







本学习笔记为Datewhale-7月组队学习-动手学数据分析的学习内容,学习链接为:https://github.com/datawhalechina/hands-on-data-analysis
目录
一、数据清洗
1.数据加载
import numpy as np
import pandas as pd
df = pd.read_csv('train.csv')
2.缺失值观察处理
2.1缺失值观察
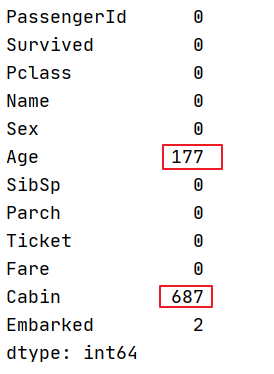
2.1.1观察特征缺失值个数
两种方法:df.info()、df.isnull().sum()
方法一:
df.info()

得自己减一下
方法二:
df.isnull().sum()
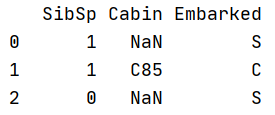
2.1.2查看有缺失值的列
- 行(列)选取(单维度选取):df[]。这种情况一次只能选取行或者列,即一次选取中,只能为行或者列设置筛选条件(只能为一个维度设置筛选条件)。
- 区域选取(多维选取):df.loc[],df.iloc[],df.ix[]。这种方式可以同时为多个维度设置筛选条件。
- 单元格选取(点选取):df.at[],df.iat[]。准确定位一个单元格。
方法一:
df[['Age','Cabin','Embarked']]
方法二:
df.loc[:,['Age','Cabin','Embarked']]
方法三:
df.iloc[:,[6,10,11]]
三种方法结果一样
2.2对缺失值进行处理
2.2.1处理缺失值的思路
- 删除
- 补充
2.2.2处理某列数据的缺失值
# 方法一
df[df['Age']==None]=0
# 方法二
df[df['Age'].isnull()] = 0
# 方法三
df[df['Age'] == np.nan] = 0
数值列读取数据后,空缺值的数据类型为float64,所以用None一般索引不到,比较的时候最好用np.nan
2.2.3处理整张表的缺失值
删除有缺失值的列
df.dropna(axis=1)

用0填充缺失值
df.fillna(0)

dropna函数:将带有缺失值的数据使用dropna函数删除

fillna函数:当缺失值所在的数据比较重要的时候,可能不适合删除,可以使用填充缺失值的方法fillna

3.重复值观察和处理
3.1查看数据中的重复值
df[df.duplicated()]
3.2对重复值进行处理
重复值一般就是删除,但还有些不能删除

















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











