeFromHandle, typeFromHandle2, typeFromHandle3);
}
TweenerCore<T1, T2, TPlugOptions> tween;
bool has = _pooledTweeners2.TryGetValue(key, out var stack);
if (has && stack.Count > 0)
{
tween = stack.Pop() as TweenerCore<T1, T2, TPlugOptions>;
}
else
{
// 扩容activeTween
if (totTweeners >= maxTweeners - 1)
{
IncreaseCapacities(CapacityIncreaseMode.TweenersOnly);
}
tween = new TweenerCore<T1, T2, TPlugOptions>();
tween.key = key;
totTweeners++;
}
AddActiveTween(tween);
return tween;
} internal static void RecycleTween(Tween tween)
{
// Type typeFromHandle = tween.typeofT1;
// Type typeFromHandle2 = tween.typeofT2;
// Type typeFromHandle3 = tween.typeofTPlugOptions;
// string key = typeFromHandle + typeFromHandle2.ToString() + typeFromHandle3;
Stack<Tween> stack;
bool has = _pooledTweeners2.TryGetValue(tween.key, out stack);
if (!has)
{
stack = new Stack<Tween>();
_pooledTweeners2[tween.key] = stack;
}
stack.Push(tween);
}总结: 在涉及查找时,直接使用字典的效率大于for循环查找,警惕for循环.
优化: 在3000个实例同时播放的情况下,优化50ms
3.减少Sequence使用 优化20ms
优化前

优化后

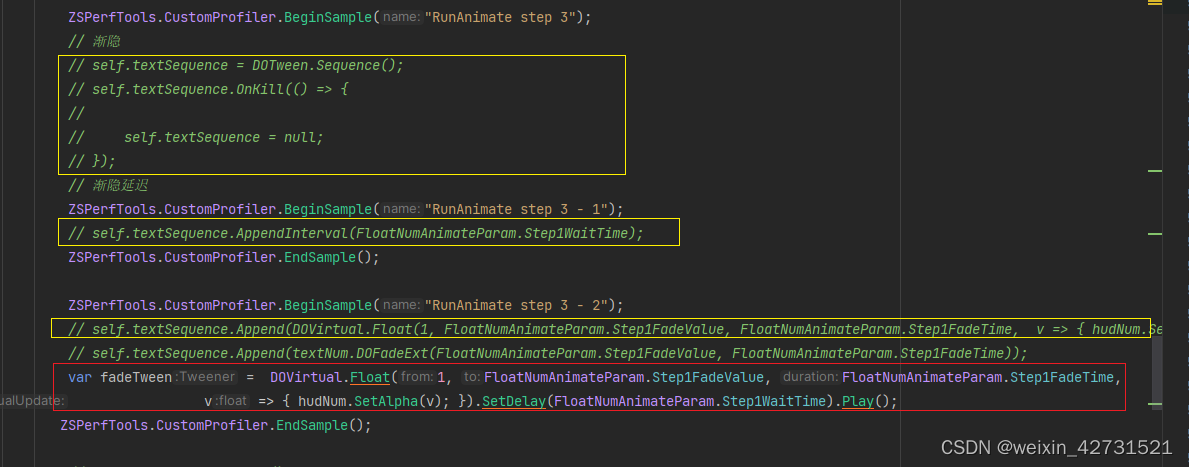
黄色为优化前代码, 红色为优化后, 舍弃掉DOTween.Sequence(该函数在对象池拿出来, 重置一系列操作消耗性能) 使用setDelay即可达到延迟效果,直接减少了DOTween.Sequence函数的一系列消耗
总结: 能直接使用dotween完成的功能, 尽量不要使用 Sequence,.
优化: 在3000个实例同时播放的情况下,优化20ms
4.正确使用DoScaleExt等方法
原本DoScale方法的gc消耗

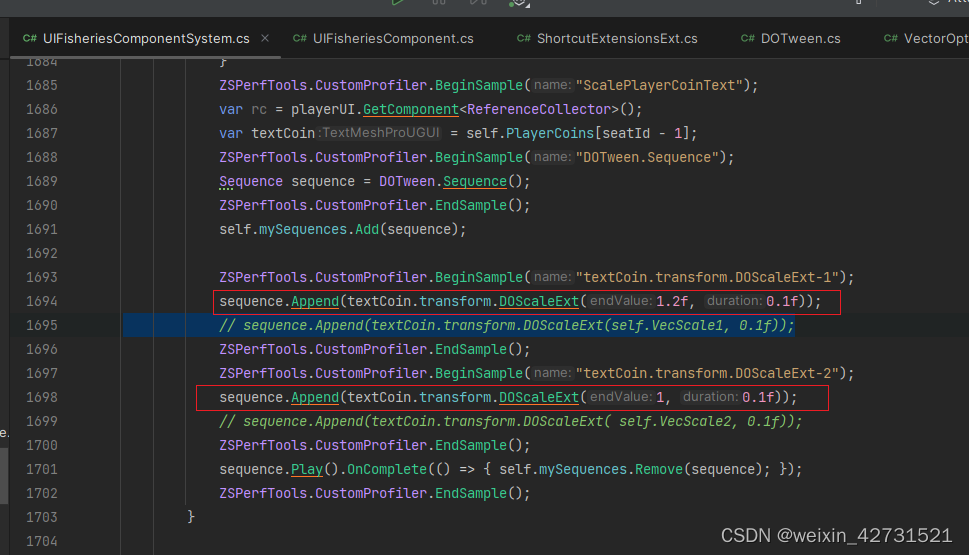
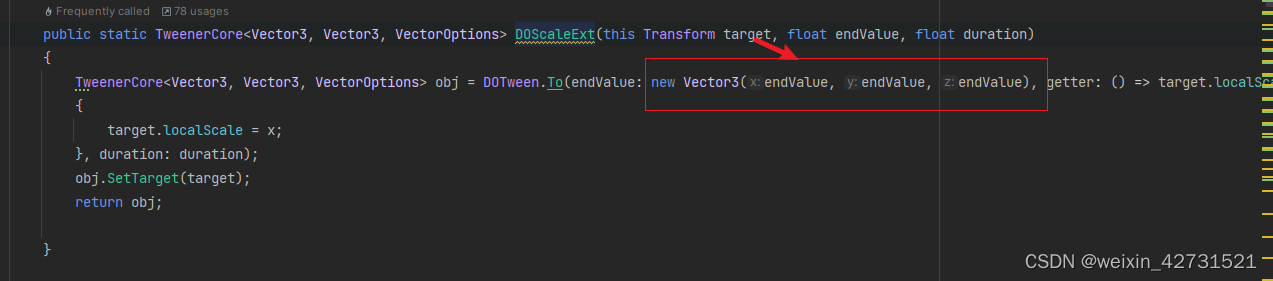
将常数传给底层,底层 DoScaleExt再new出坐标变量,每次new 都会产生一定的消耗和gc
优化后DoScale

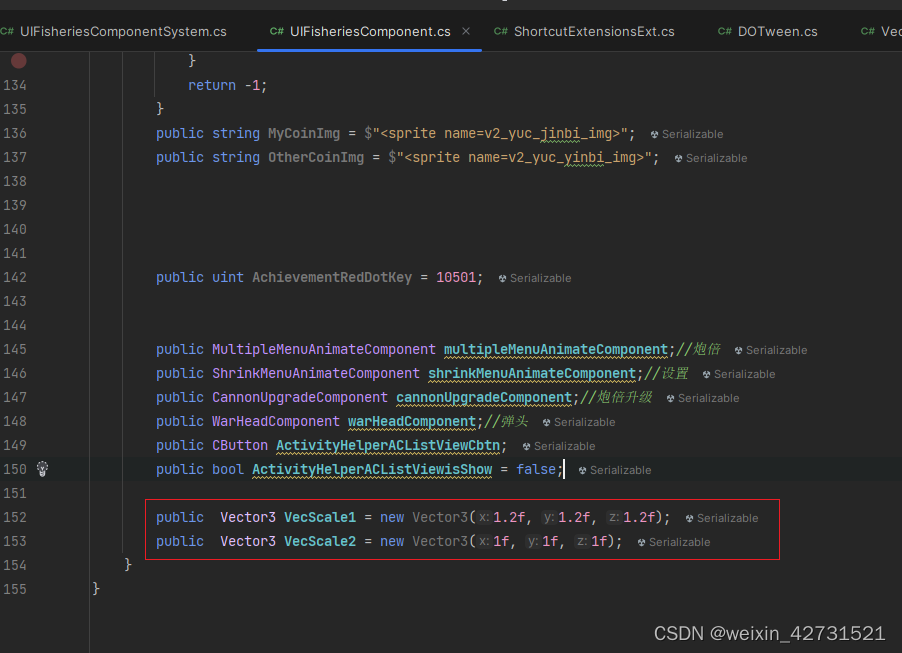
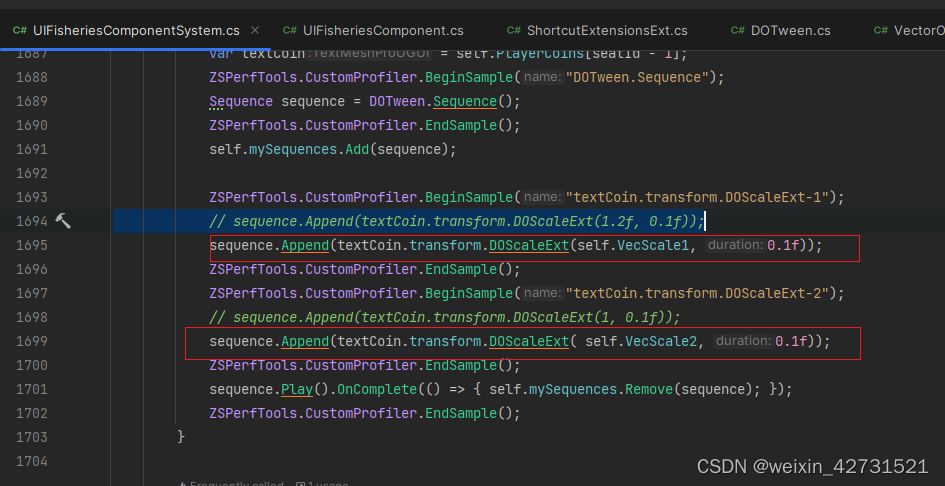
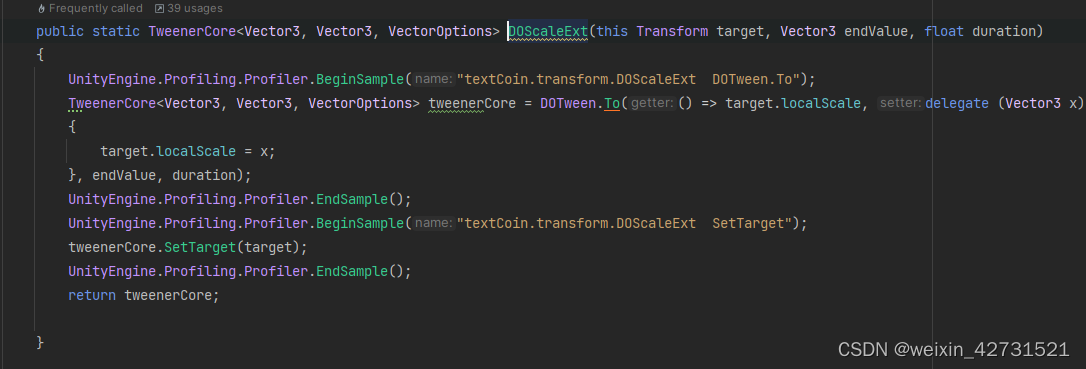
使用 DoScaleExt的重载,将已经new好的全局对象作为参数,减少了new和gc消耗
总结:类似DoScaleExt的方法,尽量使用上面方法优化
优化: gc减少了 110kb















 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









