







model.parameters()保存的是Weights和Bais参数的值。
首先定义一个模型
#design Model
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork,self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(2*2, 5),
nn.ReLU(),
nn.Linear(5,3)
nn.ReLU()
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
'''
#print:
NeuralNetwork(
(flatten): Flatten()
(linear_relu_stack): Sequential(
(0): Linear(in_features=4, out_features=5, bias=True)
(1): ReLU()
(2): Linear(in_features=5, out_features=3, bias=True)
(3): ReLU()
)
)
'''
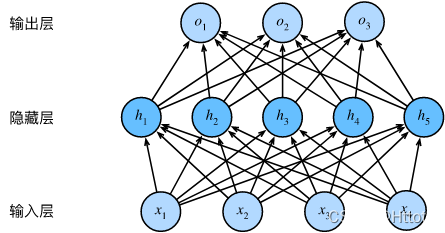
输入一个2 * 2的input(比如2*2的图片),构建长度为5的隐藏全连接层,输出3类(预测图片的label)。
H
=
W
i
X
+
b
;
O
=
σ
(
W
o
H
+
b
)
H = W_iX + b ; O = \sigma(W_oH + b)
H=WiX+b;O=σ(WoH+b)
查看model.parameters()的参数
print(list(model.parameters()))
'''
[Parameter containing: #输入层的 W,每列即为对应x乘的w(维度为5);Wi = [w1,w2,w3,w4]
tensor([[-0.2857, 0.2448, 0.1023, -0.4781],
[-0.2275, 0.3597, 0.3495, 0.0163],
[-0.4321, -0.2033, 0.1903, -0.1599],
[ 0.4215, 0.3982, 0.0478, -0.4342],
[-0.3891, 0.2578, 0.1874, -0.1962]], device='cuda:0',
requires_grad=True), Parameter containing:
tensor([-0.2413, -0.1015, -0.4152, 0.2088, 0.4680], device='cuda:0',
requires_grad=True), Parameter containing: #隐藏层的 W,每列为h对应乘的w(维度为3); Wo = [w1,w2,w3,w4,w5]
tensor([[-3.5943e-01, -1.1033e-01, 8.3123e-02, 7.8943e-02, -3.6048e-01],
[ 1.3593e-01, 4.2951e-01, -3.7831e-01, 2.6139e-01, 1.0279e-01],
[ 2.5864e-01, 4.1339e-01, 2.4220e-04, -3.3391e-01, 7.3478e-02]],
device='cuda:0', requires_grad=True), Parameter containing:
tensor([0.3463, 0.0749, 0.0696], device='cuda:0', requires_grad=True)]
'''
实际上parameters里存的就是weight,parameters()会返回一个生成器(迭代器)

















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









