







numpy升级cupy|cupy完整开发笔记|保姆级教学
大家好,这里是【来一块葱花饼】,这次带来了cupy的开发教学,与你分享~
numpy作为 Python 语言的一个扩展程序库,速度已经较 Python 有了很大的提升。CuPy 是一个借助 CUDA在英伟达 GPU 上实现 Numpy 数组的库,则可以更大幅度的提速。
文章目录
一.cupy介绍
1.numpy
作为 Python 语言的一个扩展程序库,Numpy 支持大量的维度数组与矩阵运算,为 Python 社区带来了很多帮助。借助于 Numpy,数据科学家、机器学习实践者和统计学家能够以一种简单高效的方式处理大量的矩阵数据。那么 Numpy 速度还能提升吗?本文介绍了如何利用 CuPy 库来加速 Numpy 运算速度。
就其自身来说,Numpy 的速度已经较 Python 有了很大的提升。当你发现 Python 代码运行较慢,尤其出现大量的 for-loops 循环时,通常可以将数据处理移入 Numpy 并实现其向量化最高速度处理。(numpy快:1.函数是经过优化的,肯定比直接的语句快。2.使用矩阵、向量,操作更快)
但有一点,上述 Numpy 加速只是在 CPU 上实现的。由于消费级 CPU 通常只有 8 个核心或更少,所以并行处理数量以及可以实现的加速是有限的。
参考链接:https://towardsdatascience.com/heres-how-to-use-cupy-to-make-numpy-700x-faster-4b920dda1f56
2.cupy
官网:https://docs.cupy.dev/en/stable/
这就催生了新的加速工具——CuPy 库。
何为 CuPy?

CuPy 是一个借助 CUDA GPU 库在英伟达 GPU 上实现 Numpy 数组的库。基于 Numpy 数组的实现,GPU 自身具有的多个 CUDA 核心可以促成更好的并行加速。
CuPy 接口是 Numpy 的一个镜像,并且在大多情况下,它可以直接替换 Numpy 使用。只要用兼容的 CuPy 代码替换 Numpy 代码,用户就可以实现 GPU 加速。
CuPy 支持 Numpy 的大多数数组运算,包括索引、广播、数组数学以及各种矩阵变换。
如果遇到一些不支持的特殊情况,用户也可以编写自定义 Python 代码,这些代码会利用到 CUDA 和 GPU 加速。整个过程只需要 C++格式的一小段代码,然后 CuPy 就可以自动进行 GPU 转换,这与使用 Cython 非常相似。
3.加速效果
数组大小(数据点)达到 1000 万,运算速度大幅度提升
使用 CuPy 能够在 GPU 上实现 Numpy 和矩阵运算的多倍加速。值得注意的是,用户所能实现的加速高度依赖于自身正在处理的数组大小。下表显示了不同数组大小(数据点)的加速差异:
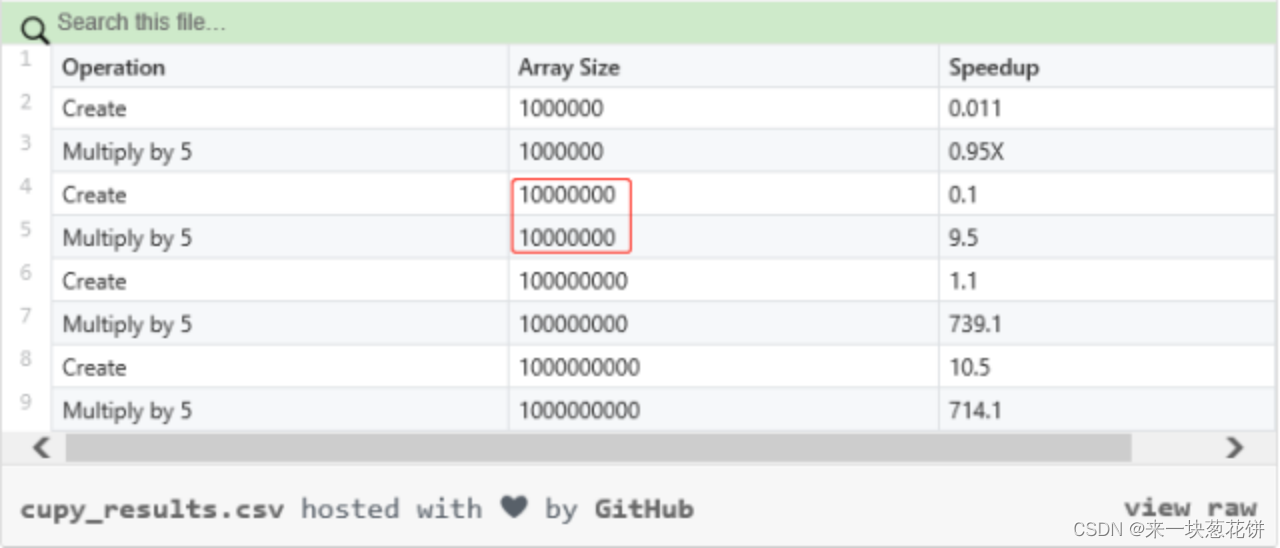
数据点一旦达到 1000 万,速度将会猛然提升;超过 1 亿,速度提升极为明显。Numpy 在数据点低于 1000 万时实际运行更快。此外,GPU 内存越大,处理的数据也就更多。所以用户应当注意,GPU 内存是否足以应对 CuPy 所需要处理的数据。
4.cupy安装与简单实用
pip install cupy
# For CUDA 8.0
pip install cupy-cuda80
# For CUDA 9.0
pip install cupy-cuda90
# For CUDA 9.1
pip install cupy-cuda91
# For CUDA 9.2
pip install cupy-cuda92
# For CUDA 10.0
pip install cupy-cuda100
# For CUDA 10.1
pip install cupy-cuda101
# Install CuPy from source
pip install cupy
cupy的使用几乎和numpy完全一致,只需要import cupy,然后将对应numpy.xx换为cupy.xx就行,因为numpy的函数和cupy的函数是镜像的。
import cupy as cp
x = cp.arange(6).reshape(2, 3).astype('f')
print(x, x.sum(axis=1))
>>> x = cp.arange(6, dtype='f').reshape(2, 3)
>>> y = cp.arange(3, dtype='f')
>>> kernel = cp.ElementwiseKernel(
... 'float32 x, float32 y', 'float32 z',
... '''if (x - 2 > y) {
... z = x * y;
... } else {
... z = x + y;
... }''',
... 'my_kernel')
>>> kernel(x, y)
array([[ 0., 2., 4.],
[ 0., 4., 10.]], dtype=float32)
参考链接:https://blog.csdn.net/qq_41185868/article/details/103479683
5.cupy和pytorch转换
cupy与numpy互转
import cupy as cp
import numpy as np
#cupy->numpy
numpy_data = cp.asnumpy(cupy_data)
#numpy->cupy
cupy_data = cp.asarray(numpy_data)
cupy与pytorch互转
需要借助中间库 dlpack,三者关系是:cupy.array<–>Dlpack.Tensor<–>torch.Tensor
from cupy.core.dlpack import toDlpack
from cupy.core.dlpack import fromDlpack
from torch.utils.dlpack import to_dlpack
from torch.utils.dlpack import from_dlpack
import torch
#pytorch->cupy
cupy_data = fromDlpack(to_dlpack(tensor_data))
#cupy->pytorch
tensor_data = from_dlpack(toDlpack(cupy_data))
numpy与pytorch互转
import numpy as np
import torch
#pytorch->numpy
numpy_data = tensor_data.numpy()
#numpy->pytorch
tensor_data = torch.from_numpy(numpy_data)
二.开发辅助工具
1.ipython辅助开发
一种是生成一个python终端
$ ipython
Python 3.6.6 (default, Aug 13 2018, 18:24:23)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.16.2 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import cupy as cp
...: import numpy as np
...: a = cp.array([1,2,5])
...: b = cp.asnumpy(a)
In [2]:
In [2]: a_ = a+1
In [3]: a_
Out[3]: array([2, 3, 6])
In [4]: b_ = b+1
In [5]: b_
Out[5]: array([2, 3, 6])
另一种用法是,在对应位置中断:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RyuL7FmR-1672043488872)(C:\Users\yuan02.gao\AppData\Roaming\Typora\typora-user-images\image-20220109155204078.png)]](https://img-blog.csdnimg.cn/7531c6c827864b3b9c75b0033216add3.png)
当run到这个位置的时候,就会在终端生成调试接口
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g2P6HaBn-1672043488872)(C:\Users\yuan02.gao\AppData\Roaming\Typora\typora-user-images\image-20220103204825015.png)]](https://img-blog.csdnimg.cn/25fe4189b6224e9fb5cea985dc6fa512.png)
可以在这里查看该位置和之前的数据,以及进行代码运行调试,非常方便
2.debug调试
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-elveaNTD-1672043488872)(C:\Users\yuan02.gao\AppData\Roaming\Typora\typora-user-images\image-20220109155231754.png)]](https://img-blog.csdnimg.cn/400cf4d7f86c4c1f82e8bbaaa99b91e6.png)
在main函数左侧点击,可以进行debug设置,debug模式下就从这里开始运行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0DLSWo60-1672043488872)(C:\Users\yuan02.gao\AppData\Roaming\Typora\typora-user-images\image-20220103205046832.png)]](https://img-blog.csdnimg.cn/d610ea9911964849beb74aa0bd3a49cf.png)
在调试控制台输入对应指令,就可以逐步调试。
3.存储python中间数据,进行单元测试
每次运行整个工程太慢,我就把中间数据(该单元要使用的数据)存储下来,然后写到if name == ‘main’:里面,
将对应代码写到这个脚本里,在这个脚本里运行对应代码。
import pickle
# 存储变量的文件的名字
filename = 'shoplist.data'
# 初始化变量
shoplist = ['apple', 'mango', 'carrot']
# 以二进制写模式打开目标文件
f = open(filename, 'wb')
# 将变量存储到目标文件中区
pickle.dump(shoplist, f)
# 关闭文件
f.close()
# 删除变量
del shoplist
# 以二进制读模式打开目标文件
f = open(filename, 'rb')
# 将文件中的变量加载到当前工作区
storedlist = pickle.load(f)
print(storedlist)
以上操作就够了。输出为.data的二进制文件
4.numpy基本操作
实现加减乘除运算
import numpy as np
#输入两个数
x=int(input("the fist number: "))
y=int(input("the second number: "))
#选择相应运算
print("1.add the two numbet")
print("2.subtract the two numbet")
print("3.mulitiply the two numbet")
print("4.divide the two numbet")
z=int(input("please choice the number:"))
#根据选择执行命令
if z==1:
print("{0} + {1} = {2}".format(x,y,np.add(x,y)))
elif z==2:
print("{0} - {1} = {2}".format(x,y,np.subtract(x,y)))
elif z==3:
print("{0} * {1} = {2}".format(x,y,np.multiply(x,y)))
else:
print("{0} / {1} = {2}".format(x,y,np.divide(x,y)))
乘法
print(np.multiply(2, 4))
print(np.multiply(2, 3.8))
---output---
8
7.6
参考链接:https://blog.csdn.net/Amy8020/article/details/88635642
这里有非常全面的一篇博客,介绍numpy的使用,必看:

三.具体开发
0.开发思路
一开始的思路是直接改,逐个验证
import cupy as cp
#将numpy升级为cupy
#两种情况要升级:1.生成numpy的nadrray数据,要转化为对应的cupy数据。2.使用np.xxx要改为cp.xxx
#先找到对应的位置,标出来要改的地方
#分段进行测试,记录每一段代码的输出结果。结果有两个:1.原先的numpy的操作结果。2.改为cupy的对应结果
#先记录numpy的结果每个节点的结果,然后逐段去改为cupy,对比对应的结果
#最后考虑输出结果要不要,再把cupy改为numpy
后来发现,cupy的函数和numpy的函数命名高度统一,直接将np.xx换为cp.xx就行。
1.config文件
为了方便整个工程的管理,先在config文件里编写对应设置:
#proposal_target.py中,在判断为True的时候使用Cupy,False的时候使用numpy
proposal_target_gpu_mode = True
# proposal_target_gpu_mode = False
config.proposal_target_gpu_mode = proposal_target_gpu_mode
2.在proposal_target.py里定义flag
class ProposalTargetOperator里都是使用self.P
init函数读取config设置
self.proposal_target_gpu_mode = self.config.proposal_target_gpu_mode
if self.proposal_target_gpu_mode:
self.P = cp
else:
self.P = np
使用P作为flag,这样方便代码管理,numpy和cupy的函数都对应同一套代码,只不过P不一样而已。
def kps_from_target(P, xxx, xxx):
# P可以是np,也可以是cp
原来:
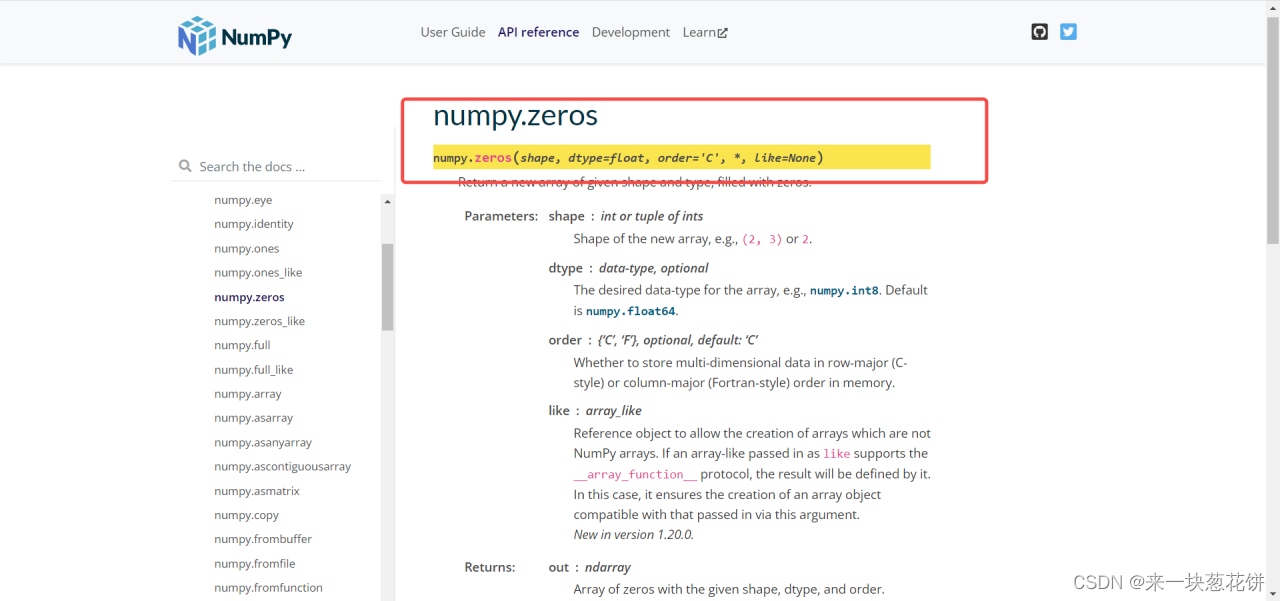
np.zeros()
修改之后:
P.zeros
是np还是cupy可以从外界传入,这样就很方便
3.数据读取
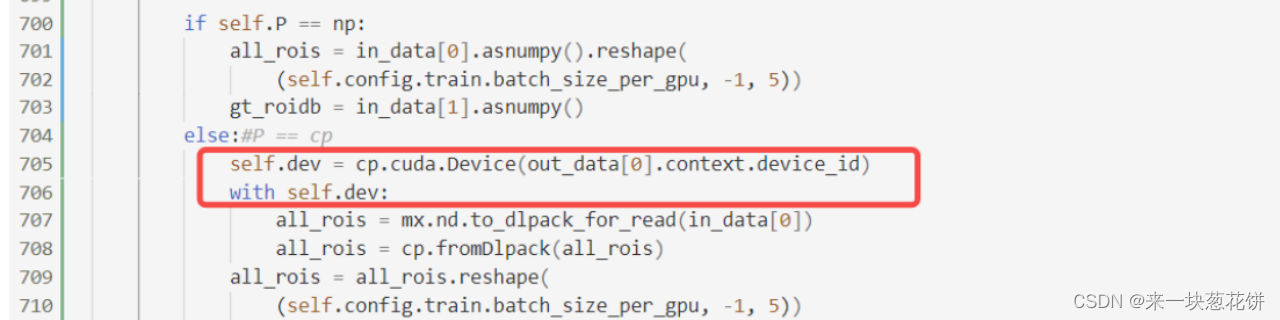
注意:这里是将mxnet的输入数据转为cupy数据,如果是使用pytorch,操作类似。
原先输入的数据时symbol数据(mxnet对于静态图的数据形式)或者NDArray(mxnet对于动态图的数据形式),要将数据转为np.ndarray,现在要转化为cp._core.core.ndarray
完整修改方法:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qOfYwTc7-1672043488873)(C:\Users\yuan02.gao\AppData\Roaming\Typora\typora-user-images\image-20220103203237551.png)]](https://img-blog.csdnimg.cn/ee208a15c834484f9188f09b4fe64de5.png)
读取数据
if self.P == np:
all_rois = in_data[0].asnumpy().reshape(
(self.config.train.batch_size_per_gpu, -1, 5))
else:#P == cp
all_rois = mx.nd.to_dlpack_for_read(in_data[0])
all_rois = cp.fromDlpack(all_rois)
all_rois = all_rois.reshape(
(self.config.train.batch_size_per_gpu, -1, 5))
toDlpack和from_dlpack函数,直接将输入的转为cupy、应用到gpu上,很快。
4.函数修改
因为cupy的函数都是numpy的函数的镜像,所以直接把np.xx换为cp.xx
# gt_assignment = np.zeros((rois.shape[0],), dtype=np.float32)
#-------------------------------这里P表示np或者cp,根据输入的config,确定P的值
gt_assignment = P.zeros((rois.shape[0],), dtype=P.float32)
也可以将cupy函数和numpy函数进行用例的对比

import cupy as cp
import numpy as np
a = cp.array([1,2,5])
b = cp.asnumpy(a)
a_ = cp.add(a,1)
b_ = np.add(b,1)
---------------------------查看输出结果
a_
array([2, 3, 6])
b_
array([2, 3, 6])
5.cython的问题
有一段代码(iou的计算)是使用cython完成的,即使用cython代码编写,底层使用c执行,所以很快。
本来打算将cython也改为cupy,进一步提高速度。
但是评估和调研后发现,cupy不支持cython
一般不会有人既使用cupy又使用cython,因为使用其中一个就已经很快了。
之后尝试不使用cython,将对应代码用python和cupy实现,发现速度并不快,所以放弃修改。保持原来的cython代码
6.多进程问题
单进程调试成功后,要看看多进程调试是否成功
worker_pool_global = multiprocessing.Pool(processes=48)
7.对齐一致性
代码修改好,跑通后,要进行一致性测试。
即一样的输入,看修改前后输出是否一致。
def rcnn_target(P, xxxx):
def test()
input = xxx
# case A
cpu_output = rcnn_target(np, input)
# case B
gpu_output = rcnn_target(cupy, input)
首先要将random函数固定住,固定随机数种子(注意:每一个random函数前都要有random.seed(number),而不是只在文件开头写)
if P==cp:
np.random.seed(0)#固定随机数种子,之后可以取消
fg_indexes = np.random.choice(cp.asnumpy(fg_indexes), size=int(fg_rois_per_this_image),
replace=False)
fg_indexes = cp.asarray(fg_indexes)
else:
P.random.seed(0)#固定随机数种子,之后可以取消
fg_indexes = P.random.choice(fg_indexes, size=int(fg_rois_per_this_image),
replace=False)
对齐:
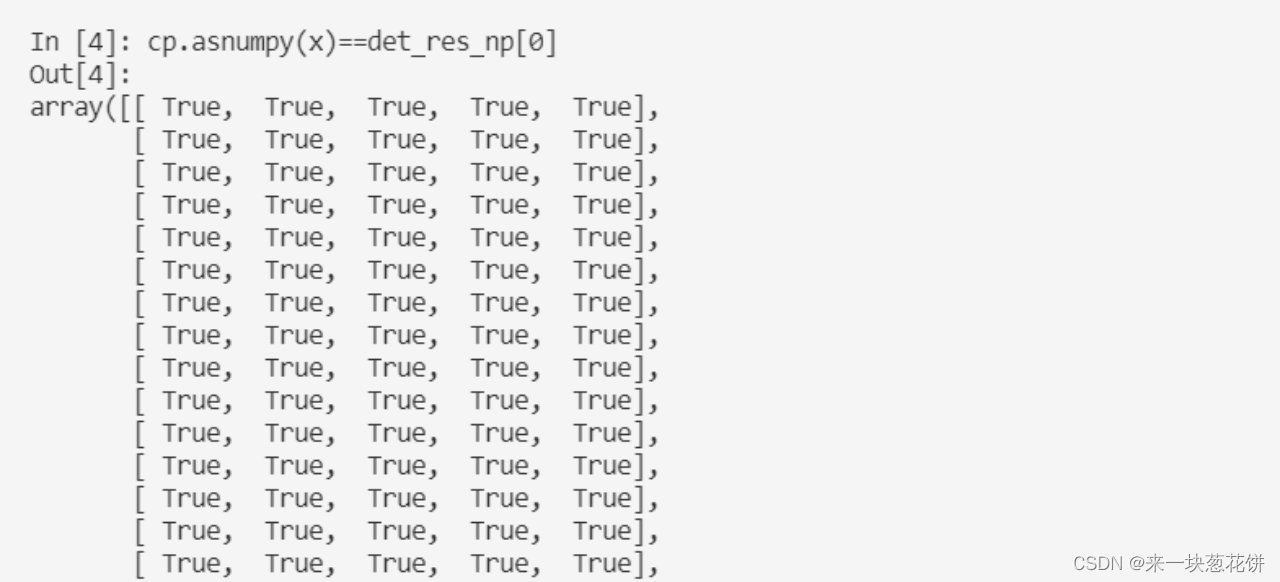
再具体比较:
np.max(data_np[3] - data_cp[3])
np.max(data_cp[3] - data_np[3])

对于这种,微小的差异是不可避免的
这种微小差异,要搞懂cuda底层,才能知道差异在哪。应该是对不上的,想对也对不上的。
8.测速
from time import time
start_time = time()
w = P.add(P.subtract(x2, x1), P.asarray(1))#一个区域的长宽
h = P.add(P.subtract(y2, y1), P.asarray(1))
end_time = time()
if P == np:
print('numpy_time=',end_time-start_time)
elif P == cp:
print('cupy_time=',end_time-start_time)
9.优化代码,节省时间
由于之前的反序列化将cupy转化为numpy,导致后面进行了多个语句的numpy转cupy。在反序列化之前,输入是mxnet数据。所以我直接保留mxnet数据形式,进行反序列化之后,我再转为cupy。这样就可以省下时间了
类似于这种加减乘除也要改为cupy,会快很多。
int等类型的数据输入,也要改为cupy。然后再送入cupy函数。
得把所有数据都转成cupy数据,cupy.asarray()。所有的操作都得使用cupy函数。
把类似于大于小于号这样的比较也换为cupy函数,应该还能加快
10.集群测试
在开发机上测试,有时候内存和性能会受到别的用户的影响,所以提交集群测试。
提交集群测试的时候,需要自己选择环境。
一般需要使用一个已有的docker环境,如果不包含对应库包,可以手动安装、生成新的docker镜像,直接使用。
集群测试,将batchsize调大,尽量使得gpu利用率饱和
集群上能直接看xxx samples/sec,作为整体的训练速度

11.cupy多卡训练
每次cupy操作对应的数据都必须在一张卡上。要使用多卡进行cupy训练,就要进行设置:
注意:
要在一开始给cupy数据分配device
对应的语句,都应该包含在with self.dev: 内部,才能保证这些操作都在该device下
self.dev = cp.cuda.Device(out_data[0].context.device_id)
with self.dev:
.......
with self.dev:
for n in range(self.config.train.batch_size_per_gpu):
all_rois_n = all_rois[n, :]
gt_roidb_n = gt_roidb[n, :]
......
测试结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5DVLwURR-1672043488873)()]](https://img-blog.csdnimg.cn/75649b3805c54252be74e1a69d0e5ec7.png#pic_center)
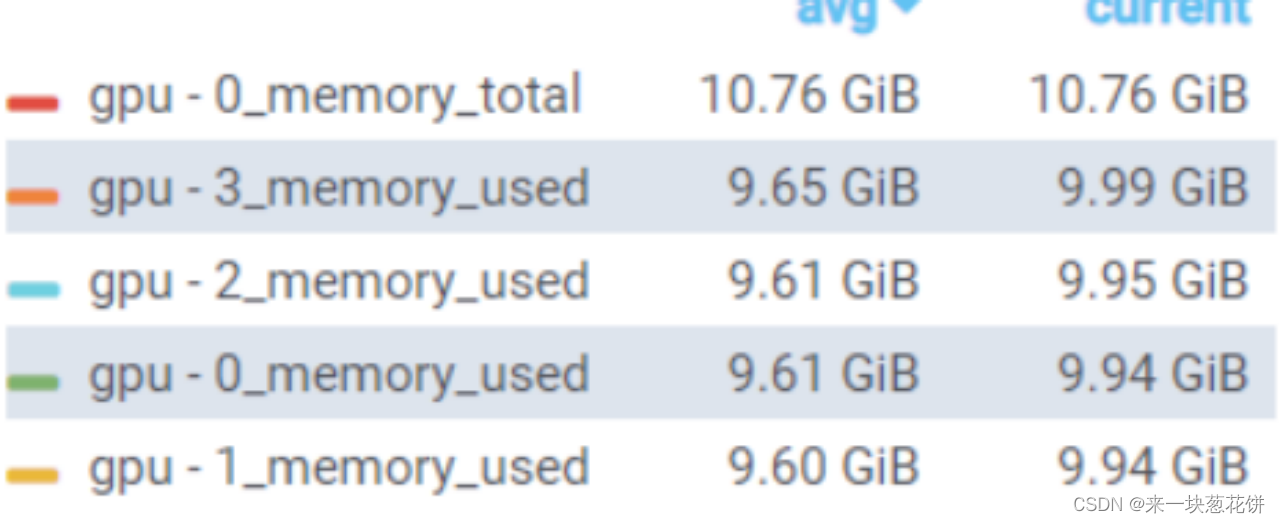
五.评估结果
1.结果
当数据量大、数据维数多、或者矩阵乘法操作多,cupy明显比numpy操作快,可以提速十倍甚至上百倍。
反之,则cupy不能快于numpy操作。
2.原因
cupy主要是矩阵乘法等高维、大规模计算快。CuPy在数据维数较低时,没有体现出加速,但是应对高维数据时,有明显的加速。当数据维数很高时,强烈建议GPU加速。
在数据量不是很大的时候,cupy确实要比numpy要慢。numpy使用cpu,一方面gpu和cpu有数据转移的耗时,另一方面cpu有cache速度较快(只是存储空间比较小)。所以数据量小的时候,cupy要比numpy慢。
https://stackoverflow.com/questions/57060365/why-is-the-execution-time-for-numpy-faster-than-cupy
- 这是一个陷阱,吸引了许多不熟悉 GPU 的人。程序的原始 GPU 版本比 CPU 版本慢是很常见的。使用 GPU 使代码快速运行并非易事,主要是因为将数据复制到 GPU 和从 GPU 复制数据的额外延迟。无论您使用 GPU 获得何种加速,都必须首先克服这种开销。您在 GPU 上做的工作还不够多,无法让开销变得值得。您在 cp.random.randint() 调用中等待数据移动所花费的时间远远多于您实际计算任何内容的时间。在 GPU 上做更多的工作,你会看到 GPU 负责,就像对大型数据集进行归约操作一样。
- Numpy 比您预期的要快得多,因为它是用经过优化的 C 语言编写的。它不是纯 Python。所以你试图超越的基准实际上是相当快的。
- 如果您真的想探索 GPU 性能调优的深度,请尝试编写一些 CUDA 并使用 NVIDIA Visual Profiler 来检查 GPU 实际在做什么。
3.cupy特性

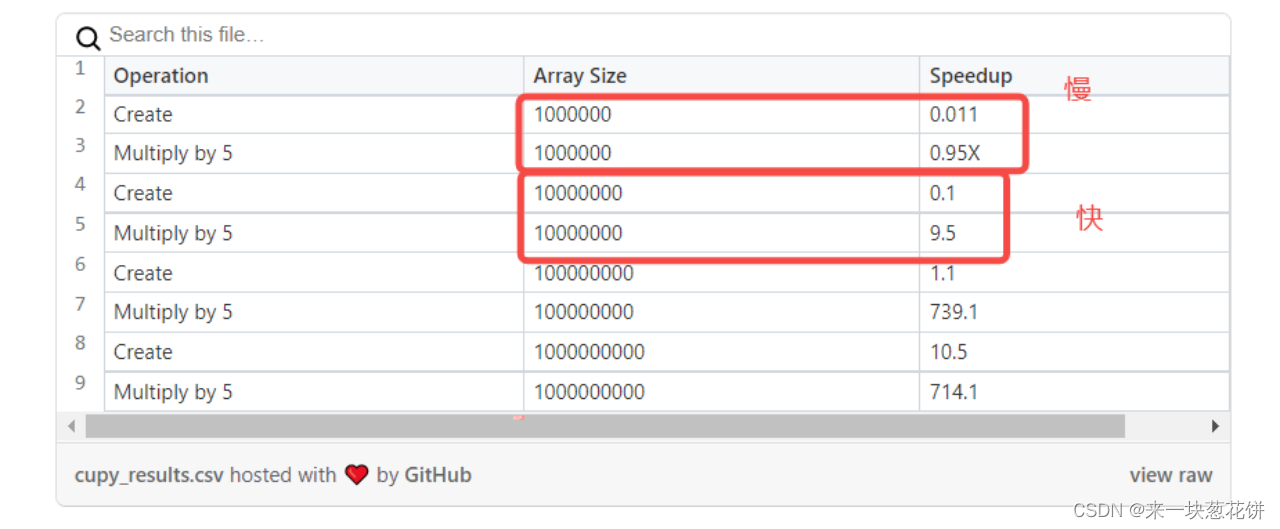
下表显示了不同数组大小(数据点)的加速差异:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TiFaenD8-1672043488873)(C:\Users\yuan02.gao\AppData\Roaming\Typora\typora-user-images\image-20211222190229025.png)]](https://img-blog.csdnimg.cn/55a882c264c14bc0b65a6b20fa8e31b7.png)
CuPy在数据维数较低时,没有体现出加速,反而因为cpu和gpu的数据沟通和转移消耗了时间,总耗时反而增加
但是应对高维数据时,尤其是矩阵的乘法,有明显的加速。当数据维数很高时,强烈建议GPU加速
码字不易,都看到这里了不如点个赞哦~
这里是【来一块葱花饼】,你的点赞+收藏+关注,就是我坚持下去的最大动力~
















 8350
8350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











