







高并发:1.提升单个机器性能或者web的性能;2.部署多服务进行支撑。
高可用:1. 冗余;2. 故障转移(感知,监控)
技术手段:集群(redis哨兵模式;);keepalived存活探测
Nginx反向代理水平扩展&高可用分析
如果nginx不够用,可以DNS负载均衡方式配置同一个域名解析出多个IP,理论上无限制扩展。
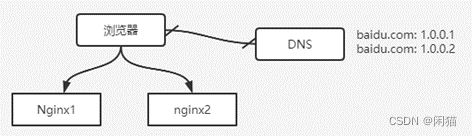
高可用分析:DNS服务器和Nginx压根就是两个服务,没法进行故障感知。如果这么配置那么01服务好不好都会解析返回。要高可用就得给nginx1冗余一台nginx1_1,但对外展示的IP都是1.0.0.1。技术就是使用VirtualIP虚拟一个IP,使用KeepAlived探测nginx可用性,如果nginx1挂掉了,自动访问nginx1_1。

网关水平扩展&高可用分析
可以在nginx.conf中配置多个server,并且配置负载均衡规则。nginx可以探测后面server可用性,理论上可以添加无限server,但局限于nginx的吞吐量。

高可用分析:nginx可以探测到tomcat是否好使,如果不好使就不在转发请求到此服务。
服务水平扩展&高可用分析
服务间调用,都是通过RPC方式调用,为了解耦调用方和背调方,独立出配置中心,调用和被调都注册到配置中心如Zookeeper,Eureka,Nacos等,配置中心
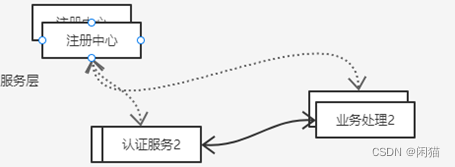
高可用分析:服务之间RCP的调用client会轮训访问ProductIP地址,如果访问不同就访问下一个Server,并有专门的后台线程和注册中心同步ProducerServerIP列表。
数据缓存高并发&高可用分析
缓存使用最广的是redis,mongodb,rockermq组件,组件都用自己集群以及保障措施。
数据库水平扩展&高可用分析
DB扩展分为一下集中:
- 业务上将比较内聚的数据拆分到另一个库
- 是架构上拆分的方式,不能动态扩展
- 三个月内订单数据和历史订单数据 放在不同的库中
- 冷热数据需要迁移过程
- 理论上三个月内订单量也会超一个数据库容量的,这种法子就失效了
- 根据订单的地点路由到不同的数据库
- 是上面第二种的变形
- 不需要进行数据迁移,但北京一个地区的数据也会超,这就不好使了
- 只是根据ID进行Hash计算,尽可能平均分配到不同DB
- 不怎么可行,存储数据没问题,访问呢?你并不知道数据在那个数据库,所以这种不现实
- 根据读写属性拆分为读库和写库
- 写到主库,从库读取数据
- 读并发高的话,可以上几个Slave支持
- 对多salve从库读取,如果一个从库宕机,druid连接池会探测到并获取其他连接进行访问
- 写库 是有一个主库,这就需要冗余了。
高可用分析:单几点Mysql是不满足高可用需求的,需要冗余一台机器。类似nginx高可用一样,使用virtualIP+KeepAlived来探测和故障转移,需要注意的我两台Mysql服务器可能存在数据同步差。
END
















 3006
3006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











