






-
论文出发点或背景
大卷积核网络存在两个未解决的问题:(1)传统的卷积神经网络或者transformer的设计原则(2)transformer在多模态的应用十分广泛,想看一下卷积在其他领域的应用是否也有如此普适性。
针对上面问题,文章提出两点:(1)提出四个大核架构设计指导,关键点是找到大核跟小核的区别,大核看的很宽。根据这个指导,提出的网络效果很好,达到了88%的精确度,速度也很快。(2)卷积神经网络原本并不优秀的领域内,通过使用大核,达到的效果也十分不错。
Our model shows universal perception ability across multiple modalities with a unified architecture so it is named UniRepLKNet.
replknet提出要用超大核,小核的感受野非常小。
现在使用超大核又逐渐变得受欢迎,但是现在的大核还是遵循以往的卷积神经网络架构,replknet用的是swin transformer,slak用的是convnext,架构设计仍在探索。
-
论文创新思路
将一个3*3的卷积核增加到小核convnet里面时,预期出现三种效应:扩大感受野、增加空间模式的抽象层次、提高模型的表现能力(增加了卷积层的深度,引入更多参数和非线性)。大卷积核会增加宽度而不是增加深度,节省资源去干别的事情。
所以提出了四个指导意见:
- 引入SE Block去增加深度
- 用Dilated Reparam Block来重新参数化大卷积核层,提高性能但是不增加cost
- 决定卷积核大小的尺寸是后续任务,通常大核用在中间和比较高维层上。
- 扩展模型深度的时候,添加3*3的卷积核
这个convnet网络实现了三个效果:大感受野,小核去抽取更多的空间特征、轻量化块去增加深度。
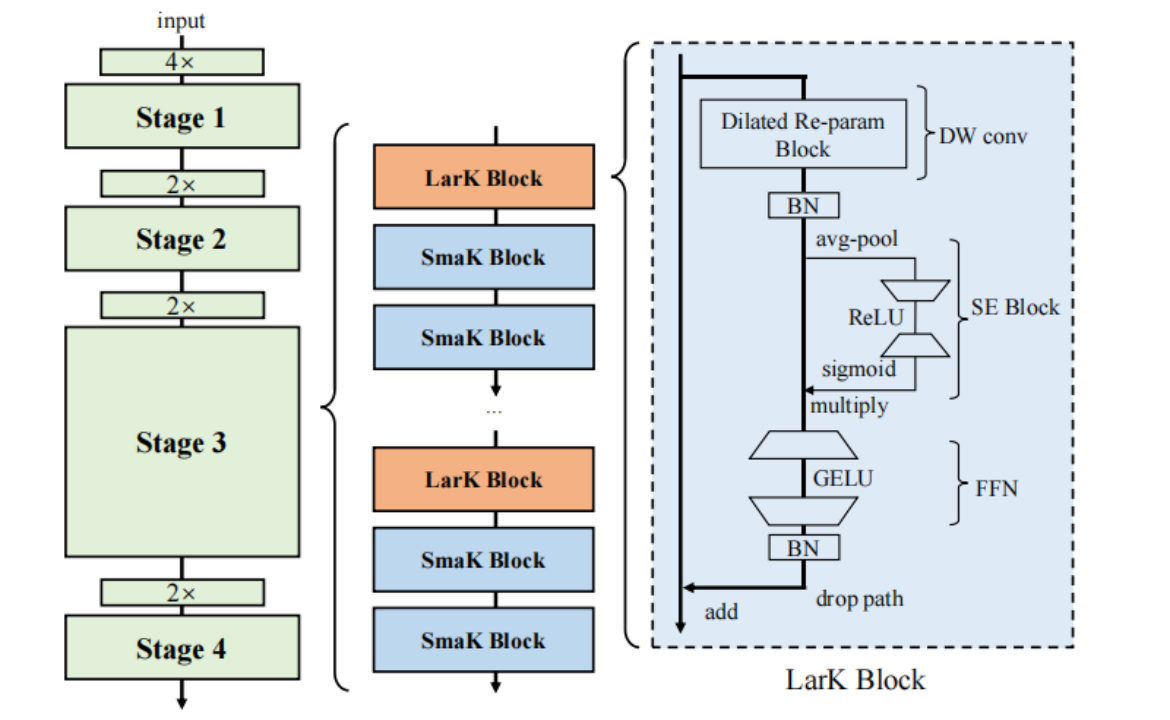
一个convnet有四个阶段,第1阶段用samk block,第2阶段用lark block,第4阶段用lark block,第3阶段用samk block和lark block组合。每个stage用步长为2的3*3卷积来下采样来连接。
一个lark block由一个dilated reparam block、一个SE block、FFN和BN层组成。
大核和小核的唯一区别就是:后者用3*3的深度分离卷积来替代前者的dilated reparam block。
那samk block的组成如下:DW 3*3 conv, SE block,FFN和BN层。
-
论文方法的大概介绍实际效果
描述 "Dilated Reparam Block" 的模块,其设计旨在通过等效转换来增强非扩张大核卷积层。以下是关键点的解释:
Dilated Reparam Block:
这是一个模块,用于增强非扩张大核卷积层。它由一个非扩张的小核和多个扩张的小核层组成。
超参数:
这个模块有一些超参数,包括大核的大小 K、并行卷积层的大小 k,以及扩张率 r。在示例中,模块使用了四个并行的卷积层,其中 K=9,r=(1,2,3,4),k=(5,3,3,3)。
灵活性:
并行分支的核大小和扩张率是灵活的,唯一的约束是它们的等效核大小不应超过大核的大小 K。
转换为大核卷积层: 为了将 Dilated Reparam Block 转换为大核卷积层进行推理,首先将每个批归一化层(BN)合并到前面的卷积层中,然后将具有扩张率 r > 1 的每一层使用特定的函数进行转换,并将所有结果核进行适当的零填充后相加。例如,在示例中,具有 k=3、r=3 的层将被转换为一个稀疏的 7×7 核,然后添加到 9×9 核中,每边填充一个像素的零
训练阶段:
大核卷积和小核卷积同时使用,大核和小核卷积的输入在BN层之后相加。
训练结束后,用结构重新参数化的方法,将BN层整合到卷积层中。
稀疏模式的获取,用扩张卷积。
将整个块等效转换为单个非扩张卷积层。
将具有小核的扩张卷积层等效地转换为具有稀疏大核的非扩张卷积层。等效核的大小为 (k − 1)r + 1
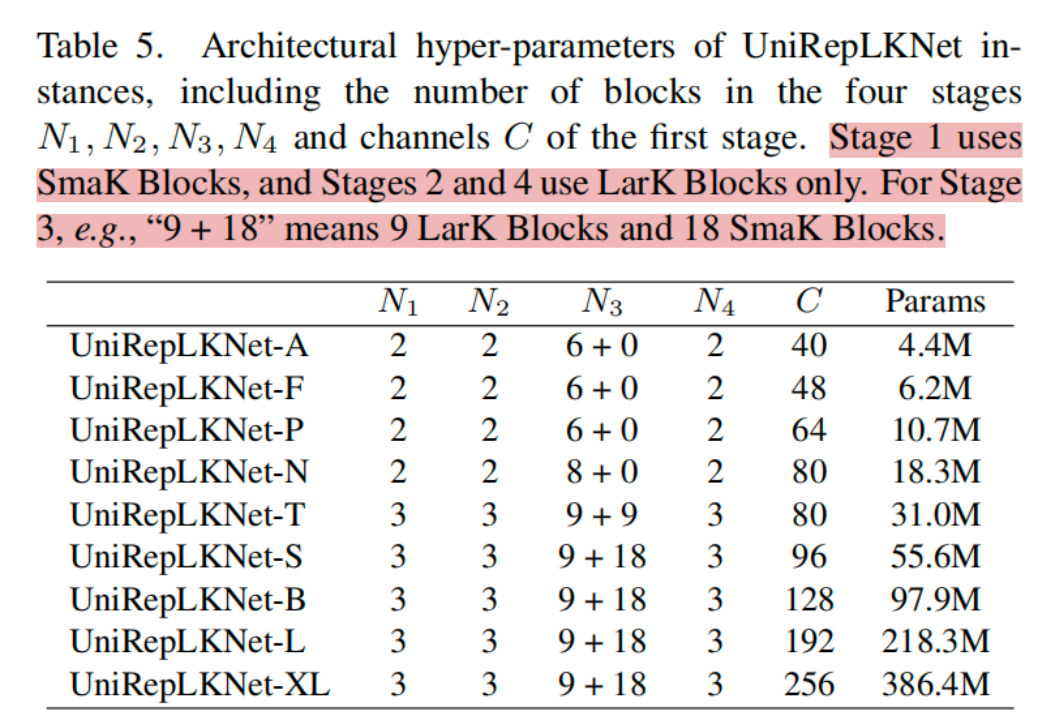
The numbers of such blocks in the four stages are denoted by N (N1,N2,N3,N4),
respectively。By default, the last three stages use 13×13 Dilated Reparam Block as the DW layer, which means K=13, k=(5,7,3,3,3) and r=(1,2,3,4,5); the first stage uses DW 3×3 conv as the DW layer.
通用网络:
为了去计算这个通用能力,我们将不同的数据预处理成B*C'*H*W,其中B为batchsize ,C由模态决定。我们直接用这个网络来处理多模态,用于图像处理任务的UniRepLKNet可以看作是C’ = 3的通用网络。C在下图里面写明了,它是第一阶段的channels C.
效果:
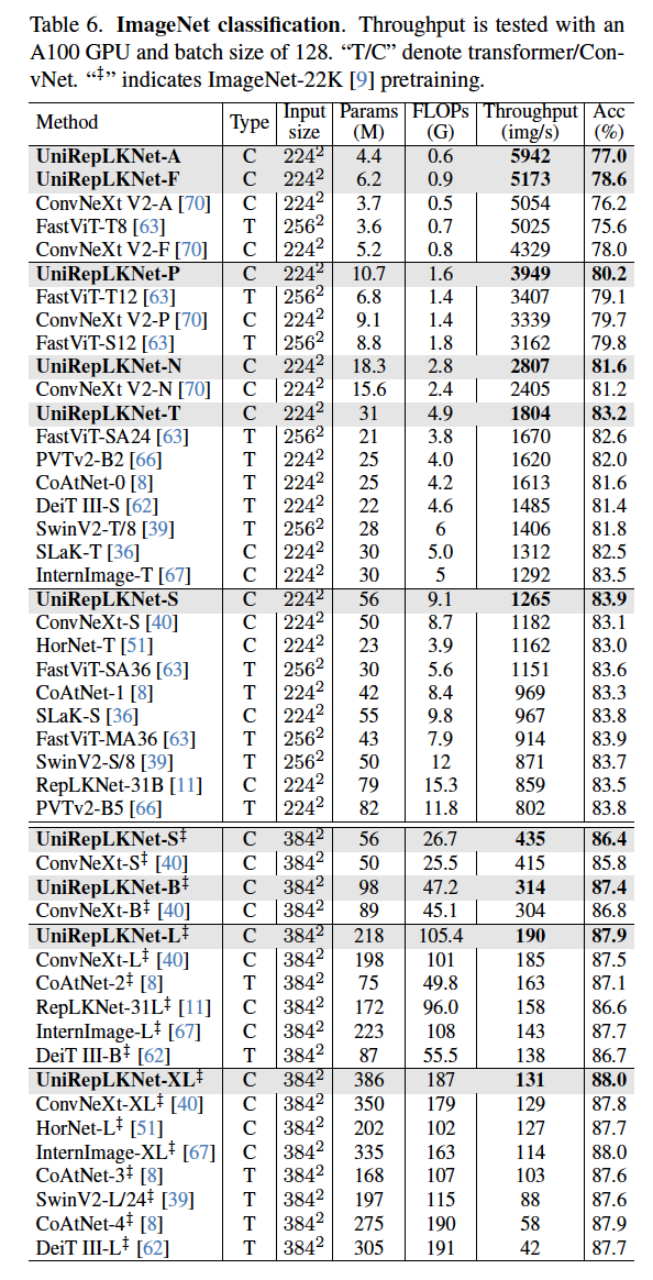
ImageNet classification
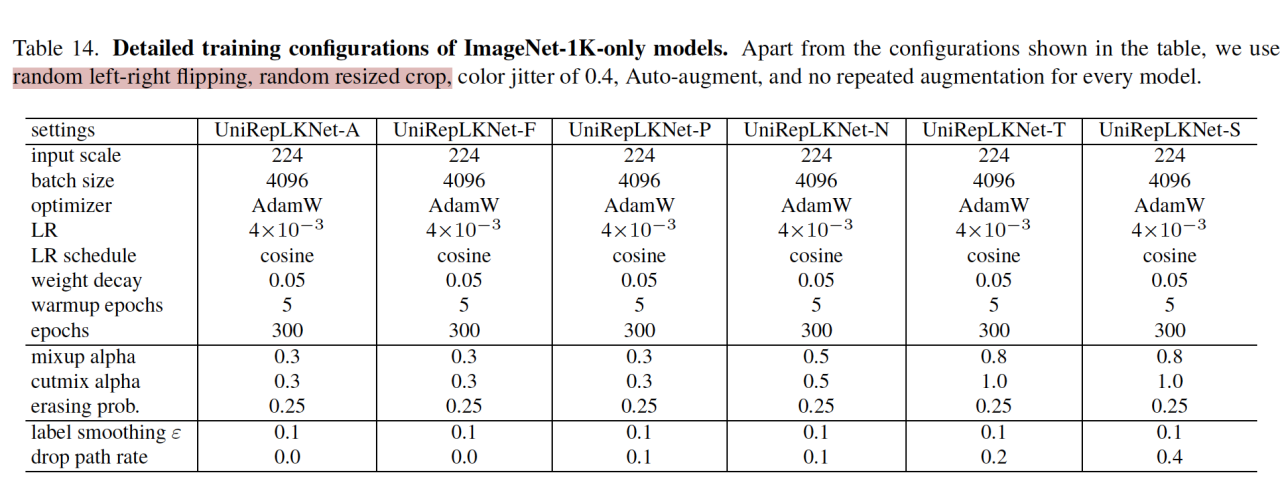
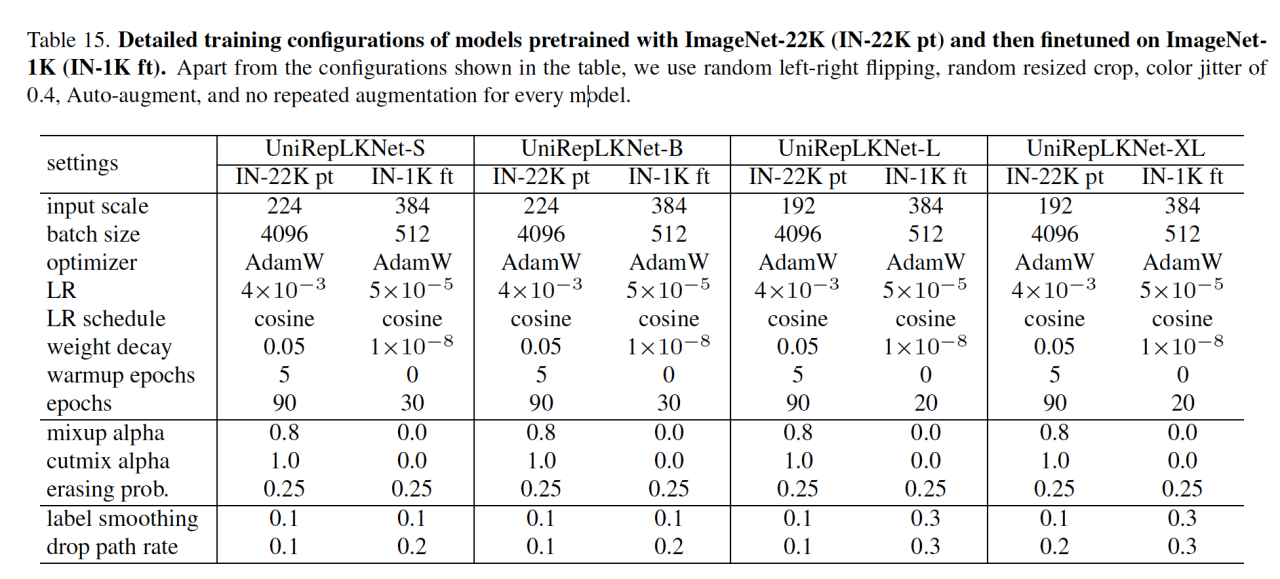
训练了好多模型:UniRepLKNet-A/F/P/N/T/S(ImageNet-1K)、UniRepLKNet-S/B/L/XL on ImageNet-22K。前一个训练了300个epoch,后一个训练了90个epoch并且用 ImageNet-1K进行了30个epoch的微调。训练的目的是为了增加训练速度。用同样的A100 GPU来进行评估(batchsize都是128)。
有个句子进行摘抄:
UniRepLKNet-A/F outperforms ConvNeXt-V2-A/F by 0.8/0.6 in the accuracy and runs 19%/17% faster, respectively.(表示性能提升)
问题:为什么要跟这个网络进行对比呢?(ConvNeXt)
答案:这个网络比较新,在23年提出了V2版本,同样是一个纯卷积神经网络模型。
(ConvNeXt网络知识补充:facebook ai 22年1月发表,是一个纯卷积神经网络模型,在分类任务和识别任务中超越了Swin-T 模型达到最佳的性能表现,它的思想是依照transformer思想对resnet50/200进行一些改进:1. Macro design 2. ResNeXt 3. Inverted bottleneck 4. Large kernel size 5. Various layer-wise Micro designs)
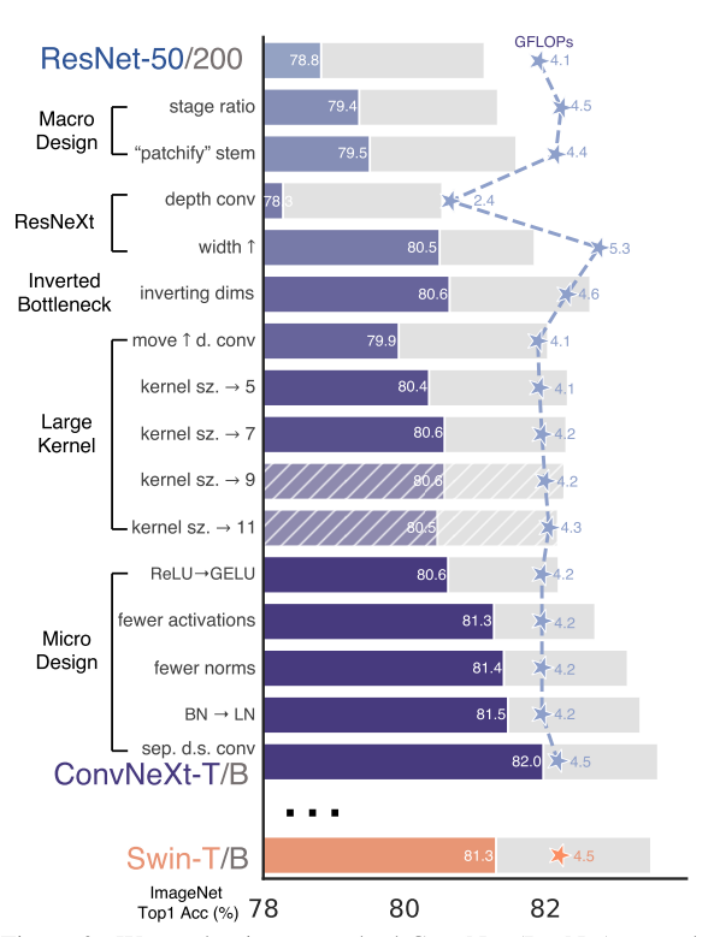
ResNet 和 Swin-T 网络均有四个 stage 阶段,然而 Swin-T 各个阶段堆叠 Block 块的比例为 1:1:3:1,Swin-L 堆叠的比例为 1:1:9:3,由此可以发现 Transformer 网络的第三层的堆叠数量较多,因此 ConvNeXt 网络依照这个比例将 ResNet 各阶段的堆叠次数从 (3, 4, 6, 3) 调整为 (3, 3, 9, 3) ,其比例也保持在 1:1:3:1。一个很神奇的点,这个stage ratio
最终效果:
-
个人对这篇论文的理解
我关注的点:
- 它的分类精度达到了88%,在XL的结构是(33,9+18,3)并且经过了预训练。
- 里面有一个点我在上面也提到了,说网络结构最好是1131的比例。
- 大卷积核
- 多种模态的数据分类效果都很好,有通用意义
configure:
training epoch are set to 100 and drop path rate is set to 0.1

















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









