







 本文基于淘宝APP的用户行为数据进行分析,涵盖流量类、用户类、用户行为和商品购买等多个方面。发现流量在双12预热期间大幅提升,但用户活跃度和支付转化率降低,用户购买次数平均值较低,复购率未达到忠诚度模式。用户活跃时间集中在19点至23点,收藏和购物车功能使用广泛,但支付转化率不高。建议优化这两个功能以提高转化率。此外,商品购买以长尾效应为主,缺乏爆款商品,需要关注高转化率商品并优化低转化率商品的体验。
本文基于淘宝APP的用户行为数据进行分析,涵盖流量类、用户类、用户行为和商品购买等多个方面。发现流量在双12预热期间大幅提升,但用户活跃度和支付转化率降低,用户购买次数平均值较低,复购率未达到忠诚度模式。用户活跃时间集中在19点至23点,收藏和购物车功能使用广泛,但支付转化率不高。建议优化这两个功能以提高转化率。此外,商品购买以长尾效应为主,缺乏爆款商品,需要关注高转化率商品并优化低转化率商品的体验。
淘宝APP用户行为数据分析研究
一、项目背景
1、分析背景
电子商务的迅速发展和移动互联网的普及,使得越来越多的人选择方便快捷的网上购物,淘宝作为国内最大的电商交易平台之一,拥有巨大的流量优势。
在淘宝APP上,商品的搜索、分类导航、个性化推荐和广告等通过让用户在短时间内了解到更多可能需要或者喜欢的商品而促进购买,同时可以通过数据埋点,收集和分析用户的数据,实现更精细化的运营。
本文基于数据集的特点,利用python对淘宝APP的用户行为数据进行分析,得出可能存在的业务问题,并提出推荐的解决策略。
2、数据来源
数据集来源于阿里云天池的官方数据集: User Behavior Data from Taobao for Recommendation.
数据集中包含了2017年11月25日至2017年12月3日之间,约一百万随机用户的所有行为 (行为包括点击、购买、加购、收藏),共有1亿多条记录,数据集的每一行表示一条用户行为,由用户ID、商品 ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
| 列名称 | 说明 |
|---|---|
| 用户ID:user_id | 整数类型,序列化后的用户id |
| 商品 ID:item_id | 整数类型,序列化后的商品ID |
| 商品类目ID:category_id | 整数类型,序列化后的商品所属类目ID |
| 行为类型:behavior | 字符串,枚举类型,包括(“pv”,“buy”,“cart”,“fav”) |
| 时间戳:timestamp | 行为发生时的时间戳 |
行为类型说明:
| 行为类型 | 说明 |
|---|---|
| pv | 商品详情页pv,等价于点击 |
| fav | 收藏商品 |
| cart | 将商品加入购物车 |
| buy | 商品购买 |
3、数据理解
(1)数据集只涵盖了9天的用户行为,时间较为短;
(2)数据集内容只包括了:用户ID、商品 ID、商品类目ID、行为类型和时间戳,有很大的局限性,有分析价值的是行为、商品ID、时间、商品类目ID这四个维度。
(3)数据集有1亿多条记录,数据量过大,本文随机抽取其中10%的数据作为代表分析,后续文中所表述的数据都是基于这10%的数据中在2017年11月25号~2017年12月03号共9天的行为数据,而不是所有的用户行为数据。
二、明确问题&搭建分析框架
1、提出问题
根据AARRR模型,在用户生命周期各环节的电商数据指标包括:
- 用户获取(Acquisition):渠道曝光量、渠道转化率、日应用下载、日新增用户数DNU(Daily New User)、获客成本CAC
- 用户激活(Activation):日活跃用户数DAU、日活跃率、周活跃率等
- 用户留存(Retention):次日留存率、3日留存率、7日留存率、30日留存率等
- 获得收益(Revenue):客单价、用户购买率、平均用户收入ARPU(average revenue per user)、平均付费用户收入(average revenue per paying user)、生命周期价值LTV(Life Time Value)、复购率
- 推荐传播(Referral):转发率、转化率、K因子
本数据集中只包含用户行为数据时间、用户ID、商品ID、商品类目ID、行为类型(点击、收藏、加购、购买),因此,可以分析的指标: - 用户获取阶段:点击量(浏览量PV)
- 用户激活阶段:日活跃用户数、周活跃用户数
- 用户留存阶段:次日留存率、2日留存率、3日留存率、7日留存率
- 获得收益阶段:复购率、回购率(复购率是一个时间窗口的多次消费行为,回购率是两个时间窗口内的消费行为)
- 推荐传播阶段:无
基于本数据集的内容特征,本次分析将从以下几个方面进行:
(1)基于AARRR模型对相关指标进行统计分析,了解淘宝APP的运营情况。
(2)用户行为时间分布分析,找到用户的活跃时间规律,进而进行针对化的活动营销。
(3)用户行为路径分析,找到可以提升转转化率的环节
(4)利用RFM理论,找出核心付费用户群体,并分析核心用户群体的用户行为分布(每天的行为统计分析)。
(5)商品的购买分布分析。
2、分析框架
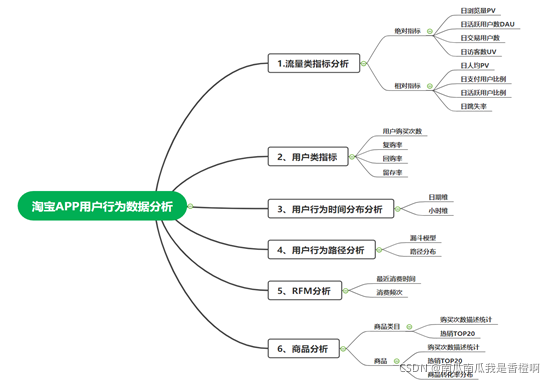
三、数据处理
1、导入相关包及数据
import time
import copy
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import pyecharts.options as opts
from pyecharts.charts import Funnel
分析在jupyter notebook中进行,可视化主要使用matplotlib完成,为了方便显示,进行matplolib有关参数设置:
%matplotlib inline
plt.rcParams["font.sans-serif"]=["SimHei"] #用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False #用来正常显示负号
plt.style.use("ggplot")
导入原始数据:
dt = pd.read_csv('./UserBehavior/UserBehavior.csv',
names=['user_id', 'item_id', 'category_id', 'behavior_type', 'timestamp'])
print('原始数据shape',dt.shape)
原始数据shape (100150807, 5)
原始数据集中一共包含100150807条数据,由于个人计算机限制,仅从中抽取10%的数据进行处理分析。
抽取10%的数据:
dt = dt.sample(frac=0.1)
dt.info()
采样的数据shape: (10015081, 5)

数据shape为(10015081,5),各字段数据类型符合要求,采样的数据集大458.5M。
2、数据清洗
(1)缺失值处理
dt.isnull().sum()

结果显示数据没有缺失值,比较完整干净。
(2)重复值处理
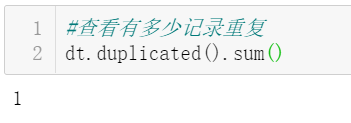
结果显示数据集中1条重复记录,因此,删除这条重复的数据。

(3)去除异常值
根据源数据集介绍,可知道数据的日期应在2017年11月25日至2017年12月3日之间,故根据这条规则对数据进行异常处理。
# 保留时间在2017-11-25 00:00:00至2017-12-4 00:00:00之间的数据,合计9天
dt = dt[(dt['timestamp'] >= 1511539200) & (dt['timestamp'] < 1512316800)]
print('时间段筛选后数据shape:',dt.shape)
# 按时间升序排列
dt = dt.sort_values(['timestamp','user_id']).reset_index(drop=True)
输出结果: (10009697, 5),说明原数据集中包含了不在2017年11月25日~2017年12月3日区间的用户行为记录。
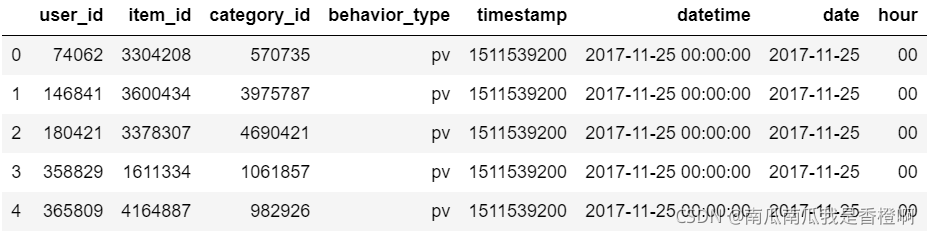
(4)时间维度拆解,增添新列
时间戳保持原数据形式,新添加日期-时间列、日期列、小时列。
date_times = []
dates = []
hours = []
for t in dt['timestamp']:
date_time = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(t))
date_times.append(date_time)
date_ = time.strftime('%Y-%m-%d',time.localtime(t))
dates.append(date_)
hour = time.strftime('%H',time.localtime(t))
hours.append(hour)
dt['datetime'] = date_times
dt['date'] = dates
dt['hour'] = hours
dt.head()
四、流量类指标分析
1、流量类绝对指标
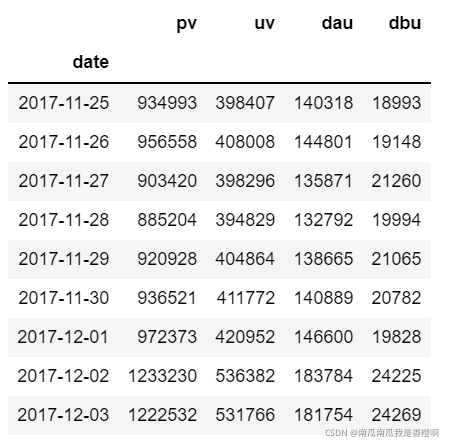
根据数据集内容,本次分析的流量类绝对指标主要包括以下4项:
- 每日PV(Page View):当天淘宝APP页面的浏览量或者点击量;
- 每日UV(Unique Visitor):当天进入淘宝APP的用户数量(需要去重);
- 每日活跃用户数DAU:在这里定义当天在淘宝APP上产生3次及以上行为数据的用户数量(需要去重);
- 每日支付用户数:当天在淘宝APP上产生购买行为(buy)的用户数量(需要去重)。
# 每日pv
daily_pv = dt[dt["behavior_type"]=="pv"][["user_id","date"]].groupby("date").count()
daily_pv.rename(columns={"user_id":"pv"},inplace=True)
# 每日uv
daily_uv = dt[["user_id","date"]].groupby("date").nunique()#按照date分组,统计每组中不同userid的个数
daily_uv = daily_uv.drop("date",axis=1)
daily_uv = daily_uv.rename(columns={"user_id":"uv"})
# 每日活跃用户:当天用户行为超过2次,则视为活跃
daily_active = dt[["user_id","behavior_type","date"]].groupby(["date","user_id"]).count()
dau = daily_active[daily_active["behavior_type"]>2]#筛选出行为数大于2的数据:日期|用户id|行为数
dau = dau.count(level=0)#根据日期,计数用户id
dau.rename(columns={"behavior_type":"dau"},inplace=True)
# 每日支付用户
dbu = dt[dt["behavior_type"]=="buy"]#筛选出支付的数据
dbu = dbu[["user_id","date","behavior_type"]].groupby(["date","user_id"]).count()#计数每天每个用户的支付行为数
dbu = dbu.count(level=0)#根据日期,计数用户id
dbu.rename(columns={"behavior_type":"dbu"},inplace=True)
# 合并数据
df_flow = daily_pv.join([daily_uv,dau,dbu])
df_flow
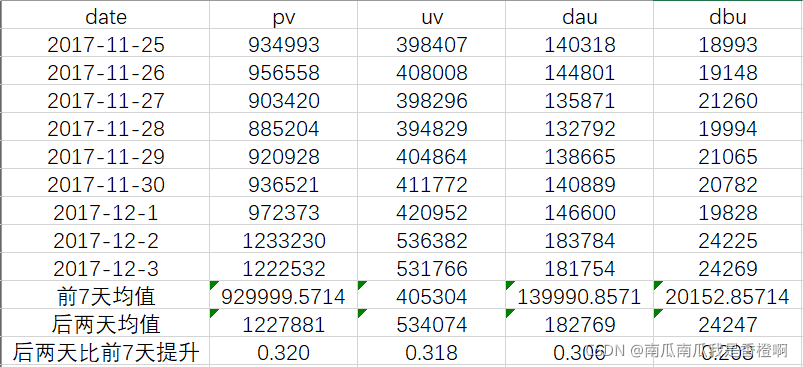
计算提升百分比:
使用matplolib绘制折线图:
plt.figure(figsize=(10,4),dpi=200) # 设置图的尺寸大小(10,4),200像素
plt.subplot(111,facecolor="#F0F0F0")#第一行,第一列,索引值
plt.xlabel("日期",fontsize=10)
plt.ylabel("单位/万",fontsize=10)
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.title("流量类绝对指标",fontsize=14)
plt.grid(axis="x")
plt.plot(df_flow["pv"]/10000,linewidth = '2',marker="o",color="#00868B",label="pv")
plt.plot(df_flow["uv"]/10000,linewidth = '2',marker="o",color="#ff5338",label="uv")
plt.plot(df_flow["dau"]/10000,linewidth="2",marker="o",color="#fe8c00",label="活跃用户")
plt.plot(df_flow["dbu"]/10000,linewidth="2& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6371
6371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









