






文章目录
一、概率类模型的评估指标
1、布里尔分数Brier Score
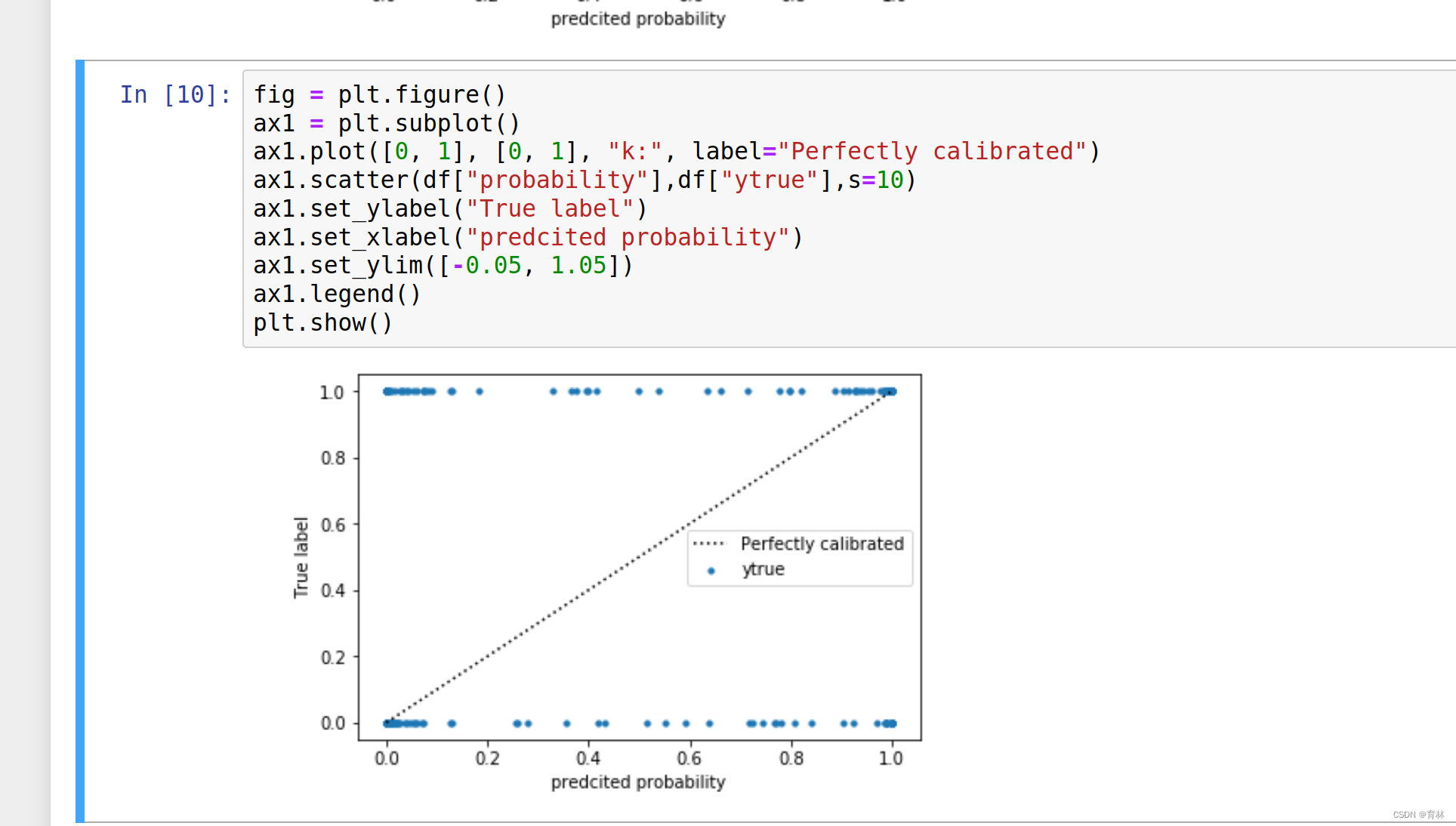
概率预测的准确程度被称为“校准程度”,是衡量算法预测出的概率和真实结果的差异的一种方式。一种比较常用的指标叫做布里尔分数,它被计算为是概率预测相对于测试样本的均方误差,表示为:
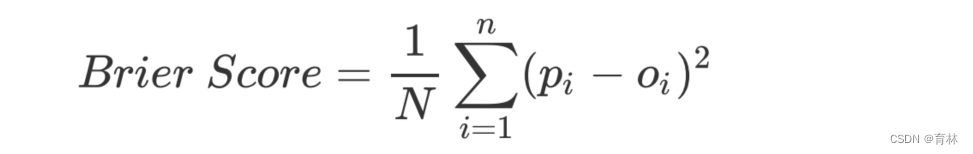
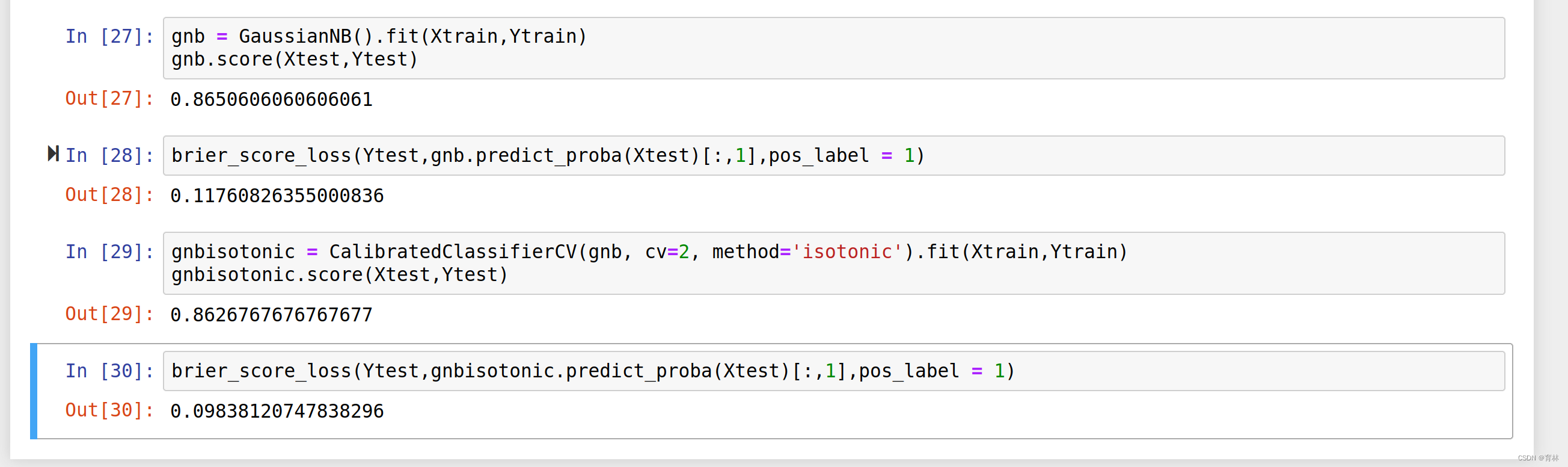
其中N是样本数量, 为朴素贝叶斯预测出的概率, 是样本所对应的真实结果,只能取到0或者1,如果事件发生则为1,如果不发生则为0。这个指标衡量了我们的概率距离真实标签结果的差异,其实看起来非常像是均方误差。布里尔分数的范围是从0到1,分数越高则预测结果越差劲,校准程度越差,因此布里尔分数越接近0越好。由于它的本质也是在衡量一种损失,所以在sklearn当中,布里尔得分被命名为brier_score_loss。
对数似然函数Log Loss
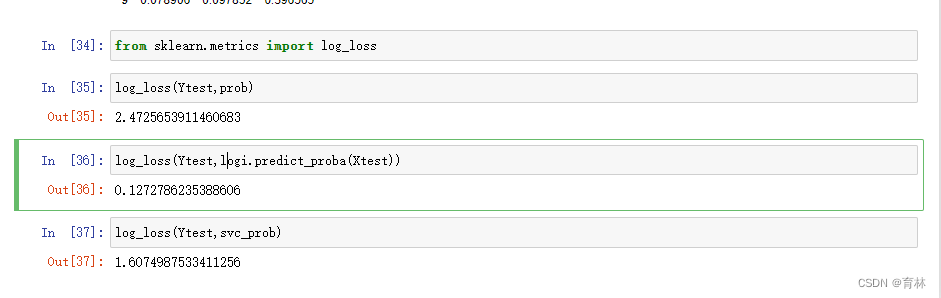
另一种常用的概率损失衡量是对数损失(log_loss),又叫做对数似然,逻辑损失或者交叉熵损失,它是多元逻辑回归以及一些拓展算法,比如神经网络中使用的损失函数。它被定义为,对于一个给定的概率分类器,在预测概率为条件的情况下,真实概率发生的可能性的负对数(如何得到这个损失函数的证明过程和推导过程在逻辑回归的章节中有完整得呈现)。由于是损失,因此对数似然函数的取值越小,则证明概率估计越准确,模型越理想。值得注意得是,对数损失只能用于评估分类型模型。对于一个样本,如果样本的真实标签yture 在{0,1}中取值,并且这个样本在类别1下的概率估计为ypred ,则这个样本所对应的对数损失是:
二、
calibration_curve:

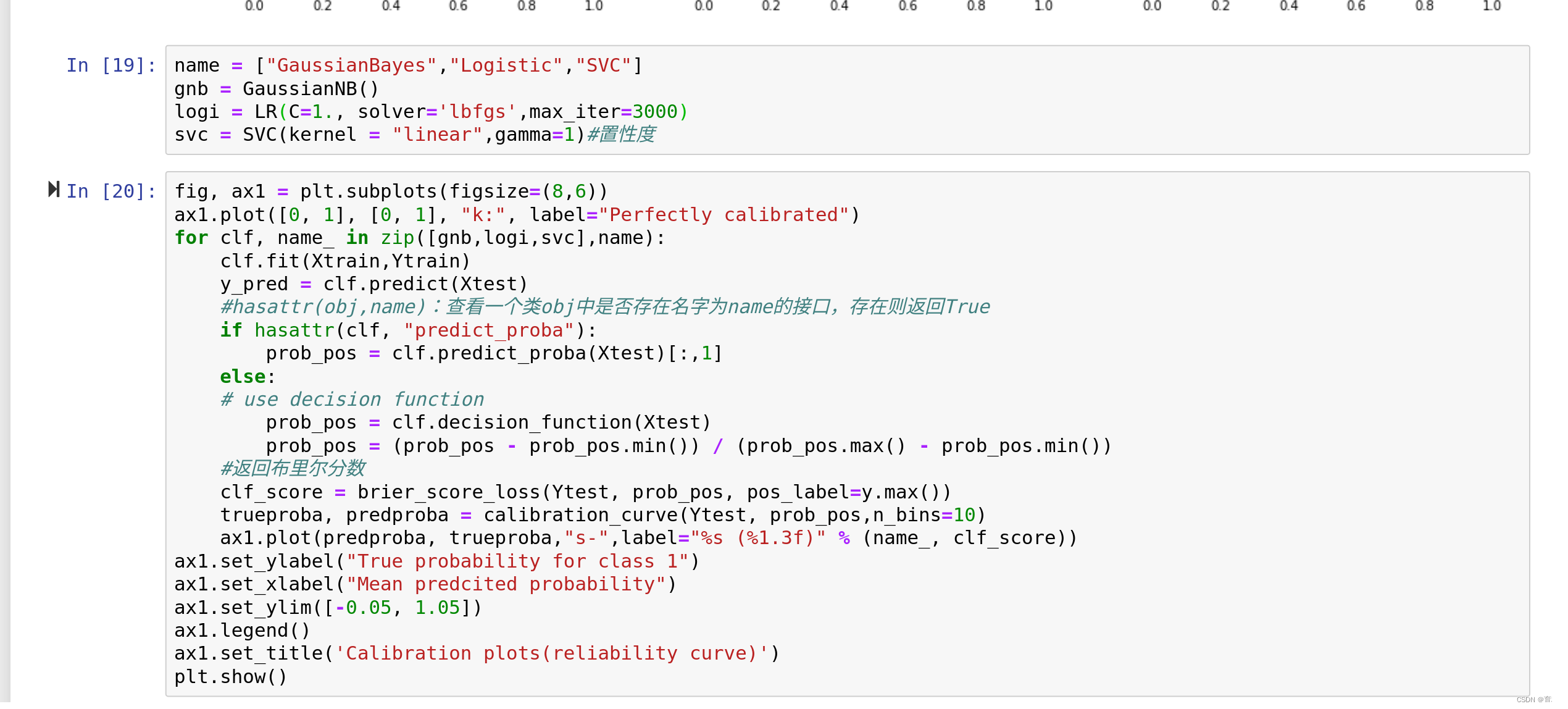
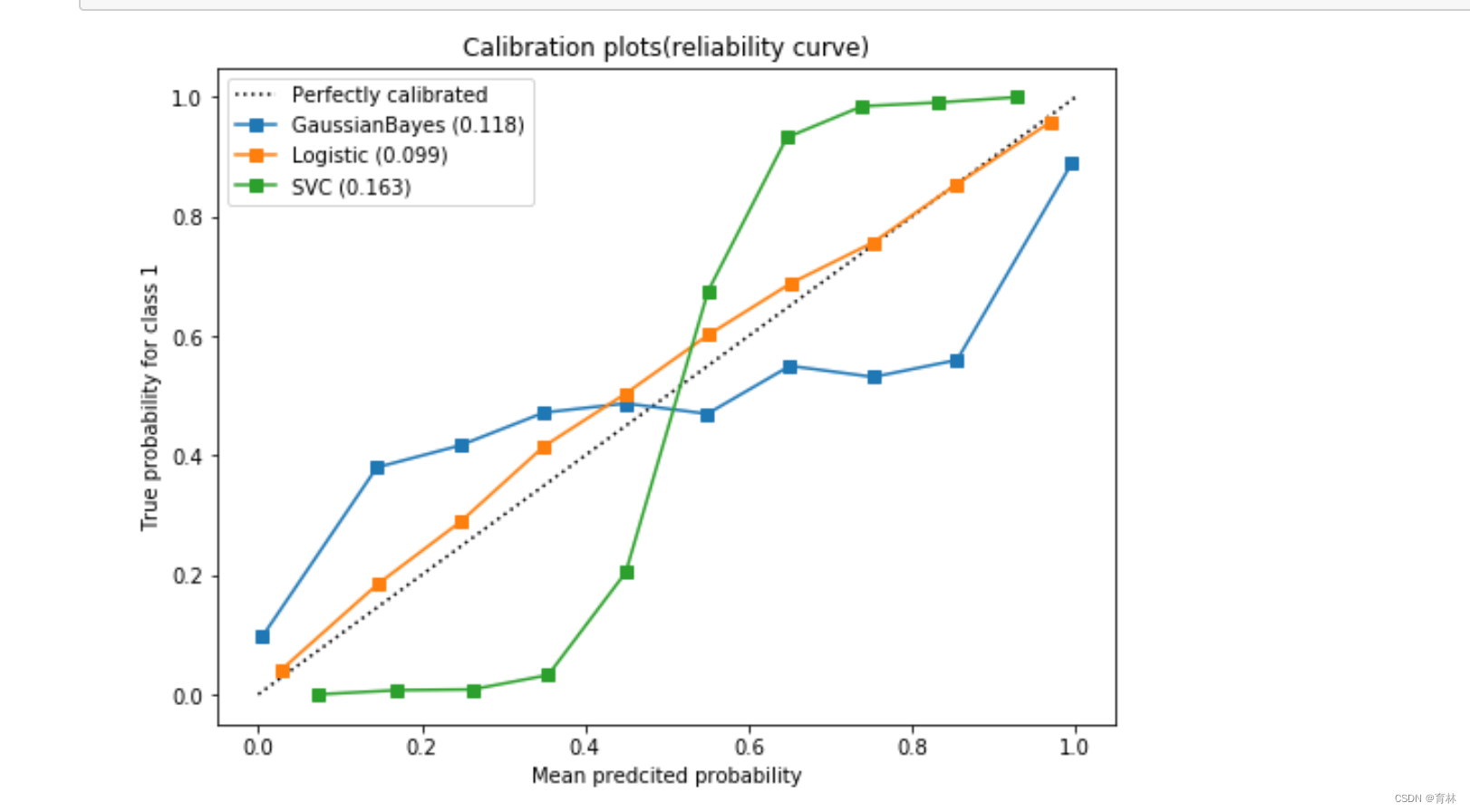
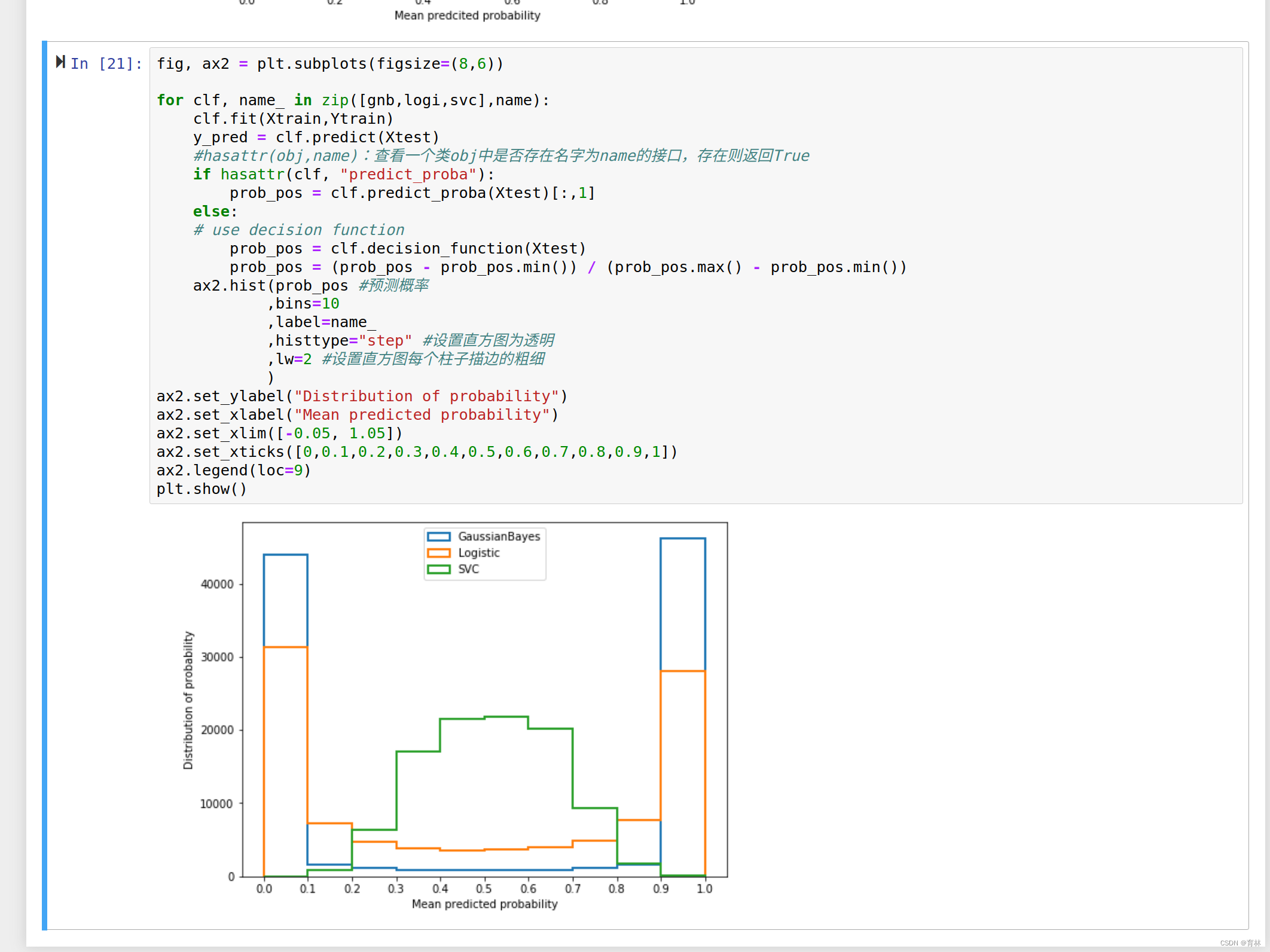
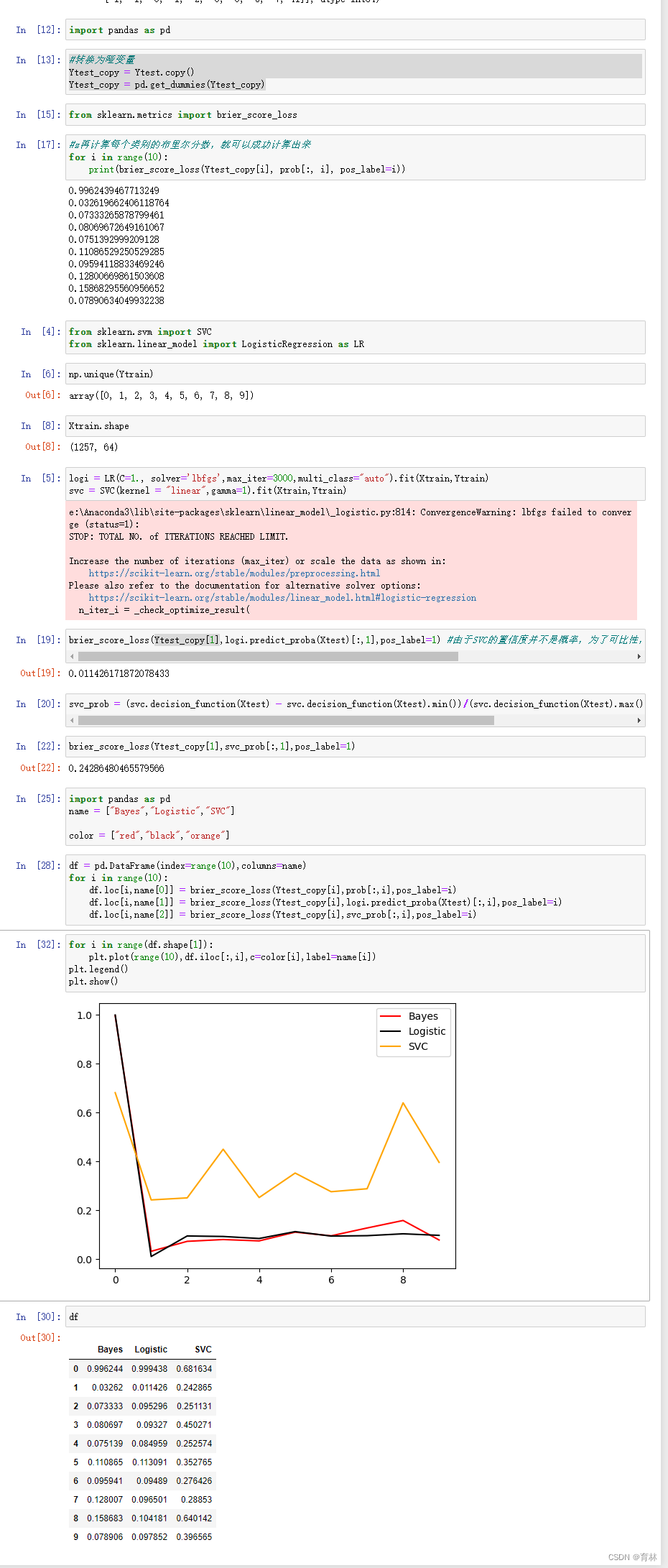
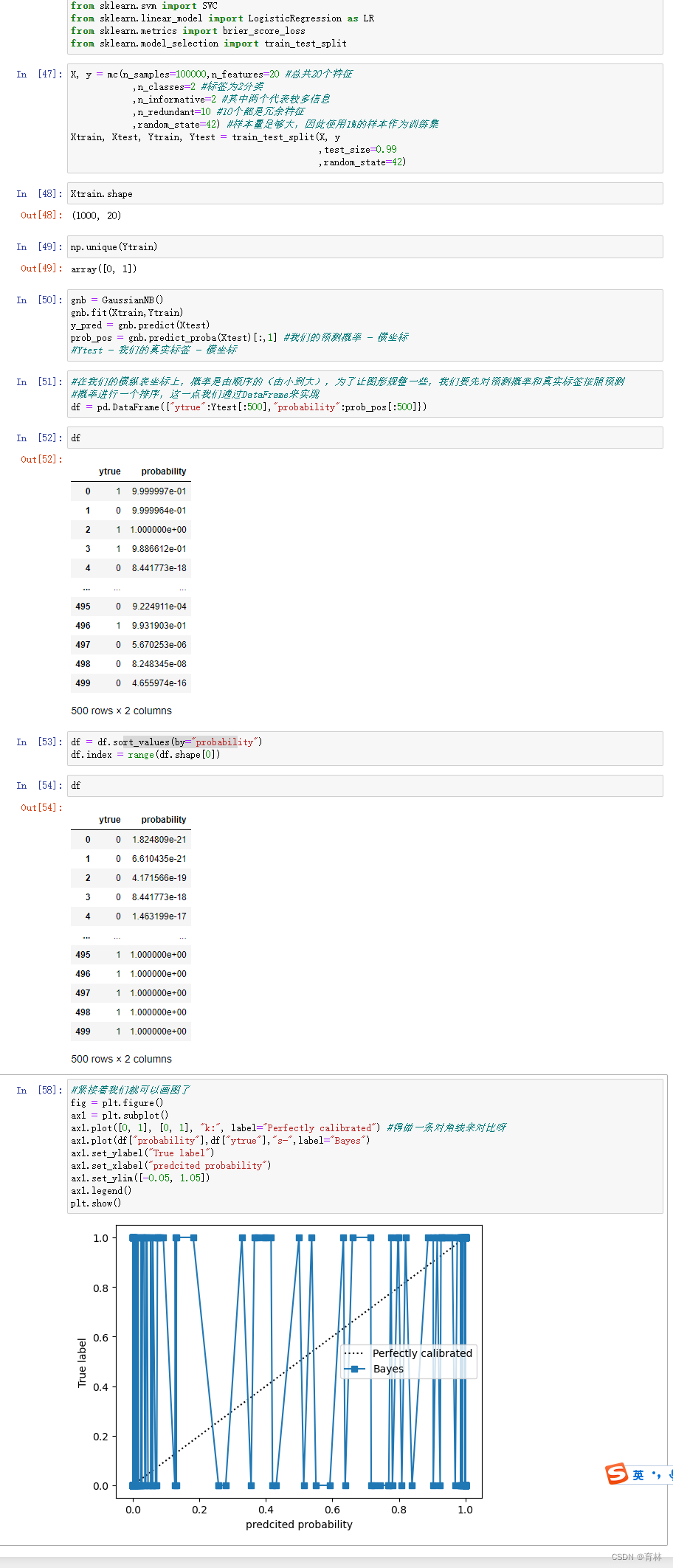
可以看到,高斯贝叶斯的概率分布是两边非常高,中间非常低,几乎90%以上的样本都在0和1的附近,可以说是置信度最高的算法,但是贝叶斯的布里尔分数却不如逻辑回归,这证明贝叶斯中在0和1附近的样本中有一部分是被分错的。支持向量贝叶斯完全相反,明显是中间高,两边低,类似于正态分布的状况,证明了我们刚才所说的,大部分样本都在决策边界附近,置信度都徘徊在0.5左右的情况。而逻辑回归位于高斯朴素贝叶斯和支持向量机的中间,即没有太多的样本过度靠近0和1,也没有形成像支持向量机那样的正态分布。一个比较健康的正样本的概率分布,就是逻辑回归的直方图显示出来的样子。
避免混淆:概率密度曲线和概率分布直方图
大家也许还记得我们说过,我们是假设样本的概率分布为高斯分布,然后使用高斯的方程来估计连续型变量的概率。怎么现在我们绘制出的概率分布结果中,高斯普斯贝叶斯的概率分布反而完全不是高斯分布了呢?注意,千万不要把概率密度曲线和概率分布直方图混淆。
在称重汉堡的时候所绘制的曲线,是概率密度曲线,横坐标是样本的取值,纵坐标是落在这个样本取值区间中的样本个数,衡量的是每个X的取值区间之内有多少样本。服从高斯分布的是X的取值上的样本分布。
现在我们的概率分布直方图,横坐标是概率的取值[0,1],纵坐标是落在这个概率取值范围中的样本的个数,衡量的是每个概率取值区间之内有多少样本。这个分布,是没有任何假设的。
校准可靠性曲线
在这里,我主要来为大家展示如果使用sklearn中的概率校正类CalibratedClassifierCV来对二分类情况下的数据集进行概率校正。
class sklearn.calibration.CalibratedClassifierCV (base_estimator=None, method=’sigmoid’, cv=’warn’)这是一个带交叉验证的概率校准类,它使用交叉验证生成器,对交叉验证中的每一份数据,它都在训练样本上进行模型参数估计,在测试样本上进行概率校准,然后为我们返回最佳的一组参数估计和校准结果。每一份数据的预测概率会被求解平均。注意,类CalibratedClassifierCV没有接口decision_function,要查看这个类下校准过后的模型生成的概率,必须调用predict_proba接口。
base_estimator
需要校准其输出决策功能的分类器,必须存在predict_proba或decision_function接口。 如果参数cv = prefit,分类器必须已经拟合数据完毕。
cv
整数,确定交叉验证的策略。可能输入是:
None,表示使用默认的3折交叉验证
任意整数,指定折数
对于输入整数和None的情况下来说,如果时二分类,则自动使用类sklearn.model_selection.StratifiedKFold进
行折数分割。如果y是连续型变量,则使用sklearn.model_selection.KFold进行分割。
已经使用其他类建好的交叉验证模式或生成器cv
可迭代的,已经分割完毕的测试集和训练集索引数组
输入"prefit",则假设已经在分类器上拟合完毕数据。在这种模式下,使用者必须手动确定用来拟合分类器的数
据与即将倍校准的数据没有交集
在版本0.20中更改:在0.22版本中输入“None”,将由使用3折交叉验证改为5折交叉验证
method
进行概率校准的方法,可输入"sigmoid"或者"isotonic"
输入’sigmoid’,使用基于Platt的Sigmoid模型来进行校准
输入’isotonic’,使用等渗回归来进行校准
当校准的样本量太少(比如,小于等于1000个测试样本)的时候,不建议使用等渗回归,因为它倾向于过拟合。样本量过少时请使用sigmoids,即Platt校准。
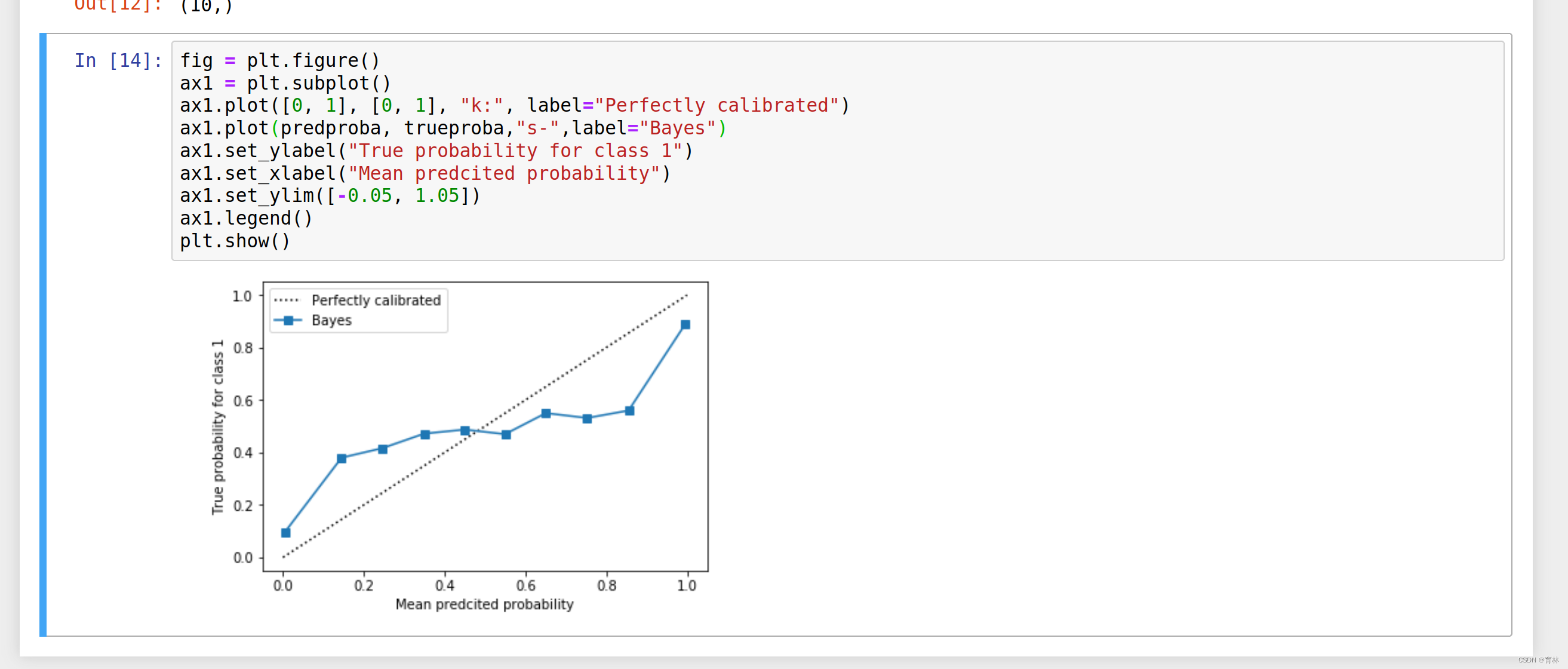
我们依然来使用之前建立的数据集。
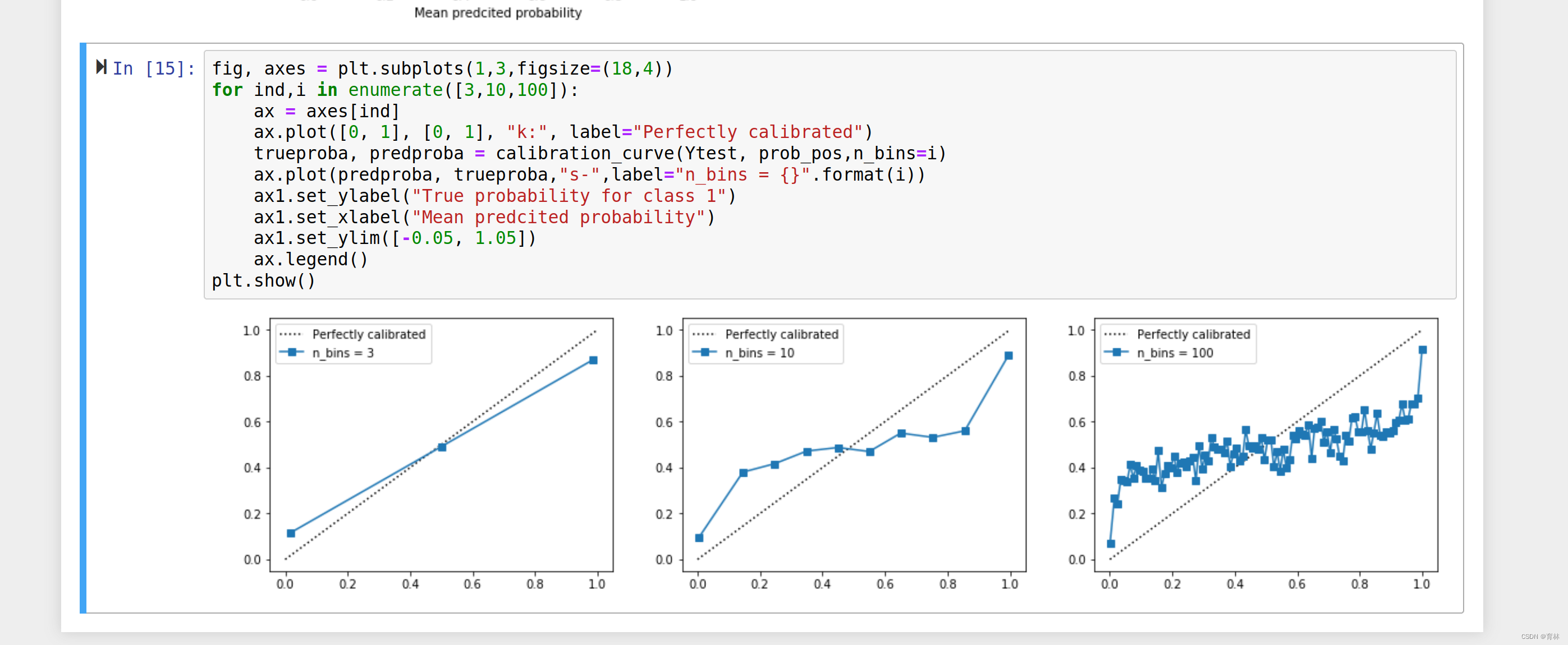
def plot_calib(models,name,Xtrain,Xtest,Ytrain,Ytest,n_bins=10):
import matplotlib.pyplot as plt
from sklearn.metrics import brier_score_loss
from sklearn.calibration import calibration_curve
fig, (ax1, ax2) = plt.subplots(1, 2,figsize=(20,6))
ax1.plot([0, 1], [0, 1], "k:", label="Perfectly calibrated")
for clf, name_ in zip(models,name):
clf.fit(Xtrain,Ytrain)
y_pred = clf.predict(Xtest)
#hasattr(obj,name):查看一个类obj中是否存在名字为name的接口,存在则返回True
if hasattr(clf, "predict_proba"):
prob_pos = clf.predict_proba(Xtest)[:,1]
else:
# use decision function
prob_pos = clf.decision_function(Xtest)
prob_pos = (prob_pos - prob_pos.min()) / (prob_pos.max() - prob_pos.min())
#返回布里尔分数
clf_score = brier_score_loss(Ytest, prob_pos, pos_label=y.max())
trueproba, predproba = calibration_curve(Ytest, prob_pos,n_bins=n_bins)
ax1.plot(predproba, trueproba,"s-",label="%s (%1.3f)" % (name_, clf_score))
ax2.hist(prob_pos, range=(0, 1), bins=n_bins, label=name_,histtype="step",lw=2)
ax2.set_ylabel("Distribution of probability")
ax2.set_xlabel("Mean predicted probability")
ax2.set_xlim([-0.05, 1.05])
ax2.legend(loc=9)
ax2.set_title("Distribution of probablity")
ax1.set_ylabel("True probability for class 1")
ax1.set_xlabel("Mean predcited probability")
ax1.set_ylim([-0.05, 1.05])
ax1.legend()
ax1.set_title('Calibration plots(reliability curve)')
plt.show()
from sklearn.calibration import CalibratedClassifierCV
name = ["GaussianBayes","Logistic","Bayes+isotonic","Bayes+sigmoid"]
gnb = GaussianNB()
models = [gnb
,LR(C=1., solver='lbfgs',max_iter=3000)
#定义两种校准方式
,CalibratedClassifierCV(gnb, cv=2, method='isotonic')
,CalibratedClassifierCV(gnb, cv=2, method='sigmoid')]
plot_calib(models,name,Xtrain,Xtest,Ytrain,Ytest)
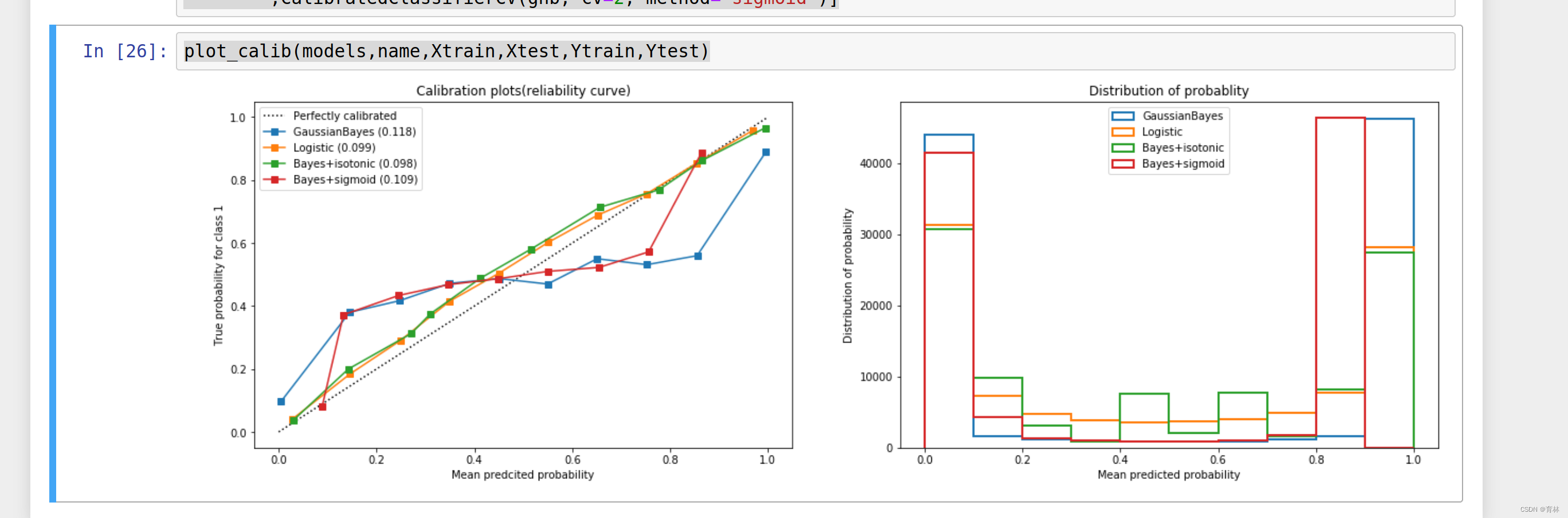
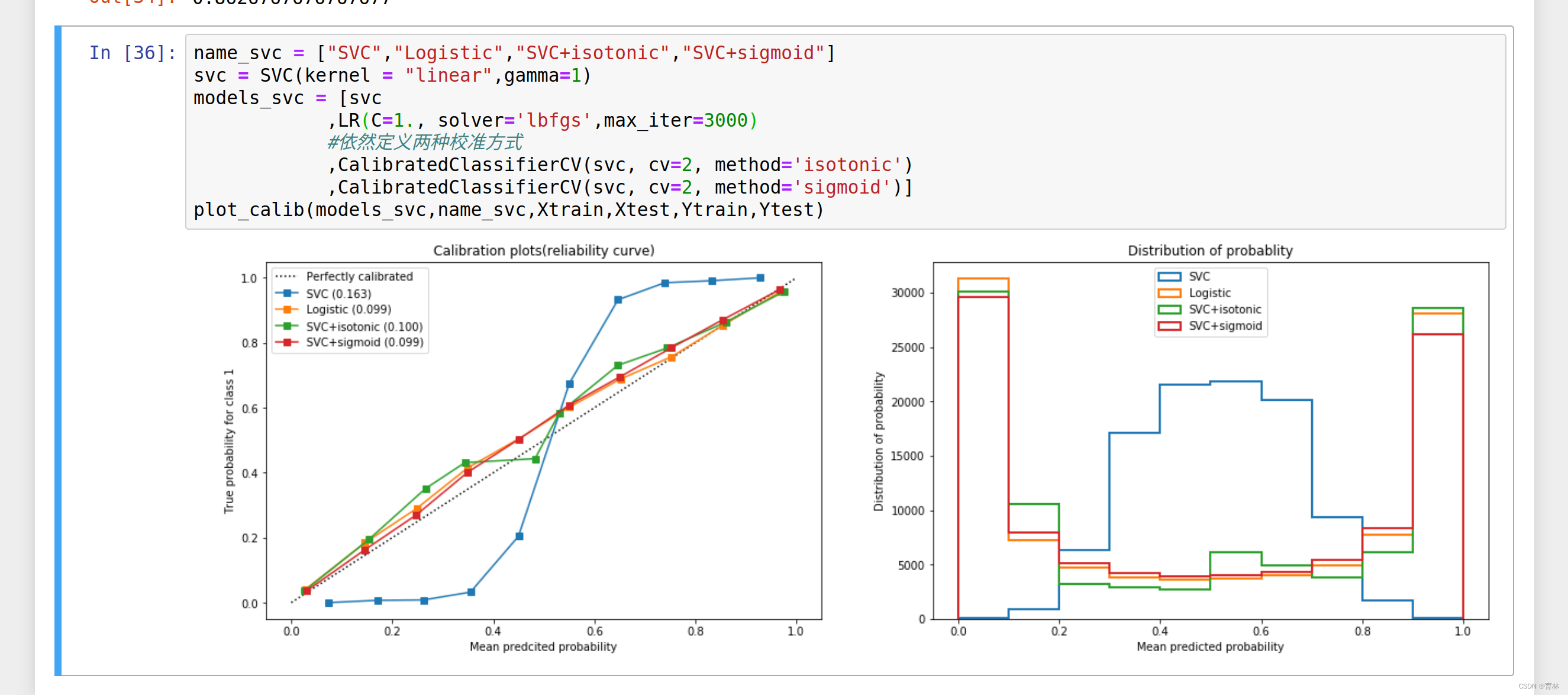
 可以看到,对于SVC来说,两种校正都改善了准确率和布里尔分数。可见,概率校正对于SVC非常有效。这也说明,概率校正对于原本的可靠性曲线是形容Sigmoid形状的曲线的算法比较有效。
可以看到,对于SVC来说,两种校正都改善了准确率和布里尔分数。可见,概率校正对于SVC非常有效。这也说明,概率校正对于原本的可靠性曲线是形容Sigmoid形状的曲线的算法比较有效。
在现实中,我们可以选择调节模型的方向,我们不一定要追求最高的准确率或者追求概率拟合最好,我们可以根据自己的需求来调整模型。当然,对于概率类模型来说,由于可以调节的参数甚少,所以我们更倾向于追求概率拟合,并使用概率校准的方式来调节模型。如果你的确希望追求更高的准确率和Recall,可以考虑使用天生就非常准确的概率类模型逻辑回归,也可以考虑使用除了概率校准之外还有很多其他参数可调的支持向量机分类器。
三、多项式朴素贝叶斯以及其变化
四、伯努利朴素贝叶斯
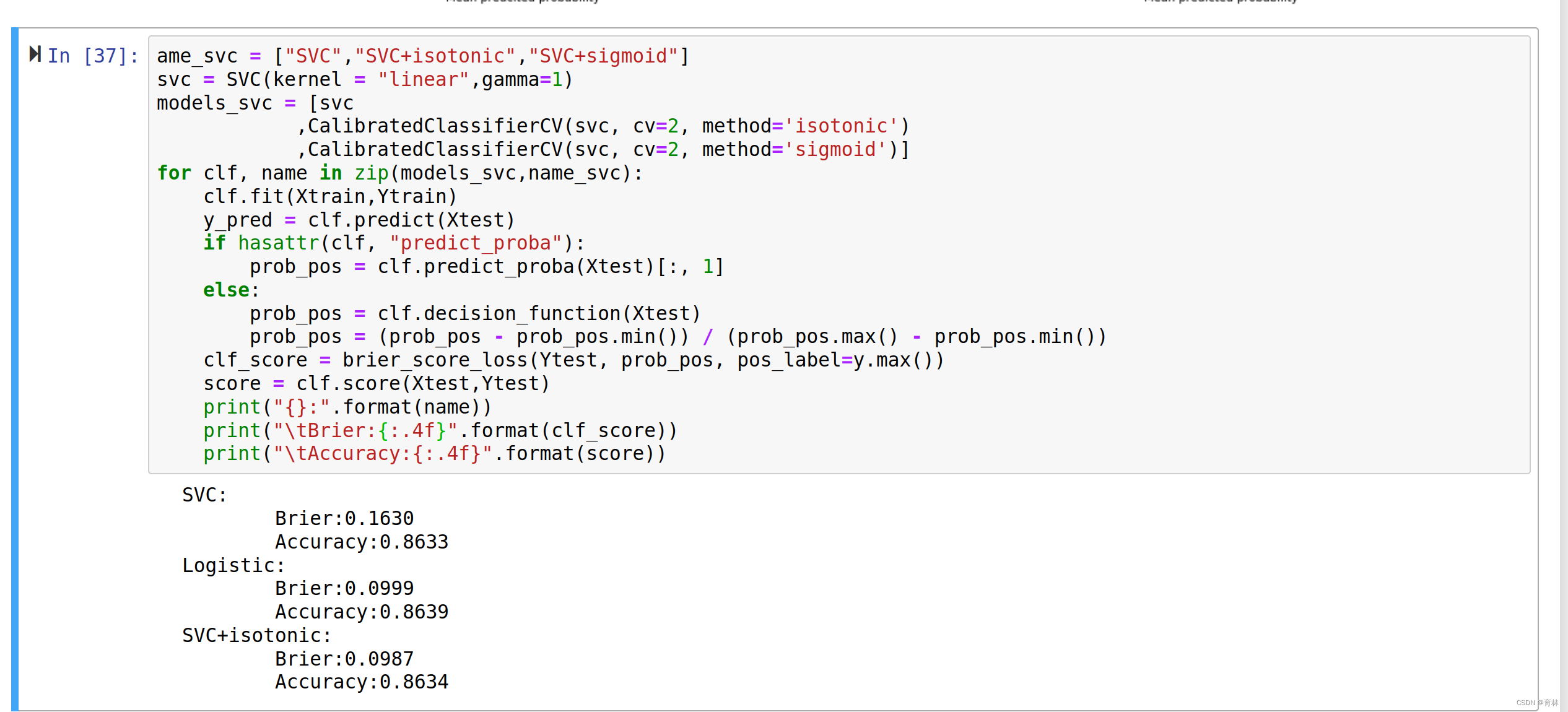
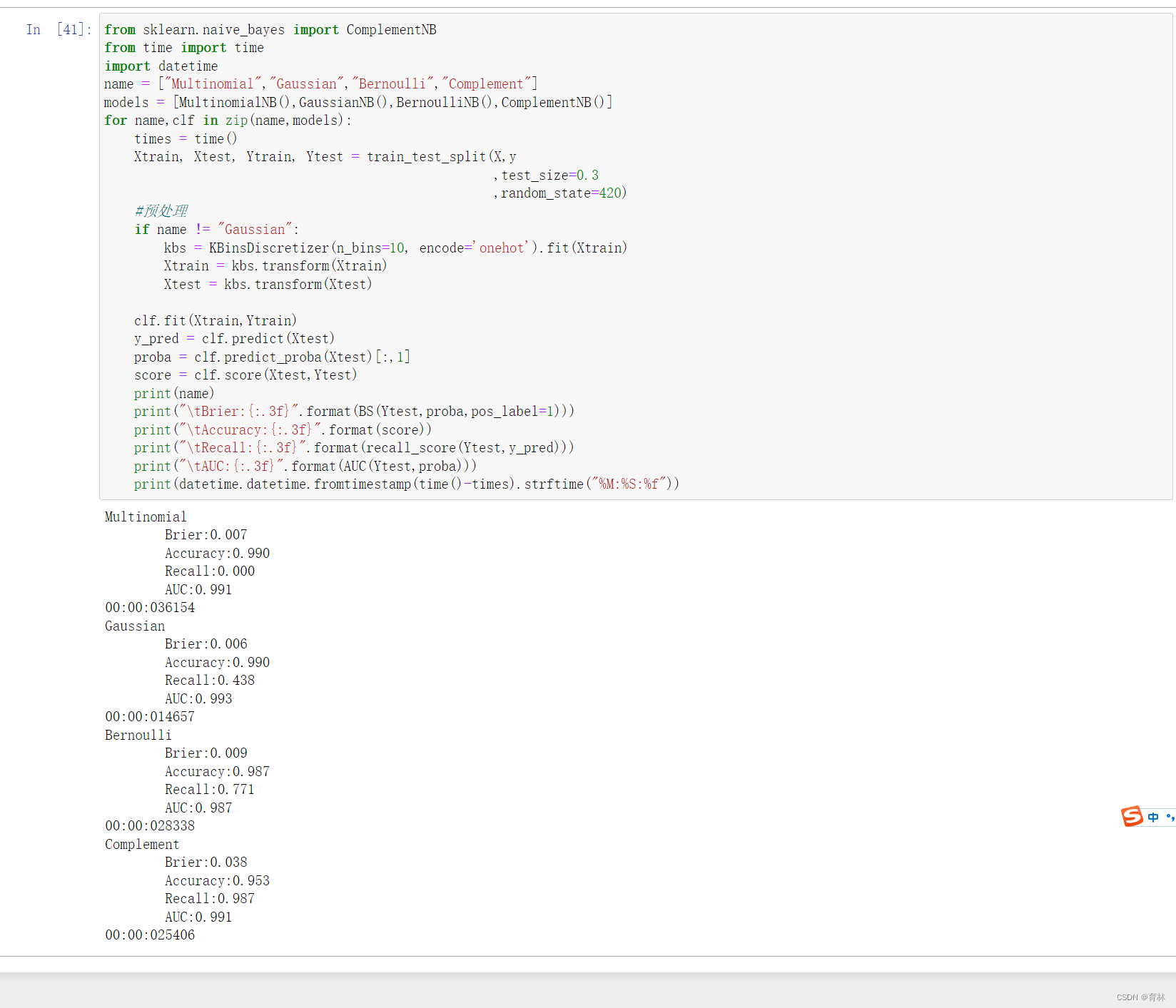
从结果上来看,多项式朴素贝叶斯判断出了所有的多数类样本,但放弃了全部的少数类样本,受到样本不均衡问题影响最严重。高斯比多项式在少数类的判断上更加成功一些,至少得到了43.8%的recall。伯努利贝叶斯虽然整体的准确度和布里尔分数不如多项式和高斯朴素贝叶斯和,但至少成功捕捉出了77.1%的少数类。可见,伯努利贝叶斯最能够忍受样本不均衡问题。
可是,伯努利贝叶斯只能用于处理二项分布数据,在现实中,强行将所有的数据都二值化不会永远得到好结果,在我们有多个特征的时候,我们更需要一个个去判断究竟二值化的阈值该取多少才能够让算法的效果优秀。这样做无疑是非常低效的。那如果我们的目标是捕捉少数类,我们应该怎么办呢?高斯朴素贝叶斯的效果虽然比多项式好,但是也没有好到可以用来帮助我们捕捉少数类的程度——43.8%,还不如抛硬币的结果。因此,孜孜不倦的统计学家们改进了朴素贝叶斯算法,修正了包括无法处理样本不平衡在内的传统朴素贝叶斯的众多缺点,得到了新兴贝叶斯算法:补集朴素贝叶斯
五、改进多项式朴素贝叶斯:补集朴素贝叶斯ComplementNB
六、文本分类案例
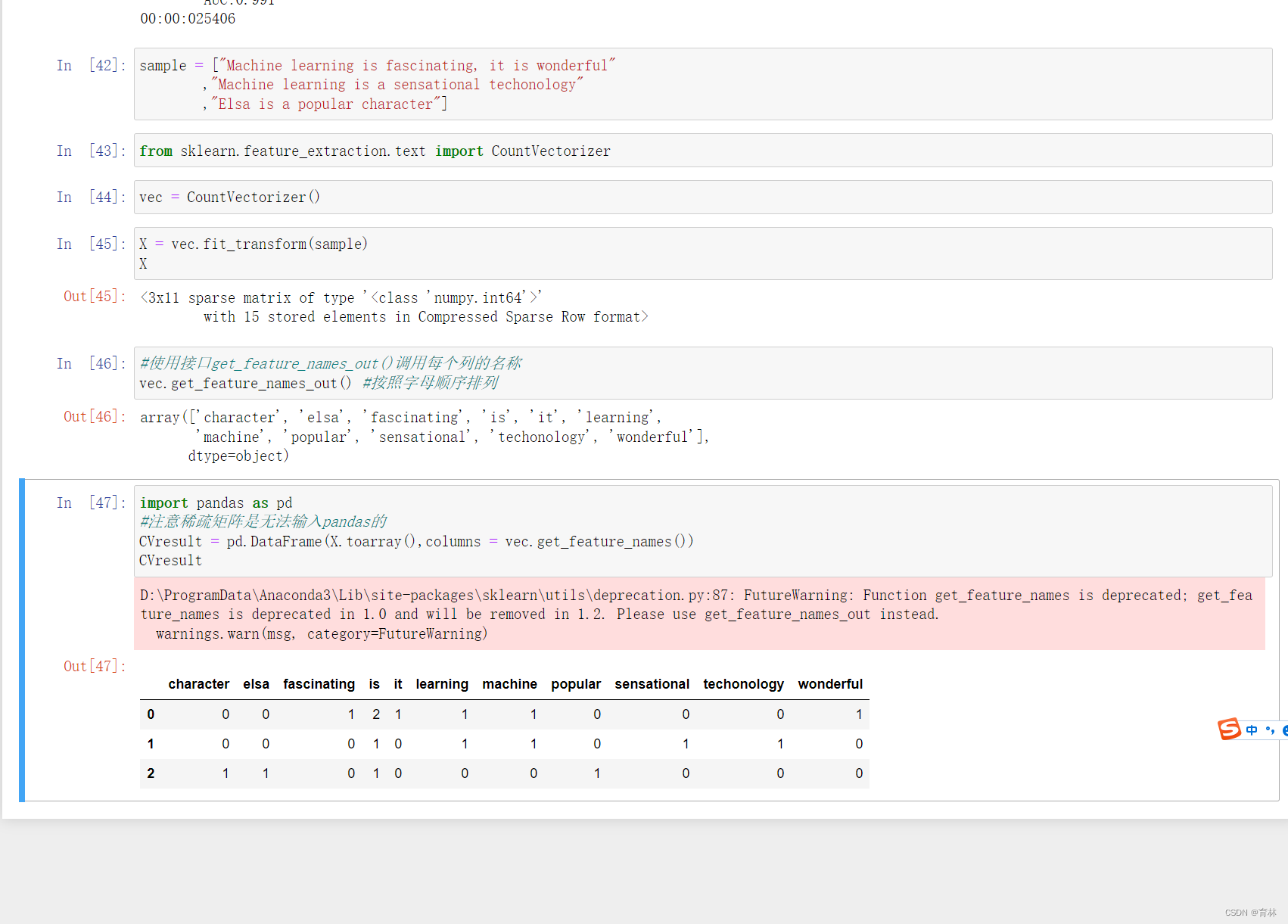
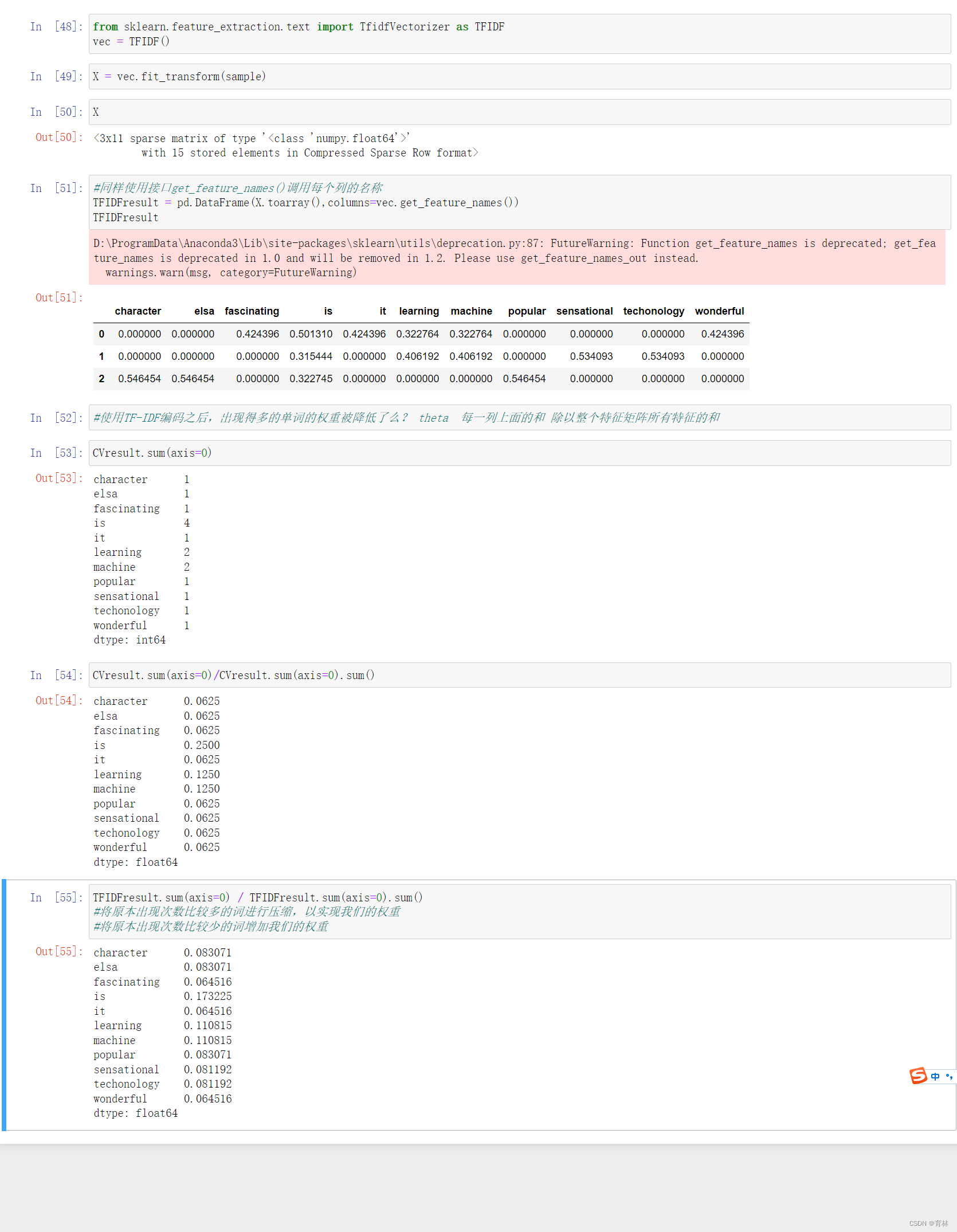
TF-IDF
TF-IDF全称term frequency-inverse document frequency,词频逆文档频率,是通过单词在文档中出现的频率来衡量其权重,也就是说,IDF的大小与一个词的常见程度成反比,这个词越常见,编码后为它设置的权重会倾向于越小,以此来压制频繁出现的一些无意义的词。在sklearn当中,我们使用feature_extraction.text中类TfidfVectorizer来执行这种编码。
sklearn.datasets.fetch_20newsgroups (data_home=None, subset=’train’, categories=None, shuffle=True,
random_state=42, remove=(), download_if_missing=True)

总结
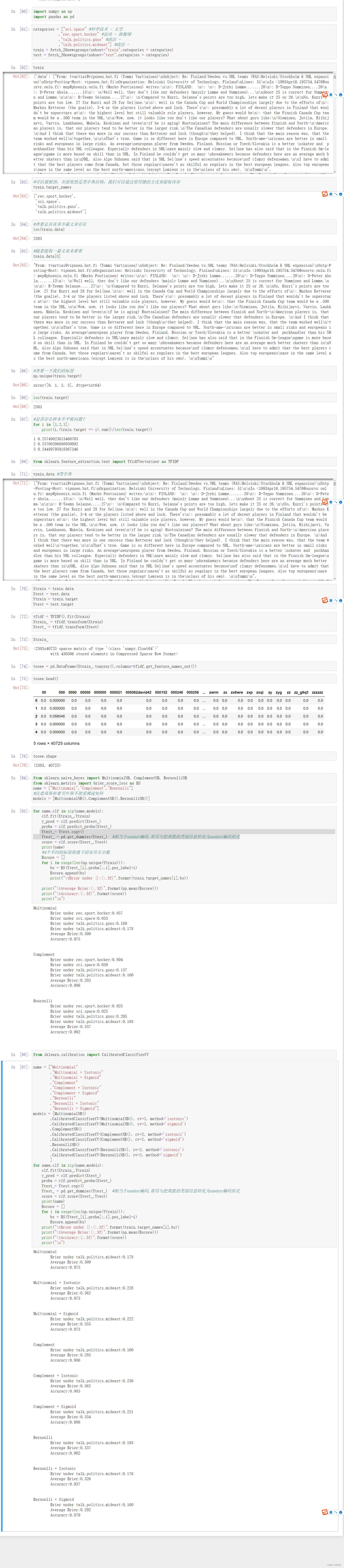
可以观察到,多项式分布下无论如何调整,算法的效果都不如补集朴素贝叶斯来得好。因此我们在分类的时候,应该选择补集朴素贝叶斯。对于补集朴素贝叶斯来说,使用Sigmoid进行概率校准的模型综合最优秀:准确率最高,对数损失和布里尔分数都在0.1以下,可以说是非常理想的模型了。
对于机器学习而言,朴素贝叶斯也许不是最常用的分类算法,但作为概率预测算法中唯一一个真正依赖概率来进行计算,并且简单快捷的算法,朴素贝叶斯还是常常被人们提起。并且,朴素贝叶斯在文本分类上的效果的确非常优秀。由此可见,只要我们能够提供足够的数据,合理利用高维数据进行训练,朴素贝叶斯就可以为我们提供意想不到的效果。














 5642
5642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









