







Aho-Corasic多模匹配算法的学习、理解和应用(Python环境下)
Aho-Corasic算法Python使用官方教程
pyahocorasick官方教程:https://pyahocorasick.readthedocs.io/en/latest/#automaton-class
Aho-Corasic算法的定义及功能
Aho-Corasick算法的定义:
Aho-Corasick(简称为AC自动机),是一种基于前缀的,使用了确定有限自动机(DFA)原理的,字符串多模匹配算法。
什么是DFA?
\quad
DFA也就是 确定有限自动机,英文全称是Deterministic Finite Automaton。
\quad
具体的细节介绍,可以参照百度百科、维基百科,以及《算法导论》之类的算法书。在这里,我们尝试用通俗的语言和图示来解释一遍。
\quad
我们一个一个字母的来解释DFA的含义。
\quad
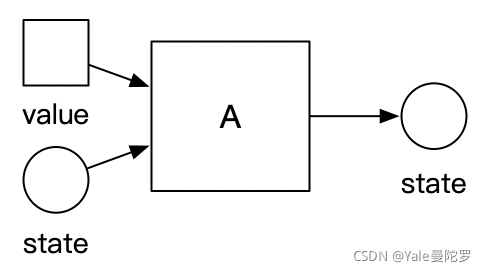
首先, 什么是自动机(A)。自动机就是一个代码块。这段代码块只做一件事,那就是接收输入值和状态值,输出同为状态值的结果。用图示来表述,就是下面这样:
其次,下一个字母—— 有限(F),是指自动机接收、输入的状态种类是有限的。而相对应的,非有限自动机的状态就是有无限种的。
\quad
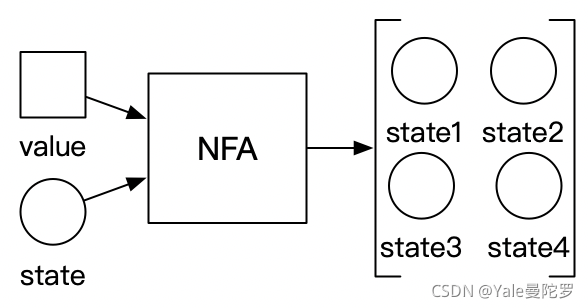
再者,下一个字母—— 确定的(D),是指自动机的输出状态是单一的一个状态。如果不太好理解的话,那就是看一下对应的非确定自动机。这种自动机的输出状态,就不是单一的,而是许多个状态的集合。用图示来表述,就是下面这样:
\quad
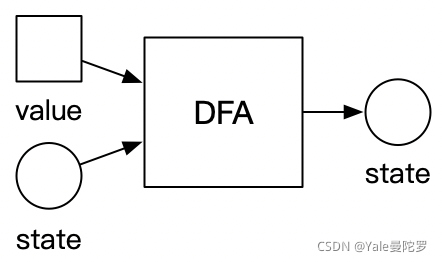
有限自动机的状态图示例:
非有限自动机的状态图示例:
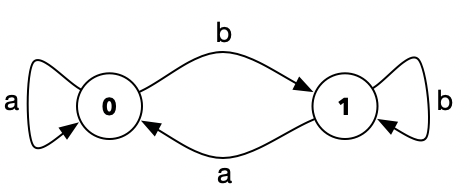
所以三个字母合起来以后, DFA 的意思就像英文全称一样了, 是一种状态值种类有限,且返回结果单一的自动机。 举个简单的代码例子:
上面的这段代码,其内部的状态转化逻辑,可以用图示(也就是所谓的状态转化图)表示:
而更加复杂的自动机状态转化图,可以参照下面这张截取自百度百科的图示:
上述内容原始出处:算法学习之Aho-Corasick,感谢博主分享。

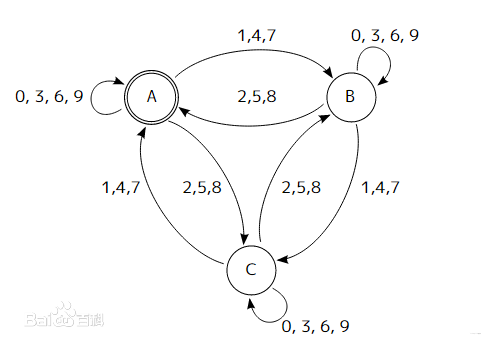
Aho-Corasick算法的功能:
Aho-Corasick的核心功能是实现字符串多模匹配。比如:现在有个大的列表,客户输入一句话,如何根据客户输入的一句话,从大列表中匹配出字符串交集。
Aho-Corasic算法的基本原理
Tire Tree的由来:
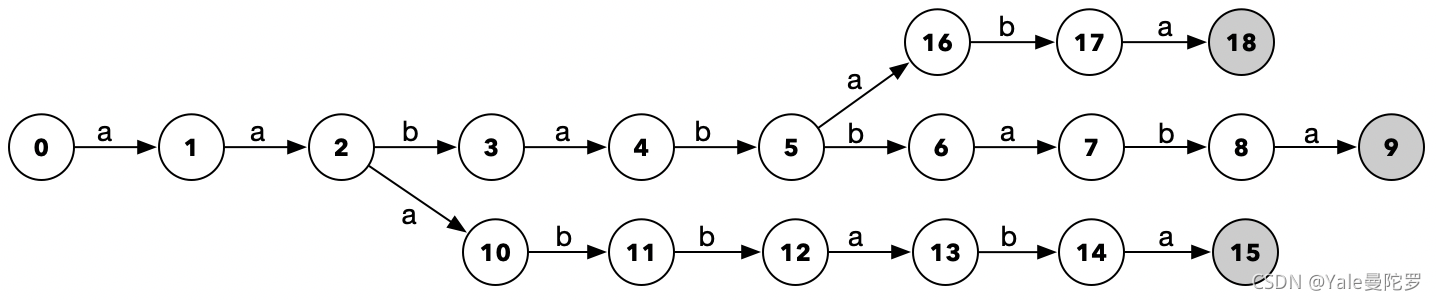
上一节对DFA进行了介绍,那么现在实际操作一把,构建一个DFA状态转化图,使得输入下面三条字符串以后,都能得到终点态: aababbaba、aaabbaba、aabababa
我们先用纸笔画一画,会得到下面这样的状态转化图:

状态转化图过程分析:
\quad
状态0为初始态,状态9为终点态。虽然可能不是十分完善,但我们输入上面那三条字符串的任意一条,都能成功的得到终点态9。那么既然能用纸笔画出来,我们就能用代码实现出来。大致构想一下代码的数据结构和逻辑,应该是下面这样:
- 首先,数据结构应该是使用链表来表示每个节点
- 其次,
代码逻辑大致有下面这几步:
2.1 接收输入的字符,判断是否和当前状态所在节点的字符内容相同;
2.2 如果不同,或者当前状态节点为初始态节点,则为本次输入字符新建节点。然后将当前状态所在节点的next指针,指向新建的节点;
2.3 如果相同,则略过本次输入,跳转至步骤2.1接收下一个字符;
\quad我们按照这样的逻辑实现了以后,输入上面那三条字符串,会发现得到的结果,跟我们用纸笔画出的状态转化图不一样,而是像下面这样:
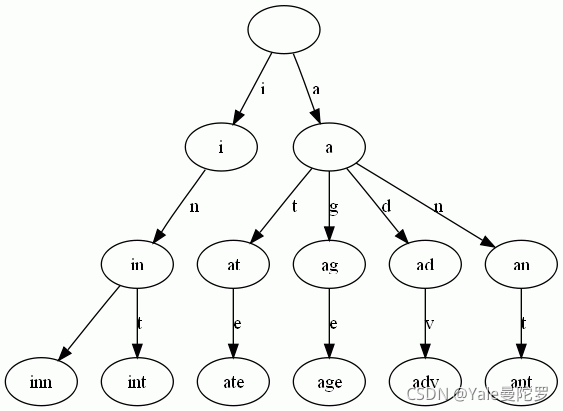
跟我们用纸笔画出来的图示,区别在于变成了树状的分叉结构。而这种我们无意之间得到的树状分叉结构,只要把状态节点,换成对应的输入字符内容,就是 Tire Tree 了,也叫做 单词查找树。
可以看出:
- 每条边对应一个字母。
- 每个节点对应一项前缀。叶节点对应最长前缀,即单词本身。
- 单词inn与单词int有共同的前缀“in”, 因此他们共享左边的一条分支,root->i->in。同理,ate, age, adv, 和ant共享前缀"a",所以他们共享从根节点到节点"a"的边。
- 查询操纵非常简单。比如:要查找int,顺着路径i -> in -> int就找到了。
更加详细的介绍,可以参照算法书及各种百科和帖子。不过在这里,我们关注的重点是,Tire Tree和DFA的关系。
Aho-Corasick算法原理:
按照上一节中生成Tire Tree类似结构DFA的代码设计,我们输入下面这三条字符串: his、hers、she。可以得到下面这样的状态转化图:
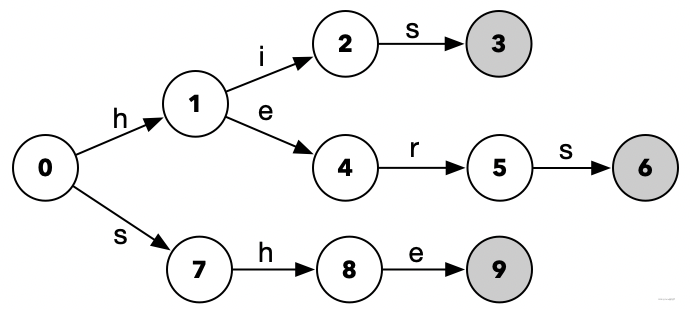
观察这个状态转化图,我们发现可以拿来做字符串匹配。比如:我们输入这样一段内容: hisdef,当输入了s以后,我们就得到了终点态,所以我们可以判定当前字符串内包含有his。
\quad
可是,如果我们输入的是abchisdef呢?想要得到终点态,就得略过前面的abc。那如果我们输入的是shis呢?匹配she的时候匹配一半,就得切换到对his的匹配。因此,我们发现需要对这种状态树做一点改进。
相较于Tire Tree而言,Aho-Corasick算法引入Fail路径(失败路径)进行算法优化。
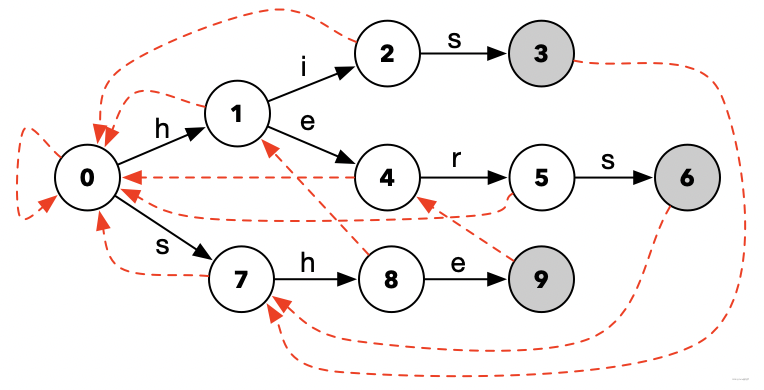
还是用上面的his、hers、she做例子,添加了红色虚线Fail路径的状态转化图,像下面这样:
这些红色的Fail路径,就是 如果我们输入的字符内容,无法使状态值,从当前状态节点,跳转到下一个预定的状态节点时,我们就通过Fail路径,回溯到前面的某一个状态节点。
\quad
例如:正常情况下的跳转动作是这样的: f(1, i) = 2。而当我们的输入值不是1和i的时候,就无法得到2了。此时,得到的则是0,即f(1, x) = 0。
Aho-Corasick算法——如何构建Fail路径?
我们先看下该怎样构建Fail路径。一言概之: Fail路径,就是指向另一个,可以作为某一范式前缀的节点。 Fail路径的构建逻辑,可以分解成下面这几步:
- 如果自己是根节点,则其Fail路径指向自己;
- 如果自己的父节点是根节点,则其Fail路径仍指向根节点;
- 找到
自己父节点Fail路径指向的节点,执行如下操作:
(1)如果自己父节点Fail路径指向的节点可以正常接收自己的输入字符,那么就指向这个节点接收自己输入字符后,所指向的那个节点;
(2)如果自己父节点Fail路径指向的节点不能正常接收自己的输入字符,就按照第3步的判断,检查自己父节点的父节点的Fail路径指向的节点; - 依次递推,一直父节点、父节点、父节点这样的回溯,如果直到回溯至根节点还没找到的话,那么其Fail路径就指向根节点;
Aho-Corasick算法——构建Fail路径的典型范例:
\quad
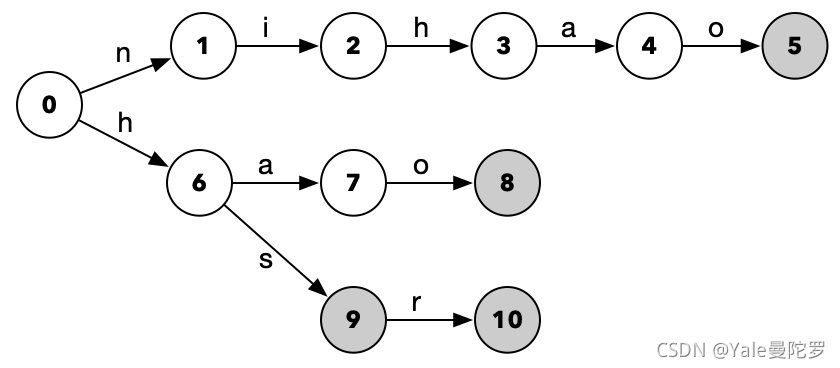
例如:通过字符串nihao、hao、hs、hsr得到的状态转化图是下面这样:
接下来,我们按照上面说的步骤来,一步一步分析nihao、hao、hs、hsr例子得到的状态转化图。
- 首先是0节点,因为是根节点,所以就指向了它自己,也就是0 -> 0
- 然后是1节点,1节点的父节点是0节点也就是根节点,所以指向0节点,也就是1 -> 0
- 由于2节点的父节点是1节点,1节点的Fail路径指向了0节点。那么因为0节点,不能正常接收2节点的输入字符也就是i,所以我们继续回溯去看2节点的父节点的父节点,也就是0节点。这时,因为已经回溯到了根节点,所以按照逻辑,我们只能最终确定指向0,也就是2 -> 0
- 由于3节点的父节点是2节点,2节点的Fail路径指向了0节点。那么因为0节点,可以正常接收3节点的输入字符也就是h,所以3节点就应该指向,0节点接收了h后指向的节点,也就是6。所以最终,我们得到3 -> 6
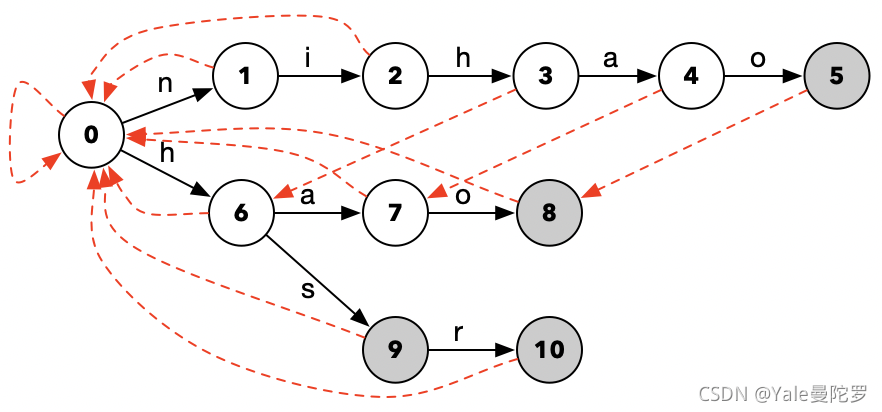
\quad依照上述原理,添上Fail路径后的状态转化图如下:
Aho-Corasick算法——如何进行状态跳转?
正常路径的跳转很简单,我们主要关注Fail路径跳转。和其文本含义一样,即当正常路径失败时,就通过Fail路径跳转。
Aho-Corasick算法——状态节点间的跳转逻辑
- 如果当前这个节点,可以正常接收输入值,那么就跳转到输入值对应的下一个节点,本轮跳转结束,接收下一个输入值以进入下一轮跳转;
- 如果当前这个节点,不能正常接收输入值,那么就先跳转到自己Fail路径指向的节点,然后再尝试执行第一步;
- 如果现在已经跳转回到了根节点,那么先尝试第一步,如果失败,则就不再执行第二步,而是停留在根节点了,本轮跳转结束,接收下一个输入值以进入下一轮跳转。
典型范例:
\quad
还是使用his、hers、she的状态转化图来举个例子,当我们输入字符串ushhis时,详细的跳转步骤是下面这样的:
- 当前状态0,输入u,无法正常跳转,进入Fail路径,到达状态0
- 当前状态0,输入s,可以正常跳转,到达状态7
- 当前状态7,输入h,可以正常跳转,到达状态8
- 当前状态8,输入h,无法正常跳转,进入Fail路径,到达状态1
- 当前状态1,输入i,可以正常跳转,到达状态2
- 当前状态2,输入s,可以正常跳转,到达状态3
当我们执行到上面的第八步时,我们发现状态3是一个终点态。所以,我们可以判定,此时我们找到了
范式his。
Aho-Corasick算法——如何得到匹配结果?
匹配结果由两部分组成:
- 每轮跳转结束后,所停留在的节点,如果是终点态,则该节点对应的模式串匹配成功;
- 从停留的节点开始,一路沿Fail路径递归至根节点,期间路过的所有的节点,只要是终点态节点,则该节点对应的模式串也就匹配成功。
典型范例:
\quad
用nihao、hao、hs、hsr的状态转化图举例。
- 如果经过跳转后,停留在节点5,那么因为节点5是终点态,所以,节点5对应的模式串nihao就匹配成功了。
- 然后我们沿着Fail路径递归至节点8,因为节点8也是终点态,所以节点8对应的模式串hao也匹配成功了。再继续沿着Fail路径递归,这时候我们到了根节点,那么至此,这一轮匹配结束。
Aho-Corasic算法中构建Fail路径的意义
为了解释这个问题,让我们回到本文最开始的位置。在第一节中,我们用一句话解释了什么是Aho-Corasick算法,而那句话中的“基于前缀的”这五个字,就是答案。
在构建Fail路径过程中,我们反复的回溯,其实就是在试图拓展上一步找到的前缀,而得到此范式的更长前缀。
在我们使用Fail路径跳转的时候,我们发现,Fail路径所指向的节点,其所在的正常状态节点链上,从根节点开始,到该节点为止,每个节点组成的字符串,必定是某一个范式的前缀。
例如:由his、hers、she所组成的状态转化图里,节点9的Fail节点,指向了节点4。那么在节点4所在的这条状态节点链上,从根节点0开始,到节点4为止,一共0、1、4三个节点所组成的字符串是he,而he就是hers范式的前缀。
参考链接:算法学习之Aho-Corasick
Aho-Corasic算法的Python调用
ahocorasick.Automaton()函数介绍
import ahocorasick # 导入ahocorasick模块
A = ahocorasick.Automaton() # 建树create an Automaton
# You can use the Automaton class as a trie.(即:将A看做trie)
for idx, key in enumerate('he her hers she'.split()): # str.split()去除字符串收尾的空格
A.add_word(key, (idx, key)) # 此处,我们将 (idx, key)作为与key关联的value,添加到刚建的树Automaton中
A.make_automaton() # 现在将trie(即:A)转换为Aho Corasick自动机以启用Aho Corasick搜索
# 补充用法说明:
# Then check if some string exists in the trie:
>>> 'he' in A
True
>>> 'HER' in A
False
# And play with the get() dict-like method:
>>> A.get('he') # 使用get函数来获取匹配到的key,如果匹配到输入Word,则返回对应于key的(idx, key)
(0, 'he')
>>> A.get('she')
(3, 'she')
>>> A.get('cat', 'not exists') # 使用get函数来获取匹配到的key,如果未匹配到输入Word,则指定返回值为“not exists”;
'not exists'
>>> A.get('dog') # 使用get函数来获取匹配到的key,如果未匹配到输入Word,且未指定匹配失败返回值,则直接报错;
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError
You can use the Automaton class as a trie. Add some string keys and their associated value to this trie. Here we associate a tuple of (insertion index, original string) as a value to each key string we add to the trie:
The Automaton.iter() method return the results as two-tuples of the end index where a trie key was found in the input string and the associated value for this key.Here we had stored as values a tuple with the original string and its trie insertion order:

Automaton.iter() 方法的返回结果为一个二元组,它由2部分构成:(1)input字符串所匹配到的key的结束索引;(2)所匹配到的key的关联value【(insertion index, original string)】
haystack = 'heissgirlsheissboy'
for end_index, (insert_order, original_value) in A.iter(haystack):
start_index = end_index - len(original_value) + 1 # 通过input字符串所匹配到的key的结束索引推算开始索引
print((start_index, end_index, (insert_order, original_value)))
assert haystack[start_index:start_index + len(original_value)] == original_value # assert语句用来声明某个条件是真的。
>>>
(0, 1, (0, 'he'))
(9, 11, (3, 'she'))
(10, 11, (0, 'he'))
二、示例
比如我们有一个wordlist列表,长度很长,包含43430个元素:
['长春海外制药接骨续筋片', '香菇炖甲鱼', '三鹤药业黄柏胶囊', '上海衡山熊去氧胆酸片', '升和药业依托泊苷注射液', '怡诺思', '人格障碍', '转铁蛋白饱和度', '脾囊肿', '素烧白萝卜', '利君现代冠脉宁片',
'上海复华药业注射用还原型谷', '阴囊上有白色小疙瘩', '腹痛伴休克', '成都通德胰激肽原酶肠溶片', '蒸猪肝', '河北百善血尿胶囊', '精神障碍', '输卵管畸形', '元和抑眩宁胶囊', '莲藕豆腐', '辰欣哈西奈德溶液',
'信谊烟酸片', '慢性胆囊炎', '参芪降糖颗粒', '康普药业盐酸普萘洛尔片', '西安迪赛胸腺肽肠溶片', '双鹭药业注射用复合辅酶', '慢性筛窦炎', '新高制药维胺酯维E乳膏', '冰黄肤乐软膏', '神经类疾病', '液晶热图',
'枣(干)', '股外侧皮神经病', '浙江惠松硅炭银片', '牙根外露', '湖北潜江氯霉素滴眼液', '盐类皮质激素分泌过多', '五子衍宗丸', '小儿阵发性睡眠性血红蛋白尿症', '功能失调性子宫出血病', '茵栀黄口服液',
'眼底出血和渗出', '斯达制药注射用头孢噻肟钠', '复方白芷酊', '胫腓骨骨折', '西南药业氯霉素片', '宫颈炎', '茶碱缓释胶囊', '原发性硬化性胆管炎', '郑州韩都利肺胶囊', '咽反射消失', '脊髓灰质炎',
'甲状腺片', '回盲瓣功能不全', '乙肝e抗体(抗...', '马齿苋粥', '动脉硬化', '宝宝乐', '肠闭锁', '肺放线菌病', '江苏晨牌产妇安颗粒', '犬吠样咳嗽', '胃康灵胶囊', '小儿烟酸缺乏病', '青龙防风通圣丸',
'广东南国维生素C片', '碘化油咀嚼片', '西乐葆', '伟哥甲磺酸酚妥拉明分散片', '成都迪康药业樟脑醑', '斑疹', '五花炖墨鱼', '肉炖芸豆粉条', '陕西东泰制药益脉康胶囊', '桔梗八味颗粒', '华南牌溴丙胺太林片',
'吉林敖东洮南小牛脾提取物注', '仁青芒觉', '血吸虫病与肝胆疾病',...,'持续性枕横位难产', '弯曲菌感染', '丝瓜蘑菇肉片汤', '长春银诺克清咽片', '肝叶萎缩', '迪皿盐酸左西替利嗪口服溶液']
index, (index, word)如下:
0 (0, '长春海外制药接骨续筋片')
1 (1, '香菇炖甲鱼')
2 (2, '三鹤药业黄柏胶囊')
3 (3, '上海衡山熊去氧胆酸片')
4 (4, '升和药业依托泊苷注射液')
5 (5, '怡诺思')
6 (6, '人格障碍')
7 (7, '转铁蛋白饱和度')
8 (8, '脾囊肿')
9 (9, '素烧白萝卜')
10 (10, '利君现代冠脉宁片')
......
43422 (43422, '弯曲菌感染')
43423 (43423, '丝瓜蘑菇肉片汤')
43424 (43424, '长春银诺克清咽片')
43425 (43425, '肝叶萎缩')
43426 (43426, '迪皿盐酸左西替利嗪口服溶液')
43427 (43427, '华润天和麝香壮骨膏')
43428 (43428, '湖北恒安曲咪新乳膏')
43429 (43429, '子宫小')
1. 建树
import ahocorasick
actree = ahocorasick.Automaton()
for index, word in enumerate(wordlist):
actree.add_word(word, (index, word))
actree.make_automaton()
#其中wordlist就是上面的那个长度为43430的列表
2. 快速匹配
for i in actree.iter('昨天发烧,服用了阿司匹林,并且还吃了牛黄清胃丸,饭是吃了瓜烧白菜,大便有点色浅'):
print(i)
这样客户输入一个字符串,我们能够快速的从之前的列表中匹配出相应的实体元素:

果然我们通过查看索引,与上图结果一致:

从结果上看,算法是根据客户输入,相当于遍历每个列表元素,来判断每个元素是否存在于客户输入中。
(效果似乎是这样,时间复杂度比较高,如果词库列表比较大,时间会更长,但是本质是采用了Aho-Corasic多模匹配算法以达到匹配的目的)
思考:
存在一个问题,从上面的客户输入看,客户输入了瓜烧白菜,但是匹配出了白菜和瓜烧白菜,我们从客户输入看,客户是想输入瓜烧白菜,白菜我们并不想匹配出来。
region_wds = []
for i in actree.iter('昨天发烧,服用了阿司匹林,并且还吃了牛黄清胃丸,饭是吃了瓜烧白菜,大便有点色浅'):
wd = i[1][1] # i形如(31, (13, '白菜')),所以通过i[1][1]切片出‘白菜’
print("wd:", wd)
region_wds.append(wd) # 将匹配到的Word添加到列表region_wds中
print("region_wds:",region_wds)
stop_wds = []
for wd1 in region_wds:
for wd2 in region_wds:
if wd1 in wd2 and wd1 != wd2:
print("w1:{},w2:{}".format(wd1,wd2))
stop_wds.append(wd1)
print("stop_wds:", stop_wds)
final_wds = [i for i in region_wds if i not in stop_wds] # 当欲匹配的wordlist中包含string和它的截断字符串组成的sub_string时(例如:此处'瓜烧白菜', '白菜'),剔除sub_string部分的匹配项。
print("final_wds:", final_wds)
>>>
wd: 发烧
wd: 阿司匹林
wd: 牛黄清胃丸
wd: 瓜烧白菜
wd: 白菜
w1:白菜,w2:瓜烧白菜
region_wds: ['发烧', '阿司匹林', '牛黄清胃丸', '瓜烧白菜', '白菜']
白菜 瓜烧白菜
stop_wds: ['白菜']
final_wds: ['发烧', '阿司匹林', '牛黄清胃丸', '瓜烧白菜']
根据 Automaton.iter() 方法的返回结果为一个二元组,它由2部分构成:(1)input字符串所匹配到的key的结束索引;(2)所匹配到的key的关联value【(insertion index, original string)】 可知:下面代码段中的二元组的第一个值3、11、22、31、31分别对应于input字符串所匹配到的key的结束索引(索引从0开始计数)。
for i in actree.iter('昨天发烧,服用了阿司匹林,并且还吃了牛黄清胃丸,饭是吃了瓜烧白菜,大便有点色浅'):
print(i)
>>>
(3, (24, '发烧'))
(11, (45, '阿司匹林'))
(22, (56, '牛黄清胃丸'))
(31, (1, '瓜烧白菜'))
(31, (13, '白菜'))
参考链接:
算法学习之Aho-Corasick
ahocorasick使用
python ahocorasick介绍
# coding:utf-8
import ahocorasick
def make_AC(AC, word_set):
for word in word_set:
AC.add_word(word, word)
return AC
def test_ahocorasick():
"""
ahocorasick:自动机的意思,可实现自动批量匹配字符串的作用,即可一次返回该条字符串中命中的所有关键词
"""
key_list = ["苹果", "香蕉", "梨", "橙子", "柚子", "火龙果", "柿子", "猕猴挑"]
# 建树
AC_KEY = ahocorasick.Automaton()
AC_KEY = make_AC(AC_KEY, set(key_list))
AC_KEY.make_automaton()
test_str_list = ['我最喜欢吃的水果有:苹果、梨和香蕉','我也喜欢吃香蕉,但是我不喜欢吃梨']
for content in test_str_list:
name_list = set()
# 将AC_KEY中每一项与content内容作比对,若匹配则返回
# 快速匹配
for item in AC_KEY.iter(content):
name_list.add(item[1])
name_list = list(name_list)
if len(name_list) > 0:
print(content, "---->命中的关键词有:",'\t'.join(name_list))
if __name__ == '__main__':
test_ahocorasick()
>>>
我最喜欢吃的水果有:苹果、梨和香蕉 ---->命中的关键词有: 梨 苹果 香蕉
我也喜欢吃香蕉,但是我不喜欢吃梨 ---->命中的关键词有: 梨 香蕉


















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











