






文章目录
一、sklearn.cluster.KMeans

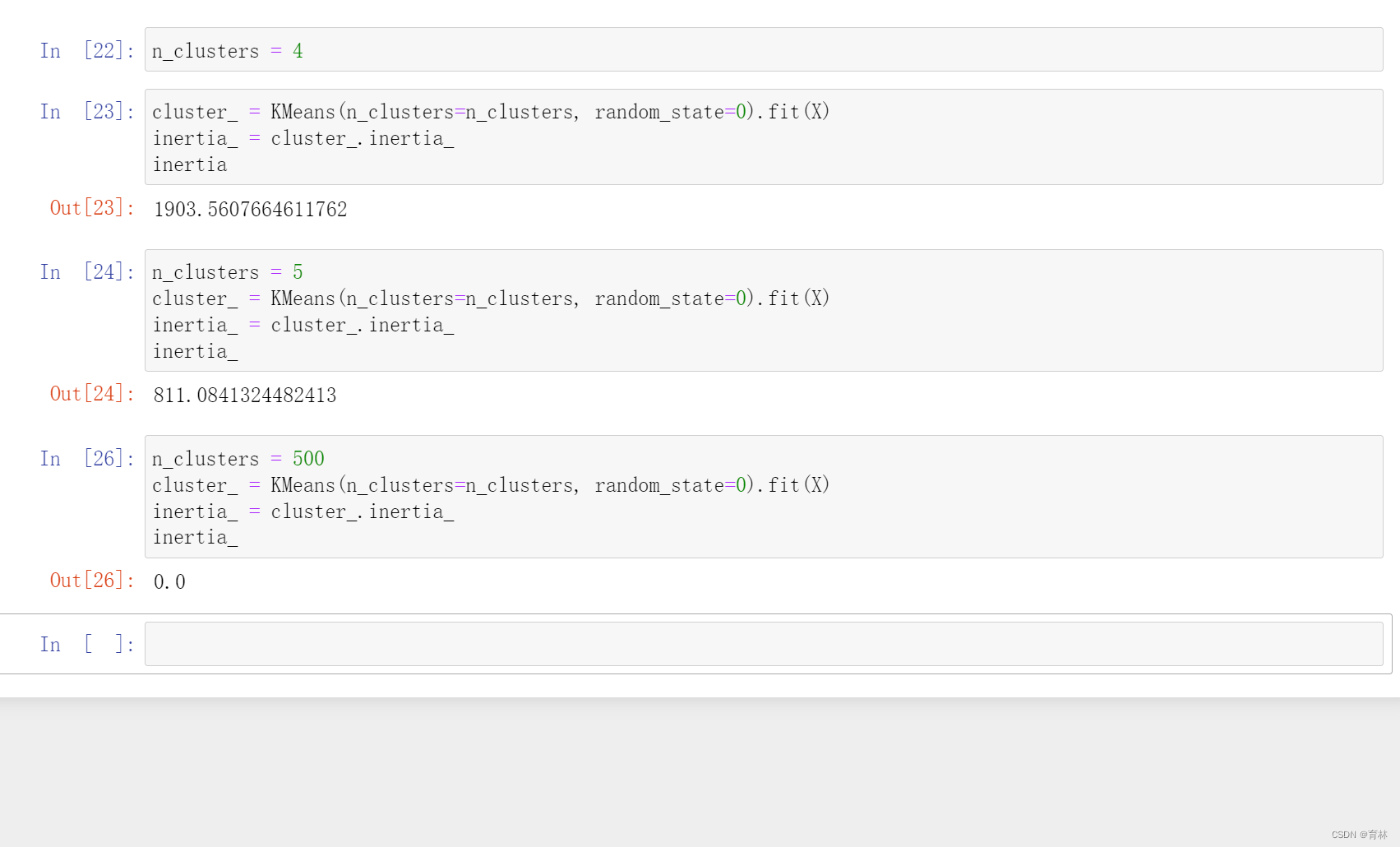
二、 聚类算法的模型评估指标

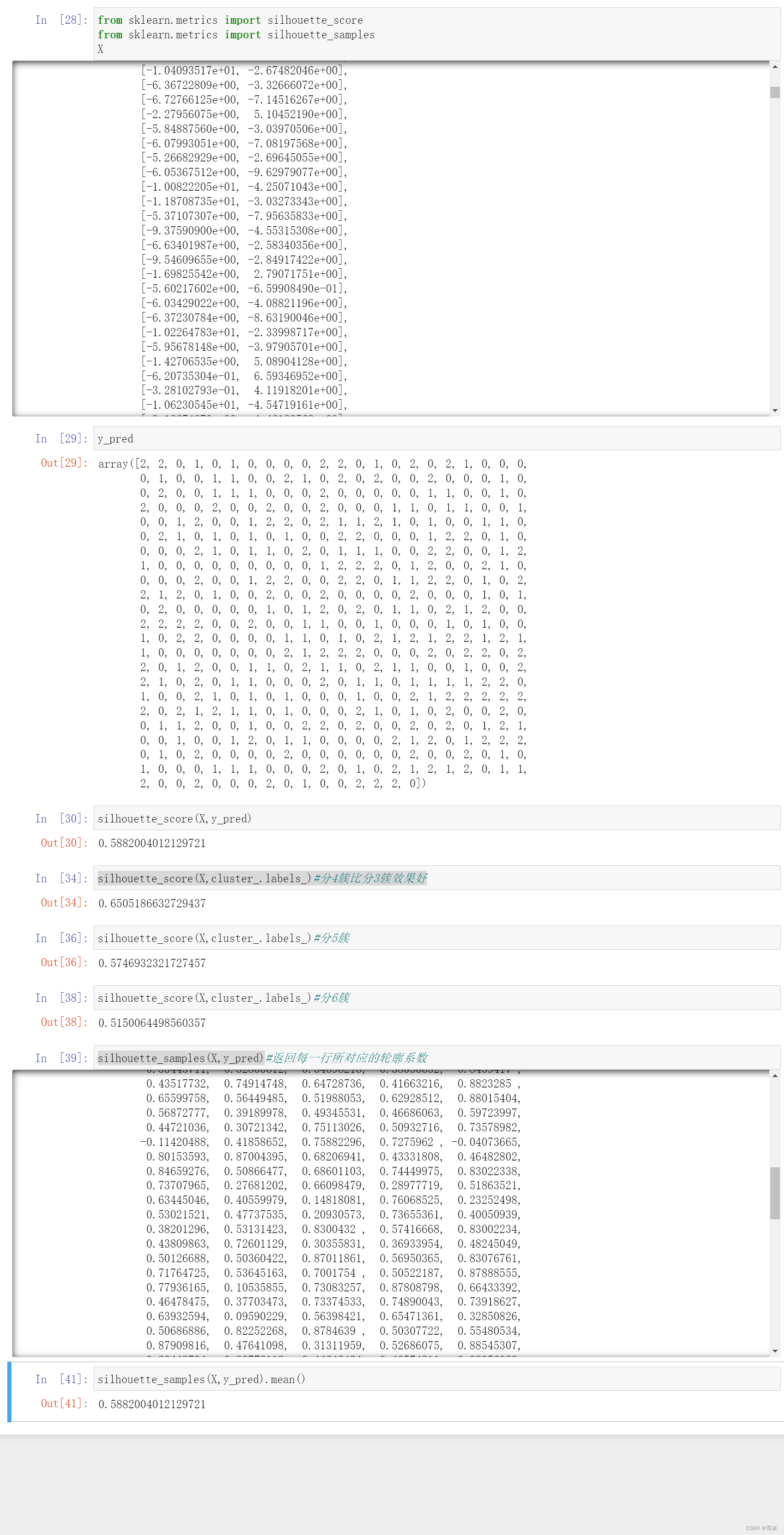
轮廓系数有很多优点,它在有限空间中取值,使得我们对模型的聚类效果有一个“参考”。并且,轮廓系数对数据的分布没有假设,因此在很多数据集上都表现良好。但它在每个簇的分割比较清洗时表现最好。但轮廓系数也有缺陷,它在凸型的类上表现会虚高,比如基于密度进行的聚类,或通过DBSCAN获得的聚类结果,如果使用轮廓系数来衡量,则会表现出比真实聚类效果更高的分数。
基于轮廓系数来选择n_clusters
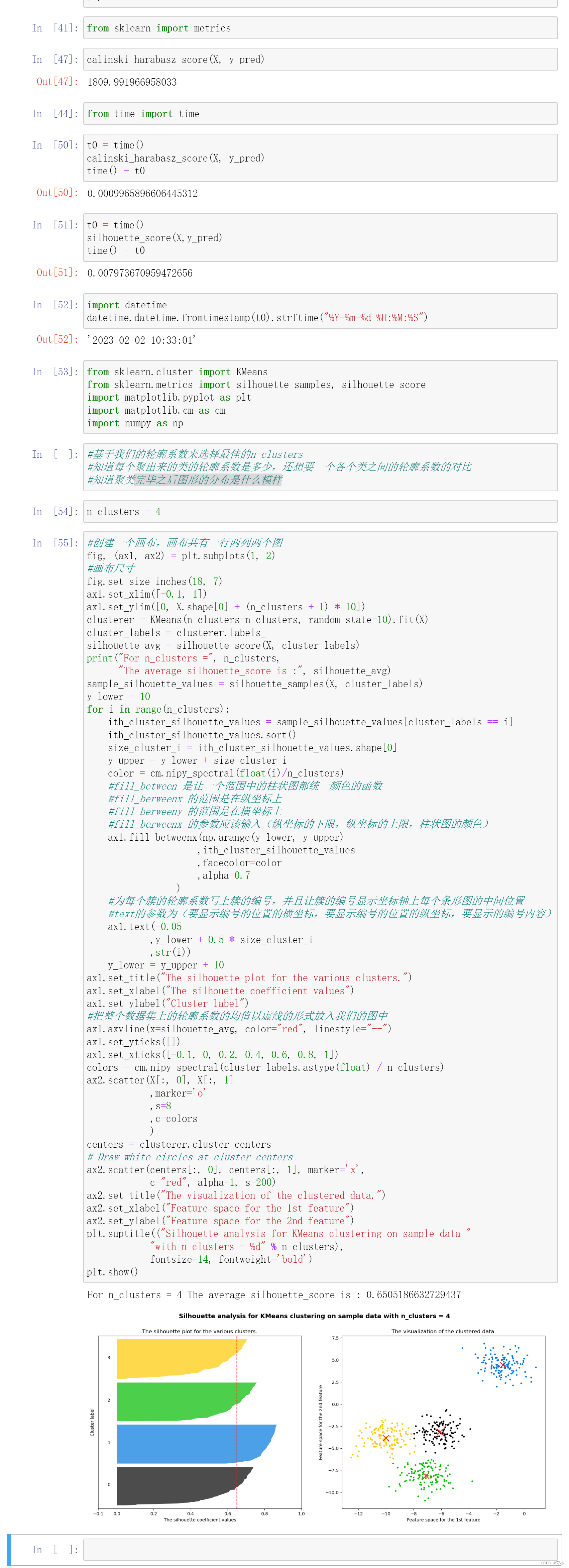
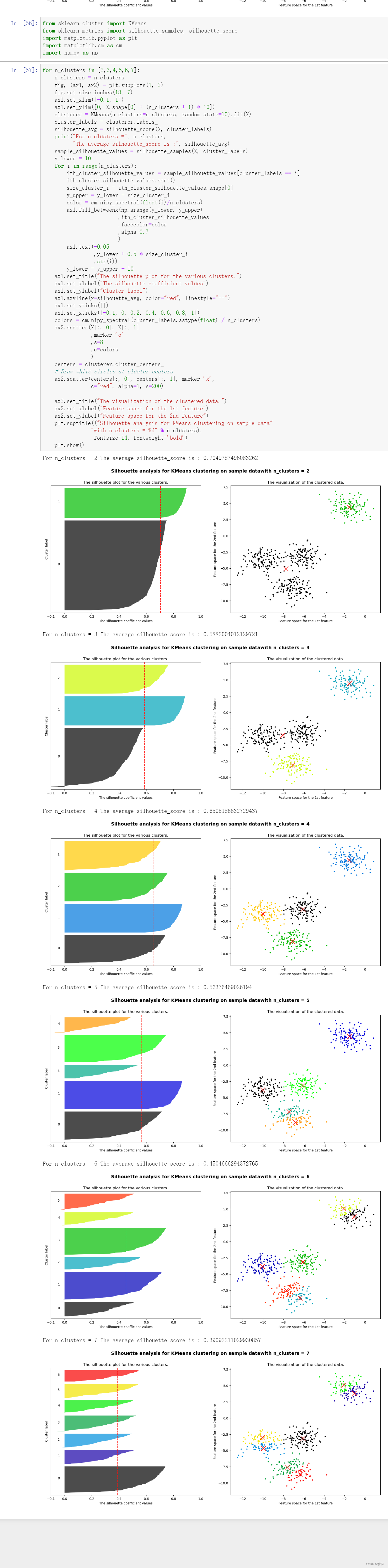
三、重要参数init & random_state & n_init:初始质心怎么放好?
init:可输入"k-means++“,“random"或者一个n维数组。这是初始化质心的方法,默认"k-means++”。输入"kmeans++”:一种为K均值聚类选择初始聚类中心的聪明的办法,以加速收敛。如果输入了n维数组,数组的形状应该是(n_clusters,n_features)并给出初始质心。
random_state:控制每次质心随机初始化的随机数种子
n_init:整数,默认10,使用不同的质心随机初始化的种子来运行k-means算法的次数。最终结果会是基于Inertia来计算的n_init次连续运行后的最佳输出
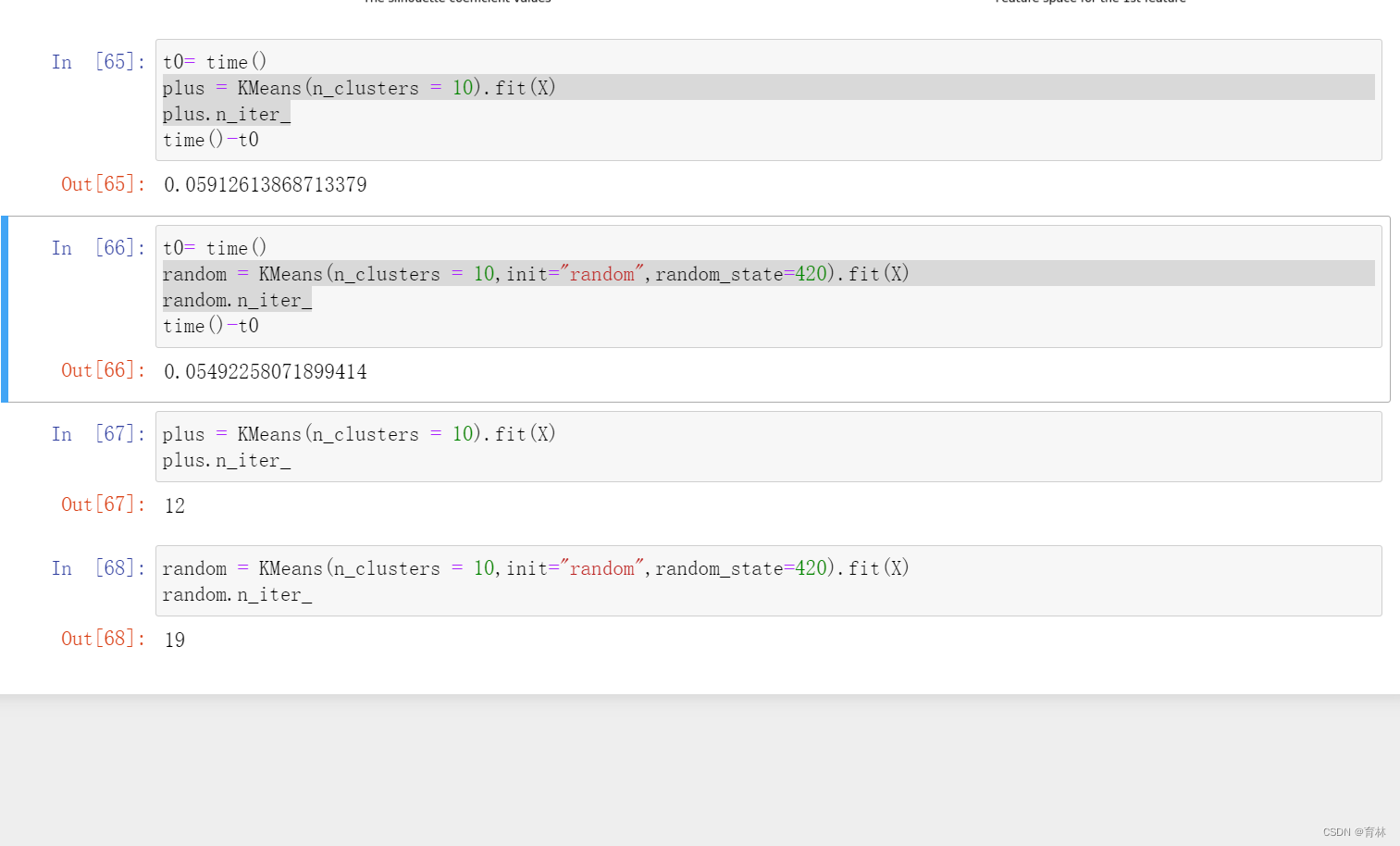
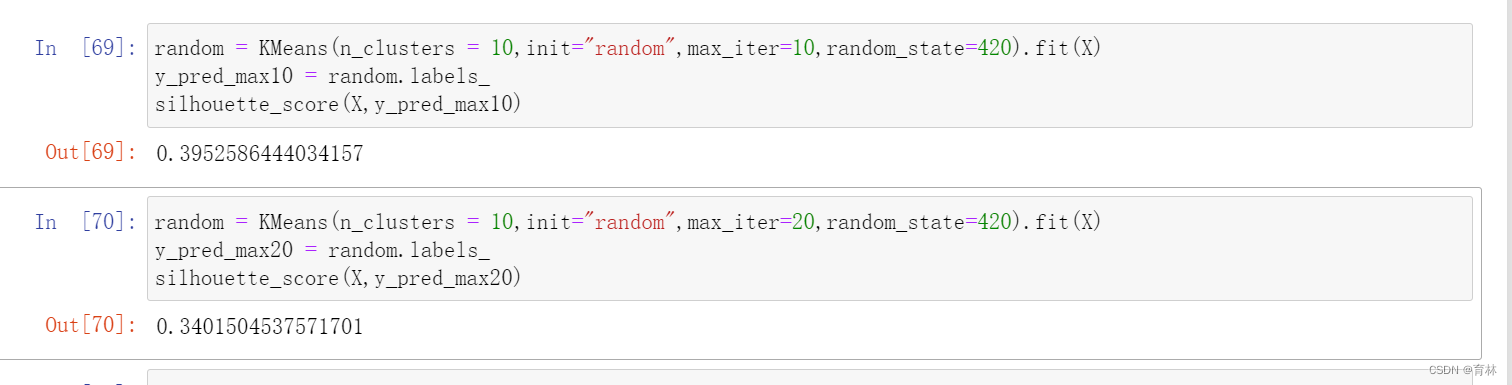
四、重要参数max_iter & tol:让迭代停下来
在之前描述K-Means的基本流程时我们提到过,当质心不再移动,Kmeans算法就会停下来。但在完全收敛之前,我们也可以使用max_iter,最大迭代次数,或者tol,两次迭代间Inertia下降的量,这两个参数来让迭代提前停下来。有时候,当我们的n_clusters选择不符合数据的自然分布,或者我们为了业务需求,必须要填入与数据的自然分布不合的n_clusters,提前让迭代停下来反而能够提升模型的表现。
max_iter:整数,默认300,单次运行的k-means算法的最大迭代次数
tol:浮点数,默认1e-4,两次迭代间Inertia下降的量,如果两次迭代之间Inertia下降的值小于tol所设定的值,迭代就会停下
五、K_Means 函数
六、案例:聚类算法用于降维,KMeans的矢量量化应用
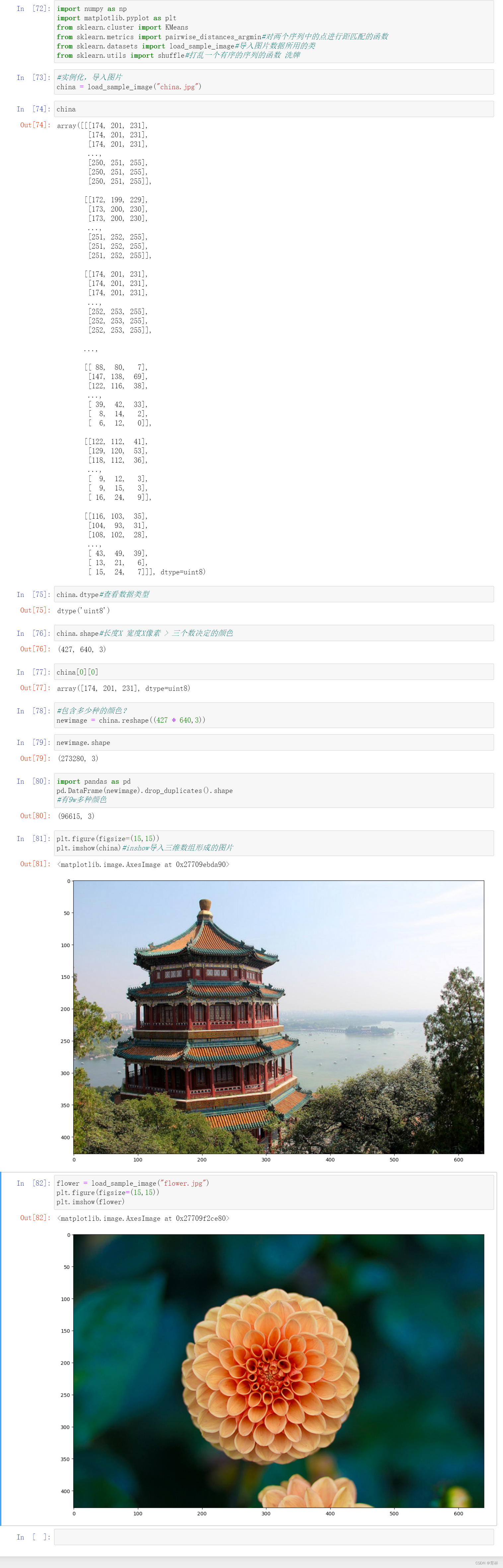

结论: 无论有结尾,只要维度之间相乘后的总数据量不变,维度可以随意变换















 2319
2319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









