







本文转载:https://wmathor.com/index.php/archives/1475/
“干翻芝麻街”
2018 年,谷歌发布了基于双向 Transformer 的大规模预训练语言模型 BERT,刷新了 11 项 NLP 任务的最优性能记录,为 NLP 领域带来了极大的惊喜。很快,BERT 就在圈内普及开来,也陆续出现了很多与它相关的新工作
BERT 带来的震撼还未平息,来自卡耐基梅隆大学与谷歌大脑的研究者又提出新型预训练语言模型 XLNet,在 SQuAD、GLUE、RACE 等 20 个任务上全面超越 BERT
作者表示,BERT 这样基于去噪自编码器的预训练模型可以很好地建模双向语境信息,性能优于基于自回归语言模型的预训练方法。然而,由于需要 mask 一部分输入,BERT 忽略了被 mask 位置之间的依赖关系,因此出现预训练和微调效果的差异(pretrain-finetune discrepancy)
基于这些优缺点,该研究提出了一种泛化的自回归预训练模型 XLNet。XLNet 可以:1)通过最大化所有可能的因式分解顺序的对数似然,学习双向语境信息;2)用自回归本身的特点克服 BERT 的缺点。此外,XLNet 还融合了当前最优自回归模型 Transformer-XL 的思路
最终,XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果(state-of-the-art),包括机器问答、自然语言推断、情感分析和文档排序
以前超越 BERT 的模型很多都在它的基础上做一些修改,本质上模型架构和任务都没有太大变化。但是在这篇新论文中,作者从自回归(autoregressive)和自编码(autoencoding)两大范式分析了当前的预训练语言模型,并发现它们虽然各自都有优势,但也都有难以解决的困难。为此,研究者提出 XLNet,并希望结合大阵营的优秀属性
AR 与 AE 两大阵营

自回归语言模型(AutoRegressive LM)
在 ELMO/BERT 出来之前,大家通常讲的语言模型其实是根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行(就是根据下文预测前面的单词)。这种类型的 LM 被称为自回归语言模型。GPT 就是典型的自回归语言模型。ELMO 尽管看上去利用了上文,也利用了下文,但是本质上仍然是自回归 LM,这个跟模型具体怎么实现有关系。ELMO 是分别做了两个方向的自回归 LM(从左到右以及从右到左两个方向的语言模型),然后把 LSTM 的两个方向的隐状态拼接到一起,来体现双向语言模型这个事情的。所以其本质上仍然是自回归语言模型
给定文本序列x=[x1…xn] ,语言模型的目标是调整参数使得训练数据上的似然函数最大
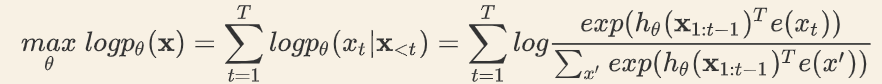
其中,e(x)表示x的embedding
自回归语言模型的缺点是无法同时利用上下文的信息,貌似 ELMO 这种双向都做,然后拼接看上去能够解决这个问题,但其实融合方法过于简单,所以效果其实并不是太好。它的优点跟下游 NLP 任务有关,比如生成类 NLP 任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。而 Bert 这种 DAE(Denoise AutoEncoder)模式,在生成类 NLP 任务中,面临训练过程和应用过程不一致的问题,导致生成类的 NLP 任务到目前为止都做不太好
自编码语言模型(AutoEncoder LM)
BERT 通过将序列x中随机挑选 15% 的 Token 变成 [MASK] 得到带噪声版本的 x^hat。假设被 Mask 的原始值为 ,那么 BERT 希望尽量根据上下文恢复(猜测)出原始值,也就是
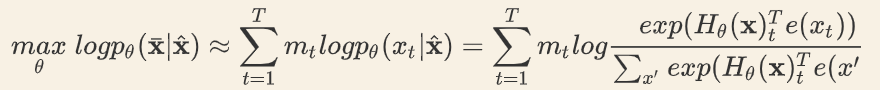
上式中,若 mt=1,表示 t时刻是一个 Mask,需要恢复。H表示Transformer,它把长度为 T 的序列 x 映射为隐状态的序列。注意:前面的语言模型的 RNN 在 时刻只能看到之前的时刻,BERT 的 Transformer(不同与用于语言模型的 Transformer)可以同时看到整个句子的所有 Token。
这种 AE LM 的优缺点正好和 AR LM 反过来,它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文,这是好处。缺点是啥呢?主要在输入侧引入 [Mask] 标记,导致预训练阶段和 Fine-tuning 阶段不一致的问题,因为 Fine-tuning 阶段是看不到 [Mask] 标记的
XLNet 的出发点就是:能否融合自回归 LM 和 DAE LM 两者的优点。具体来说就是,站在 AR 的角度,如何引入和双向语言模型等价的效果
Permutation Language Model
作者们发现,只要在 AR 以及 AE 方式中再加入一个步骤,就能够完美地将两者统一起来,那就是 Permutation

具体实现方式是,通过随机取一句话排列的一种,然后将末尾一定量的词给 “遮掩”(和 BERT 里的直接替换 “[MASK]” 有些不同)掉,最后用 AR 的方式来按照这种排列方式依此预测被 “遮掩” 掉的词

这里我稍微解释下,为什么是 “遮掩” 末尾的一些词,以及随机打乱句子的顺序有什么用?输入句子正常的顺序是 “1 2 3 4 5 6 7”,常规的自回归 LM 无法同时考虑上下文信息。如果能够同时考虑上下文信息,那 “3” 这个词,需要有 “1 2 4 5 6 7” 这些信息,换句话说,在预测 “3” 之前,我们需要保证模型已经看过 “1 2 4 5 6 7”(无所谓顺序)。而打乱句子的顺序之后(比方说上图的例子),3 这个词就来到了句子的末尾,此时按照自回归 LM 预测 “3” 的时候,模型已经看过了 “1 2 4 5 6 7”,由此便考虑到了 “3” 的上下文信息。当然,句子到底怎么打乱是无所谓的,因为我们的目标不是具体要预测哪个词,而是谁在最后,就预测谁
这里再谈一个有意思的点,到底该挑选最后几个做遮掩呢?作者这里设了一个超参数 K,K 等于总长度除以需要预测的个数。拿上面的例子,总长为 7 而需要预测为 2,于是 K = 7/2。而论文中实验得出的最佳 K 值介于 1/6 和 1/7 (更好)之间,其实如果我们取 K 的倒数(即 ),然后转为百分比,就会发现最佳的比值介于 14.3% 到 16.7% 之间,还记得 BERT 论文的同学肯定就会开始觉得眼熟了。因为 BERT 里将 Token 遮掩成 “[MASK]” 的百分比就是 15%,正好介于它们之间,我想这并不只是偶然,肯定有更深层的联系

上面的公式看起来有点复杂,细读起来其实很简单:从所有的排列中采样一种,然后根据这个排列来分解联合概率成条件概率的乘积,然后加起来
论文中 Permutation 具体的实现方式不是打乱输入句子的顺序,而是通过对 Transformer 的Attention Mask进行操作

比如说序号依次为 1234 的句子,先随机取一种排列 3241。根据这个排列我们就做出类似上图的 Attention Mask,先看第 1 行,因为在新的排列方式中 1 在最后一个,根据从左到右 AR 方式,1 就能看到 234 全部,于是第一行的 234 位置是红色的(没有遮盖掉,会用到),以此类推,第 2 行,因为 2 在新排列是第二个,只能看到 3 于是 3 位置是红色,第 3 行,因为 3 在第一个,看不到其他位置,所以全部遮盖掉…
没有目标 (target) 位置信息的问题
上面的思想很简单,但是如果我们使用标准的 Transformer 实现时会有问题。下面举个例子



Two-Stream Self-Attention




















 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









