







动手学深度学习19 卷积层
1. 从全连接到卷积

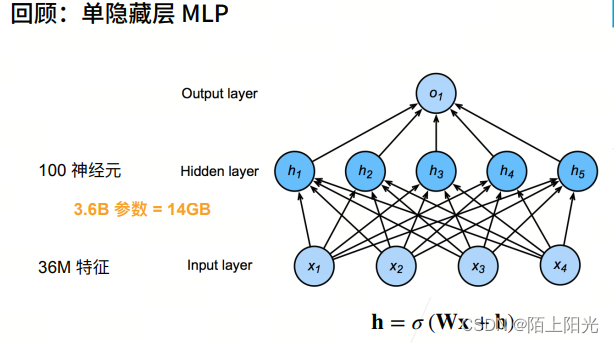
3.6B元素 36亿元素–模型参数,存储下来需要14GB大小。
waldo在哪里,找waldo遵循两个原则。识别图片的识别器找到目标不会因为在图片的那个位置而有不同,从局部找就可以,不用从全局。

怎么从全连接层处罚,应用平移不变性和局部性这两个原则,得到卷积。
考虑到空间信息,必须用矩阵。
二维到四维:

对下标做变换引出卷积。
v不发生变化,不论识别器移到哪里位置i j,识别器都是不变的。
平移不变性,对权重做了限制,不是每个元素都可以自由变换,降低模型复杂度,不用存储太多元素。干掉 i j 维度。

不看远离输入
x
i
,
j
x_{i,j}
xi,j 太远的元素,只看附近的。超过delta位置的元素就不看了。

v–压缩成一个二维的东西

2. 卷积层
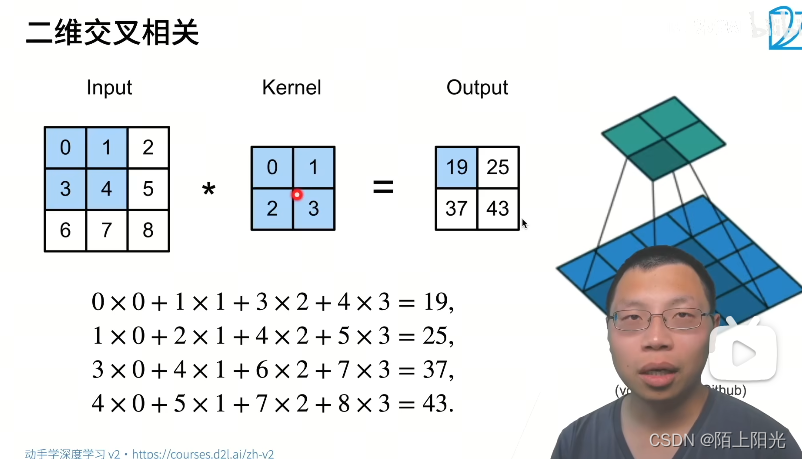
平移不变性,kernel是不变的。输出看局部,局部和kernel对应位置计算。kernel窗口不断的往右移往下移,不断计算。
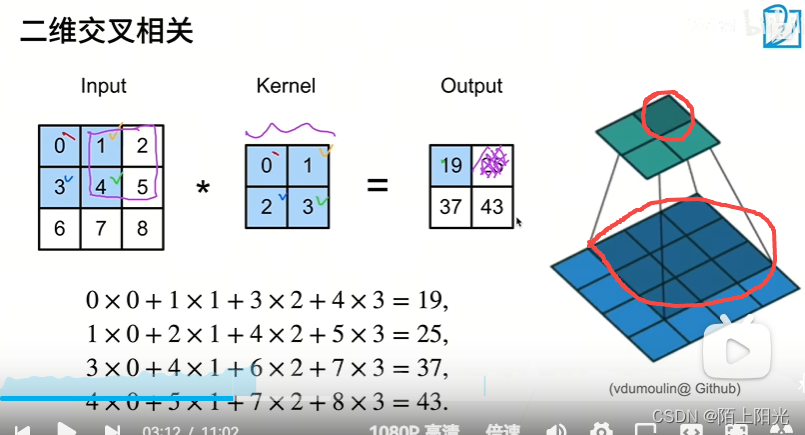
当kernel移动到边界,没有数据了就不再移动,这样就会丢掉一些数据
(
k
h
−
1
,
k
w
−
1
)
(k_h-1, k_w-1)
(kh−1,kw−1)
星号:表示二维交叉相关计算操作子

不同的卷积核会带来不同的效果。神经网络可以学习一些kernel,达到我们想要的效果。

交叉相关和卷积没有太大区别,区别是卷积在索引处有负号,在索引w的时候是反过来走的,所以是负号。又因为是对称的,在实际使用中正反没有区别,学到的w正反,左右上下反一下是一样的东西。
说是卷积层,实际计算实现的是交叉相关。

kernel卷积核大小控制的是局部性,大看的局部多,小看的局部少。
卷积层是个特殊的全连接层。卷积核不会随着输入数据大小而改变,可以固定。

3. 代码
白变黑 黑变白 第一列第二列数值相同就相加为0,不同则等于正1或者负1.
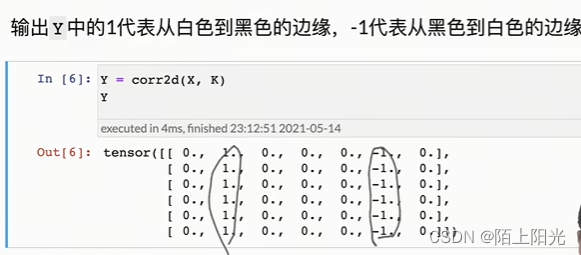
只能检查纵向,不能检查横向。1*2只能检测垂直的。
从数据中,学出kernel的值。
手写梯度下降
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(X, K):
"""计算二维互相关运算"""
h, w = K.shape
# 创建输出Y的shape,用0填充。
Y = torch.zeros((X.shape[0]-h+1, X.shape[1]-w+1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i+h, j:j+w] * K).sum()
return Y
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
print(X, K)
print(corr2d(X, K))
# tensor([[0., 1., 2.],
# [3., 4., 5.],
# [6., 7., 8.]])
# tensor([[0., 1.],
# [2., 3.]])
# tensor([[19., 25.],
# [37., 43.]])
# 边缘检测
class Conv2D(nn.Module):
# 传参 卷积核shape
def __init__(self, kernel_size):
super().__init__()
# weight和卷积核大小shape一致
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
X = torch.ones((6, 8))
X[:, 2:6] = 0
print(X)
K = torch.tensor([[1.0, -1.0]])
Y = corr2d(X, K)
print(Y)
# 该K无法检测水平边缘
print(corr2d(X.t(), K))
# 6.2.4. 学习卷积核
# 手动实现一个梯度下降
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
# nn.Conv2d(输入输出通道)
conv2d = nn.Conv2d(1, 1, kernel_size=(1,2), bias=False)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i+1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}')
# 查看学习到的卷积核的值
print(conv2d.weight.data)
print(conv2d.weight.data.reshape((1, 2)))
tensor([[0., 1., 2.],
[3., 4., 5.],
[6., 7., 8.]]) tensor([[0., 1.],
[2., 3.]])
tensor([[19., 25.],
[37., 43.]])
tensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])
tensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])
tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
epoch 2, loss 20.265
epoch 4, loss 6.997
epoch 6, loss 2.647
epoch 8, loss 1.048
epoch 10, loss 0.423
tensor([[[[ 1.0548, -0.9211]]]])
tensor([[ 1.0548, -0.9211]])
4. QA
17: 100个神经元—>输出维度100维
18:怎么对全连接层做限制做变化到卷积层。
19: 图片本身是一个二维矩阵,卷积就是直接对二维矩阵处理,不用reshape
20: 可变卷积 https://blog.csdn.net/jiangqixing0728/article/details/126269423
21: 最终要看到所有的数据,不用看很远,类似于宽浅MLP的效果不一定好于深窄的MLP。卷积核一样,深且卷积核小的网络可能好于浅且卷积核大的网络。因为每次看一点每次看一点,最终看到的数据是一样的。主流用33或者55.


22:google的论文 inception v1 设计师思路。
23:卷积是从信号处理求解线性不变系统输出得来的,符号的来源是单位脉冲。傅里叶变换。
24: 平移不变性: 不管在图片的那个位置,卷积核是不变的。
25:卷积核由先验知识确定。
26:数字与信号处理定义卷积数学含义,196X年定义的。
27:抖动很厉害可能是因为学习率太大,或者数据多样性很大,随机采样可能看的数据不一样,抖动没关系。可以把批量大小弄大,可以把抖动弄平滑。但是只抖动不下降是不可以的。可以设置学习率高一些、批量大小大一些。都可以尝试。
28:全连接层最大问题:权重w的高取决于输入的宽,当输入给1200w像素的时候,权重的高就是1200w,权重参数的矩阵过大,数据爆炸。卷积核大小固定,没有这个问题。实际使用不会放这么大的数据进去,可能200*200.














 349
349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









