






1.SIOU
传统的目标检测损失函数依赖于边界框回归指标的聚合,例如预测框和真实框(即 GIoU、CIoU、ICIoU 等)的距离、重叠区域和纵横比。
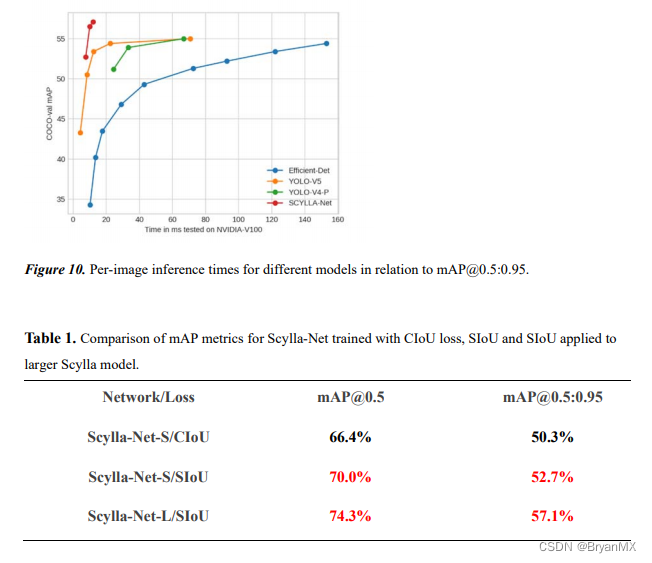
然而,迄今为止提出和使用的方法都没有考虑到所需真实框与预测框之间不匹配的方向。本文中,提出了一种新的损失函数 SIoU,其中考虑到所需回归之间的向量角度,重新定义了惩罚指标。应用于传统的神经网络和数据集,表明 SIoU 提高了训练的速度和推理的准确性。
在许多模拟和测试中揭示了所提出的损失函数的有效性。特别是,将 SIoU 应用于 COCO-train/COCO-val 与其他损失函数相比,提高了 +2.4% (mAP@0.5:0.95) 和 +3.6%(mAP@0.5)。

2. G-GhostNet
PyTorch代码
现有的轻量级推理网络(MobileNet, EfficientNet, ShuffleNet,GhostNet)都是针对CPU、ARM等移动设备设计而成,在GPU等基于大吞吐量设计的处理单元上的表现却不尽人意,推理速度甚至比传统的卷积神经网络更慢。新版GhostNet(G-GhostNet)提出的跨层廉价操作,减少计算量的同时减少的内存数据搬运,基于此设计了GPU版GhostNet,可用于不同网络结构中,提升GPU等设备上的运行速度。至此,GhostNet系列已经打通ARM、CPU、GPU甚至NPU的常用设备,能够在不同硬件需求下达到最佳的速度和精度的平衡。在华为自研NPU昇腾310上,G-GhostNet的速度比同量级ResNet要快30%以上。该论文已被计算机视觉顶级期刊IJCV收录。
3.SWA(随机权重平均)
官方代码
SWA简单来说就是对训练过程中的多个checkpoints进行平均,以提升模型的泛化性能。一般情况下我们会选择训练过程中最后的一个epoch的模型或者在验证集上效果最好的一个模型作为最终模型。但SWA一般在最后采用较高的固定学习速率或者周期式学习速率额外训练一段时间,取多个checkpoints的平均值。















 9622
9622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









