







 本文详细介绍了Kubernetes调度框架的工作流程,包括队列排序、过滤、评分等扩展点,并展示了如何编写调度插件。通过示例展示了如何实现一个判断Pod调度到GPU节点的插件。此外,还提供了处理依赖问题的脚本,以及配置和部署自定义调度器的步骤。测试结果显示,插件能有效控制Pod调度到具有特定标签的节点。
本文详细介绍了Kubernetes调度框架的工作流程,包括队列排序、过滤、评分等扩展点,并展示了如何编写调度插件。通过示例展示了如何实现一个判断Pod调度到GPU节点的插件。此外,还提供了处理依赖问题的脚本,以及配置和部署自定义调度器的步骤。测试结果显示,插件能有效控制Pod调度到具有特定标签的节点。
调度框架介绍
调度框架是面向 Kubernetes 调度器的一种插件架构, 它为现有的调度器添加了一组新的“插件” API。插件会被编译到调度器之中。 这些 API 允许大多数调度功能以插件的形式实现,同时使调度“核心”保持简单且可维护。
框架工作流程
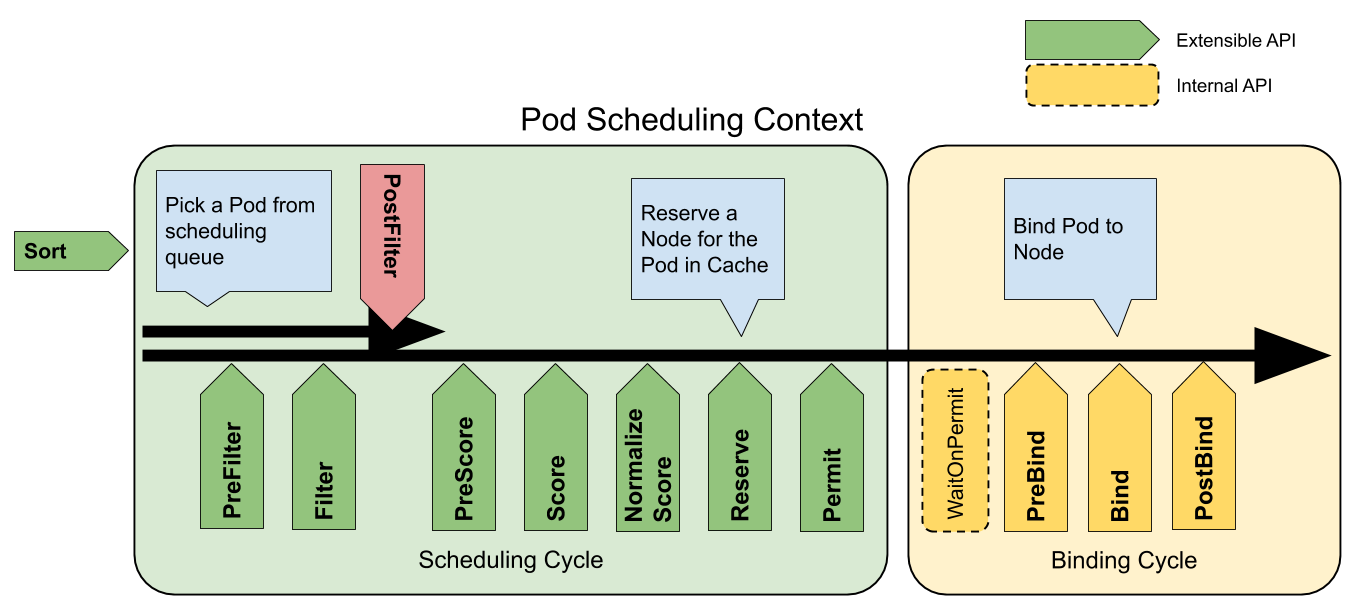
调度框架定义了一些扩展点。调度器插件注册后在一个或多个扩展点处被调用。 这些插件中的一些可以改变调度决策,而另一些仅用于提供信息。每次调度一个 Pod 的尝试都分为两个阶段,即 调度周期 和 绑定周期。
调度周期和绑定周期
调度周期为 Pod 选择一个节点,绑定周期将该决策应用于集群。 调度周期和绑定周期一起被称为“调度上下文”。调度周期是串行运行的,而绑定周期可能是同时运行的。如果确定 Pod 不可调度或者存在内部错误,则可以终止调度周期或绑定周期。 Pod 将返回队列并重试。
扩展点
以下为可以可扩展的11个扩展点,需要在哪个阶段自定义一些操作,就根据自己的需求实现哪个阶段的扩展点即可
源码在kubernetes@v1.21.2/pkg/scheduler/framework/interface.go
//插件的名字,必须实现此接口
type Plugin interface {
Name() string
}1. 队列排序 QueueSort
//队列排序插件用于对调度队列中的 Pod 进行排序。 队列排序插件本质上提供 less(Pod1, Pod2) 函数。 一次只能启动一个队列插件。
type QueueSortPlugin interface {
Plugin
Less(*QueuedPodInfo, *QueuedPodInfo) bool
}
//比较pod的优先级
type LessFunc func(podInfo1, podInfo2 *QueuedPodInfo) bool2. 前置过滤 PreFilter
//前置过滤插件用于预处理 Pod 的相关信息,或者检查集群或 Pod 必须满足的某些条件。 如果 PreFilter 插件返回错误,则调度周期将终止。
type PreFilterPlugin interface {
Plugin
PreFilter(ctx context.Context, state *CycleState, p *v1.Pod) *Status
PreFilterExtensions() PreFilterExtensions
}
type EnqueueExtensions interface {
EventsToRegister() []ClusterEvent
}
type PreFilterExtensions interface {
AddPod(ctx context.Context, state *CycleState, podToSchedule *v1.Pod, podInfoToAdd *PodInfo, nodeInfo *NodeInfo) *Status
RemovePod(ctx context.Context, state *CycleState, podToSchedule *v1.Pod, podInfoToRemove *PodInfo, nodeInfo *NodeInfo) *Status
}3. 过滤 Filter
//过滤插件用于过滤出不能运行该 Pod 的节点。对于每个节点, 调度器将按照其配置顺序调用这些过滤插件。如果任何过滤插件将节点标记为不可行, 则不会为该节点调用剩下的过滤插件。节点可以被同时进行评估。
type FilterPlugin interface {
Plugin
Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status
}4. 后置过滤
//这些插件在筛选阶段后调用,但仅在该 Pod 没有可行的节点时调用。 插件按其配置的顺序调用。
//如果任何后过滤器插件标记节点为“可调度”, 则其余的插件不会调用。典型的后筛选实现是抢占,
//试图通过抢占其他 Pod 的 资源使该 Pod 可以调度。
type PostFilterPlugin interface {
Plugin
PostFilter(ctx context.Context, state *CycleState, pod *v1.Pod, filteredNodeStatusMap NodeToStatusMap) (*PostFilterResult, *Status)
}5. 前置评分
//前置评分插件用于执行 “前置评分” 工作,即生成一个可共享状态供评分插件使用。 如果 PreScore 插件返回错误,则调度周期将终止。
type PreScorePlugin interface {
Plugin
PreScore(ctx context.Context, state *CycleState, pod *v1.Pod, nodes []*v1.Node) *Status
}6. 评分
//评分插件用于对通过过滤阶段的节点进行排名。调度器将为每个节点调用每个评分插件。
//将有一个定义明确的整数范围,代表最小和最大分数。
//在标准化评分阶段之后,调度器将根据配置的插件权重 合并所有插件的节点分数。
type ScorePlugin interface {
Plugin
Score(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) (int64, *Status)
ScoreExtensions() ScoreExtensions
}
type ScoreExtensions interface {
NormalizeScore(ctx context.Context, state *CycleState, p *v1.Pod, scores NodeScoreList) *Status
}7. Reserve
//这是一个信息扩展点,当资源已经预留给 Pod 时,会通知插件。 管理运行时状态的插件(也成为“有状态插件”)应该使用此扩展点,以便 调度器在节点给指定 Pod 预留了资源时能够通知该插件。 这是在调度器真正将 Pod 绑定到节点之前发生的,并且它存在是为了防止 在调度器等待绑定成功时发生竞争情况。
//这个是调度周期的最后一步。 一旦 Pod 处于保留状态,它将在绑定周期结束时触发不保留 插件 (失败时)或 绑定后 插件(成功时)。
type ReservePlugin interface {
Plugin
Reserve(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) *Status
Unreserve(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string)
}8. PreBind
//这些插件在 Pod 绑定节点之前执行
type PreBindPlugin interface {
Plugin
PreBind(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) *Status
}9. PostBind
//这是一个信息扩展点,在 Pod 绑定了节点之后调用。
type PostBindPlugin interface {
Plugin
PostBind(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string)
}10. Permit
// 这些插件可以阻止或延迟 Pod 绑定, 一个允许插件可以做以下三件事之一:
//批准:一旦所有 Permit 插件批准 Pod 后,该 Pod 将被发送以进行绑定。
//拒绝:如果任何 Permit 插件拒绝 Pod,则该 Pod 将被返回到调度队列。 这将触发Unreserve 插件。
//等待(带有超时):如果一个 Permit 插件返回 “等待” 结果,则 Pod 将保持在一个内部的 “等待中” 的 //Pod 列表,同时该 Pod 的绑定周期启动时即直接阻塞直到得到 批准。如果超时发生,等待 变成 拒绝,并且 Pod 将返回调度队列,从而触发 Unreserve 插件。
type PermitPlugin interface {
Plugin
Permit(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) (*Status, time.Duration)
}11. Bind
// 这个插件将 Pod 与节点绑定。绑定插件是按顺序调用的,只要有一个插件完成了绑定,其余插件都会跳过。绑定插件至少需要一个。
type BindPlugin interface {
Plugin
Bind(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) *Status
}官方有给出demo
https://github.com/kubernetes-sigs/scheduler-plugins
仿照官方的demo实现一个小功能,比如在调度的时候需要判断将pod调度到label为gpu=true的节点
Demo
注册
package main
import (
"k8s.io/kubernetes/cmd/kube-scheduler/app"
"math/rand"
"os"
my_scheduler "sche/my-scheduler"
"time"
)
func main() {
rand.Seed(time.Now().UnixNano())
// 注册,可以注册多个
command := app.NewSchedulerCommand(
app.WithPlugin(my_scheduler.Name, my_scheduler.New),
// app.WithPlugin(my_scheduler2.Name, my_scheduler2.New),
)
if err := command.Execute(); err != nil {
os.Exit(1)
}
}实现
package my_scheduler
import (
"context"
"k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/kubernetes/pkg/scheduler/framework"
"log"
)
const Name = "sample"
type sample struct{}
// ide(goland)可以自动识别要实现的接口长啥样,implement missing method会一键创建对应方法
var _ framework.FilterPlugin = &sample{}
var _ framework.PreScorePlugin = &sample{}
/**
根据k8s版本,此处可能有些许不同
经测试在1.19版本需要如此导入framework包
framework "k8s.io/kubernetes/pkg/scheduler/framework/v1alpha1"
New函数为
func New(_ *runtime.Object, _ framework.FrameworkHandle) (framework.Plugin, error) {
return &Sample{}, nil
}
*/
func New(_ runtime.Object, _ framework.Handle) (framework.Plugin, error) {
return &sample{}, nil
}
// 必须实现
func (pl *sample) Name() string {
return Name
}
func (pl *sample) Filter(ctx context.Context, state *framework.CycleState, pod *v1.Pod, node *framework.NodeInfo) *framework.Status {
log.Printf("filter pod: %v, node: %v", pod.Name, node)
// 如果节点的label不包含gpu=true,返回不可调度
if node.Node().Labels["gpu"] != "true" {
return framework.NewStatus(framework.Unschedulable, "Node: "+node.Node().Name)
}
return framework.NewStatus(framework.Success, "Node: "+node.Node().Name)
}
func (pl *sample)PreScore(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodes []*v1.Node) *framework.Status {
// 没做具体实现,此处只为演示,只做打印
log.Println(nodes)
log.Println(pod)
return framework.NewStatus(framework.Success, "Pod: "+pod.Name)
}打包镜像
FROM ubuntu:18.04
ADD sche /usr/bin/
RUN chmod a+x /usr/bin/sche
CMD ["sche"]问题
k8s下载依赖包的一些问题
直接go mod init xx
然后go mod tidy
会出现unknown revision v0.0.0问题,可用以下脚本解决
#!/bin/sh
set -euo pipefail
VERSION=${1#"v"}
if [ -z "$VERSION" ]; then
echo "Must specify version!"
exit 1
fi
MODS=($(
curl -sS https://raw.githubusercontent.com/kubernetes/kubernetes/v${VERSION}/go.mod |
sed -n 's|.*k8s.io/\(.*\) => ./staging/src/k8s.io/.*|k8s.io/\1|p'
))
for MOD in "${MODS[@]}"; do
V=$(
go mod download -json "${MOD}@kubernetes-${VERSION}" |
sed -n 's|.*"Version": "\(.*\)".*|\1|p'
)
go mod edit "-replace=${MOD}=${MOD}@${V}"
done
go get "k8s.io/kubernetes@v${VERSION}"使用方法为:
go mod init xxx
bash mod.sh v1.19.2 // 假设上面的脚本保存为mod.sh 需要的k8s版本为1.19.2
插件配置
集群开启了RBAC,所以需要给权限,然后通过configmap的方式将配置文件传给自定义的scheduler,使用一个deployment将自定义的scheduler运行起来
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: sample-scheduler-clusterrole
rules:
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs:
- get
- update
- create
- apiGroups:
- ""
resources:
- endpoints
verbs:
- delete
- get
- patch
- update
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: sample-scheduler-sa
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: sample-scheduler-clusterrolebinding
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: sample-scheduler-clusterrole
subjects:
- kind: ServiceAccount
name: sample-scheduler-sa
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: scheduler-config
namespace: kube-system
data:
scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
clientConnection:
kubeconfig: "/etc/kubernetes/ssl/kubecfg-kube-scheduler.yaml"
profiles:
- schedulerName: sample-scheduler # 新的调度器的名字,随便取
plugins:
filter: # 表示在filter这个扩展点
enabled: # 开启
- name: sample # sample这个插件定义的filter,同时还会执行默认的插件的filter
preScore:
enabled:
- name: sample
disabled: #禁用
- name: "*" # 表示禁用默认的preScore,只使用sample的preScore,除了默认的调度器,其他扩展的调度器必须显示enable才会执行,默认的调度器必须显示disabled才会不执行
# 注意:所有配置文件必须在 QueueSort 扩展点使用相同的插件,并具有相同的配置参数(如果适用)。 这是因为调度器只有一个保存 pending 状态 Pod 的队列。意思要么用默认的queueSort不用扩展的queueSort,要么用扩展的queueSort,把默认的queueSort禁用掉
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-scheduler
namespace: kube-system
labels:
component: sample-scheduler
spec:
replicas: 1
selector:
matchLabels:
component: sample-scheduler
template:
metadata:
labels:
component: sample-scheduler
spec:
hostNetwork: true
serviceAccount: sample-scheduler-sa
priorityClassName: system-cluster-critical
volumes:
- name: scheduler-config
configMap:
name: scheduler-config
- name: kubeconfigdir
hostPath:
path: /etc/kubernetes/ssl # 本地的scheduler-config文件所在位置,在我的环境中该文件名为kubecfg-kube-scheduler.yaml,挂载到deployment内供deployment用到的configmap使用
type: DirectoryOrCreate
containers:
- name: scheduler-ctrl
image: sche:v1
imagePullPolicy: IfNotPresent
args:
- /usr/bin/sche
- --config=/etc/kubernetes/scheduler-config.yaml # configmap挂载的文件
- --v=3
resources:
requests:
cpu: "50m"
volumeMounts:
- name: scheduler-config
mountPath: /etc/kubernetes
- name: kubeconfigdir
mountPath: /etc/kubernetes/ssl
readOnly: true测试
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-example
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
schedulerName: sample-scheduler # 使用自定义的scheduler,如果不指定则会使用默认的scheduler
containers:
- name: nginx
image: nginx调度时可使用kubectl logs查看sample-scheduler的日志
在未给节点打上gpu=true时,pod一直处于pending状态,当打上标签之后pod成功调度
未完成事项
官方文档中有以下一段:
要在启用了 leader 选举的情况下运行多调度器,你必须执行以下操作:
首先,更新上述 Deployment YAML(my-scheduler.yaml)文件中的以下字段:
- --leader-elect=true
- --lock-object-namespace=<lock-object-namespace>
- --lock-object-name=<lock-object-name>
配置之后pod无法调度,日志中立即打印Add event for unscheduled pod,只有在scheduler-config.yaml中
leaderElection:
leaderElect: false设置为false的时候能成功调度

















 536
536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









