






用GNN作为基分类器构建随机森林,结合集成学习和GNN优点
通过节点采样、特征选择、边dropout等方式将不同的子图构建为不同的训练集
然后用各种子图来训练GNN基分类器,其余特征用于训练全链接神经网络FCN
随机森林:一种机器学习方法,由多个决策树组成,每个决策树在随机选择的子样本和特征上训练,然后通过投票或者平均来确定最终的预测结果。
图神经网络(GNN)作为基分类器:传统随机森林中,基分类器通常是决策树,但是这里用GN来作为基分类器。
不同子图的构建:为了使用GNN来作为基分类器,将原始数据拆分成多个子图。这里面提到了好几种方法:节点采样(随机选择一部分节点)、特征选择(只选择部分特征)、边dropout(随机删除一些边),来构建不同训练集
训练GNN基分类器:针对每个子图,使用GNN进行训练,将图数据转换为预测结果。
训练全连接神经网络:使用全连接神经网络来处理剩余的特征,FCN处理向量数据。
输出对齐和聚合:每个子图和FCN都会产生一个输出,然后将它们对齐并聚合,生成最终的预测结果,这可能包括简单的平均或投票。
先补一下随机森林的知识:
随机森林里面每棵树看问题的角度不同,然后最终给一个输出,集成学习
它的超参数:有几棵树,各自怎么怎么样
为什么要用GNN来当基分类器,原因是:随机森林的基分类器是DT,DT的缺点是:容易过拟合,它们对复杂非线性关系的建模能力较弱(那就需要提取更多的特征)。对噪声敏感。
创新点:
(1)提出了一个随机森林算法和GNN相结合的框架,该框架利用GNN的关系能力和集成学习的优势
(2)提出一种对齐机制,通过有效利用特征选择后的剩余特征,进一步增强GNN基成模型的性能
(3)框架非常灵活,可以与各种广泛使用的骨干网一起使用
模型的框架图:
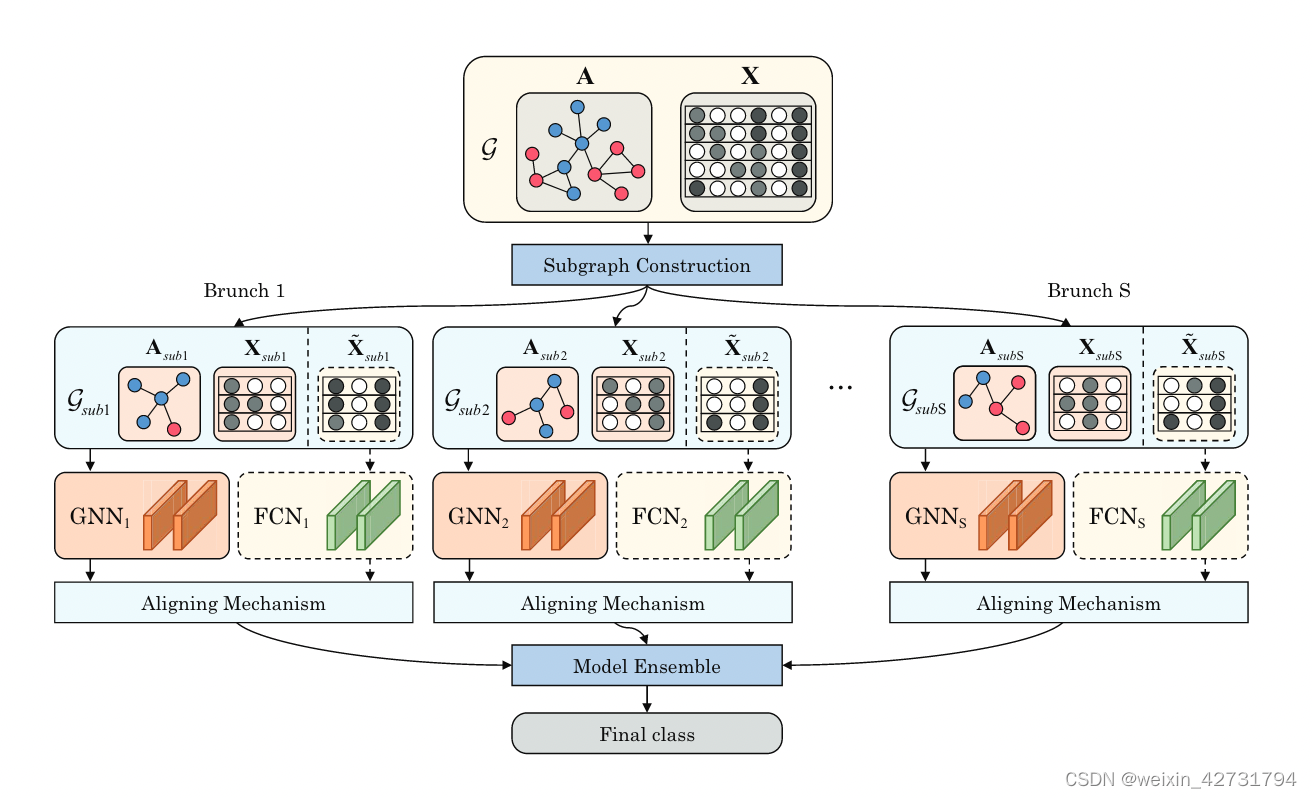
论文方法的大概介绍::
(1)构建子图的方式
- 节点下采样(按照一定比例)
- feature selection(按照一定比例)
- edge dropping.(边缘丢弃是为了增加子图的区别)
GNN用来处理图数据,FCN用来处理非图数据。
GNN输出和FCN输出对齐方式:Hadamard乘积,点乘的方法。我们需要确保GNN的输出和FCN的输出具有相同的维度和含义,

先得出标签值,然后再计算预测标签和真实标签的差值。
算法1:训练算法
输入是:G和X,下采样(比例阿尔法)还有多个GNN和FCN。
GNN输出一个值,FCN输出一个值,然后align。更新参数:通过应用梯度下降来最大化更新 Gθi 和 Fθi 的参数(公式4:Li = − ∑ vn∈VL loss (yin, ̃ yin) )
三个数据集
基线比较:
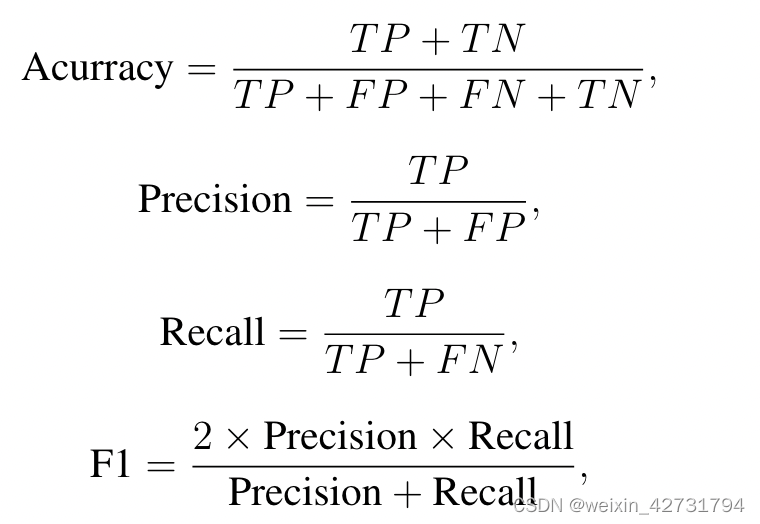
| DT、RF、Node2Vec、GCN、SGC、GAT、Boosting-GNN、JK-Nets、GraphSAINT、LA-GCN | |
4.3变体
为了更全面地了解每个模块在整体学习框架中的运作方式,并更好地评估它们各自对性能改进的贡献,我们生成了完整 RF-GNN 模型的几个变体。
RF-GNN 模型由三个主要模块组成:子图构建模块、对齐机制和模型集成模块。
为了进行消融研究。
超参数:
AdamW 优化器、200 轮训练。除 Node2Vec 的学习率设置为 0.005 外,所有模型的学习率均设置为 0.01。所有数据集上的 L2 权重衰减因子均设置为 5e-4。dropout设置为 0.3 至 0.5。对于所有模型,GNN 层的输入和输出维度都是一致的,分别为 128 或 256。
GAT 和 RGAT的注意力头设置为 4。
我们使用 Pytorch 1.8.0、Python 3.7 实现 RF-GNN。 10、PyTorch Geometric [27] 与稀疏矩阵乘法。所有实验均在配备 9 Titan RTX GPU、2.20GHz Intel Xeon Silver 4210 CPU 和 512GB RAM 的服务器上执行。操作系统是Linux bcm 3.10.0。
GCN跟GAT模型比其他模型在不同数据集上表现更好,主要是因为它们引入了全局信息或注意力机制来适应特定任务。
实际效果:
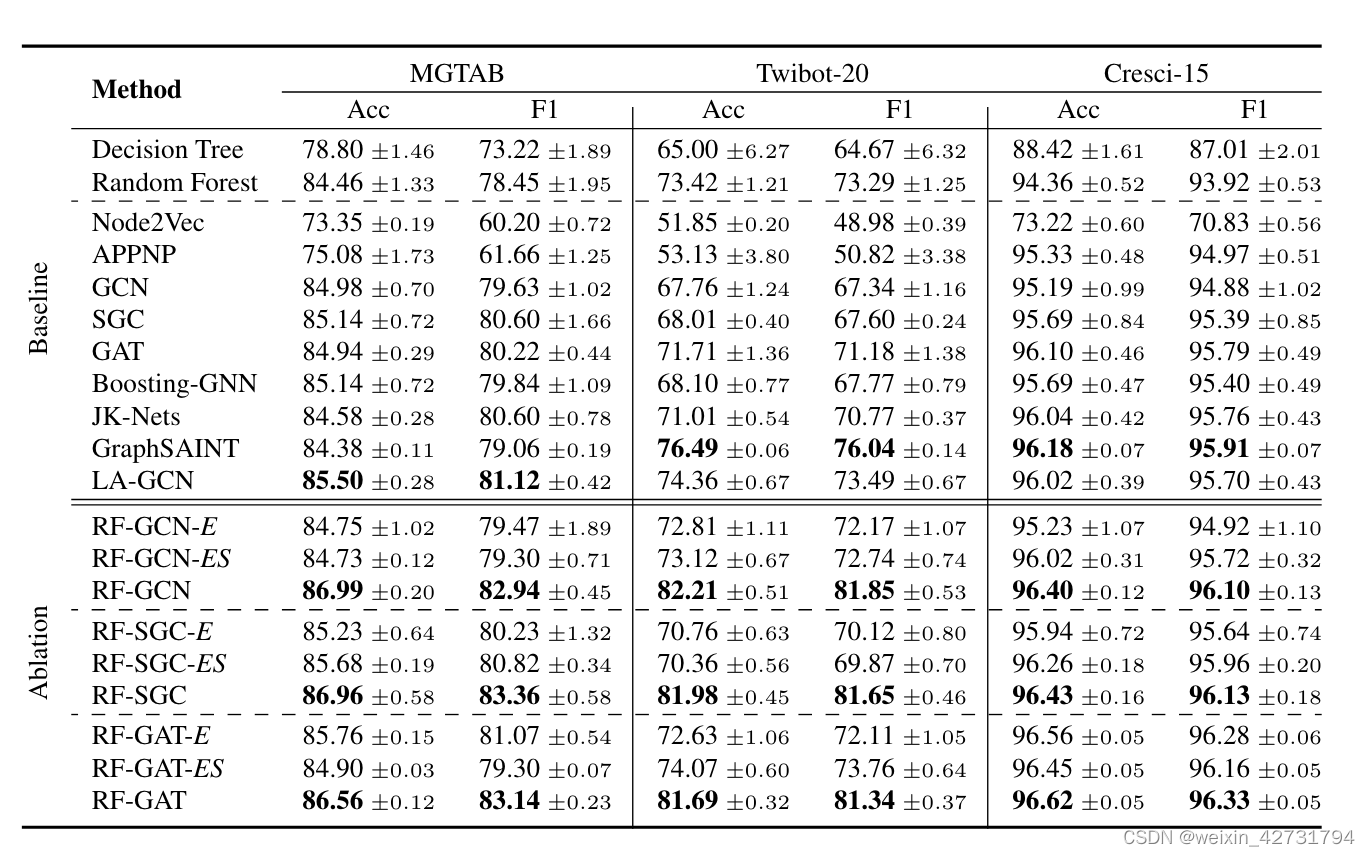
SGC模型从GCN中去除了非线性激活函数。尽管所有数据集的准确性略有下降,但与 GCN 相比,SGC 可以实现相似的性能。
GCN方法讲归一化邻接矩阵和特征矩阵相乘,再将其与可训练参数矩阵相乘,以对整个图数据进行卷积运算。
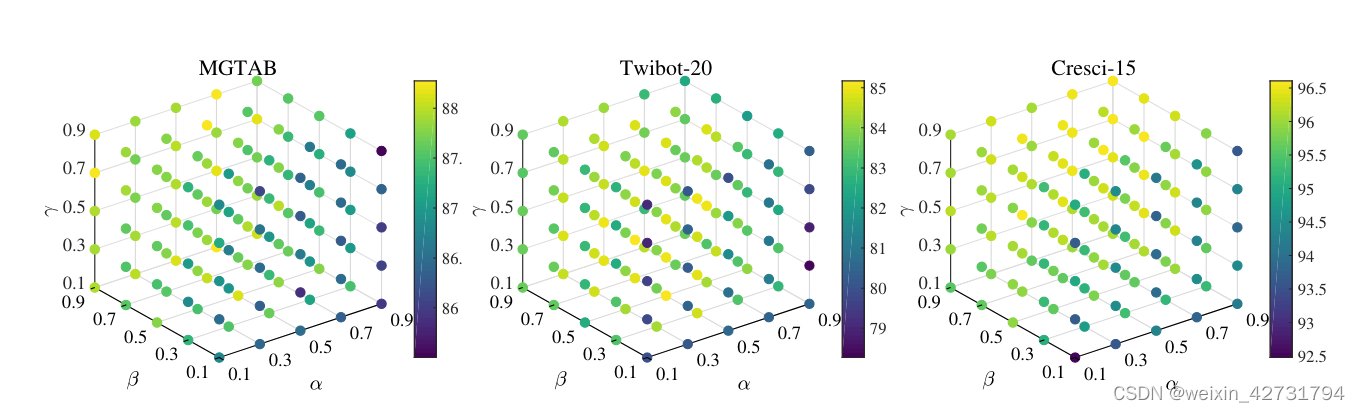
RF-GCN 的 a 的最佳值为 0.5,在Cresci-15数据集上,RF-GCN的性能随着α的增加而逐渐提高。总体而言,当所有数据集的 α 在 0.3 到 0.7 范围内时,RFGCN 表现出稳定性。
特征选择概率β分析:特征选择比是对RF-GCN性能影响最大的参数。在所有数据集中,当 β 小于 0.3 时,RF-GCN 的性能很差。这可能是由于特征数量不足,阻碍了模型有效学习和检测机器人的能力。在 Twibot-20 数据集上,当 β 设置为 0.7 时,RF-GCN 表现最佳。在 MGTAB 和 Cresci-15 数据集上,β 的最佳值为 0.9,以获得最佳性能。
边缘保持概率 γ 分析:当所有数据集上 γ 在 0.1 到 0.9 范围内时,RF-GCN 是稳定的。减小γ值会增加数据增强对图数据的效果,模型性能会略有提升。
这意味着RF-GCN-E的每个基分类器都是在相同的训练集上训练得到的。这样做会导致基分类器之间的相似度很高。















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









