






经过前面几个步骤,模型部署的相关环境以及必要条件都已准备就绪,接下来我使用自己的模型做部署测试:
1.模型转换
我这里使用的模型为一个人脸检测模型,由于模型为公司内部模型未开源,所以这里就演示整个开发的过程,其他模型同理;
此模型为一输入两输出结构的网络,模型格式为.onnx,依次进行以下操作:
(1)导入模型:
pegasus import onnx --model face.onnx --output-model face.json --output-data face.data
(2)生成yml文件:
输入预处理yml文件
pegasus generate inputmeta --model face.json --input-meta-output face_inputmeta.yml
输出后处理yml文件
pegasus generate postprocess-file --model face.json --postprocess-file-output face_postprocess_file.yml
这两个文件要根据自己的模型做相应修改,一般是修改inputmeta.yml,也就是根据自己的模型的预处理的不同来修改;这里的我的模型预处理主要是做了减均值,然后输入格式为uint8格式,所以我做了下面两处修改:
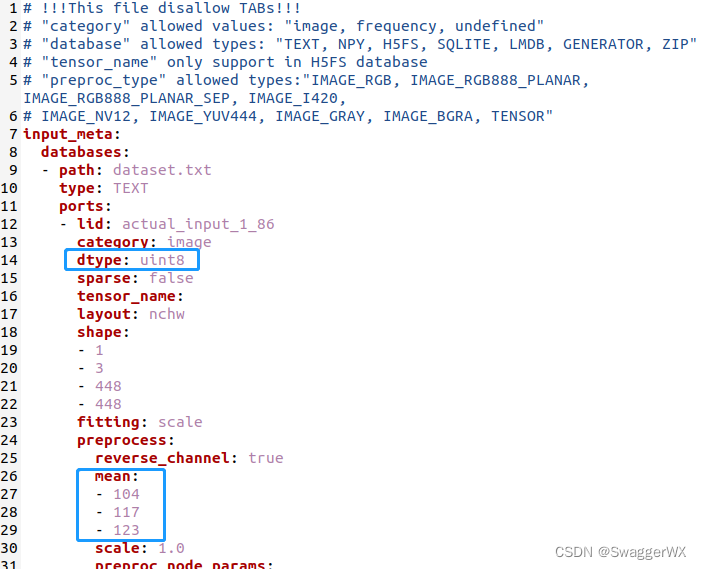
(3)量化:
在量化之前要准备好dataset.txt文件,这里我准备了一张图片放入到dataset.txt中(我尝试放入多张图片,并且对应设置–batch-size为图片数,但是运行下面指令就会报错,暂时还不知道是啥原因),格式为:
./val/1.jpg 0
同时在同级文件夹下val文件夹中放入1.jpg图片,然后设置–batch-size为1:
pegasus quantize --model face.json --model-data face.data --batch-size 1 --device CPU --with-input-meta face_inputmeta.yml --rebuild --model-quantize face.quantize --quantizer asymmetric_affine --qtype uint8
(4)预推理:
预推理的目的是按照当前所得的模型以及预处理、后处理yml文件,对dataset.txt中所列的图片做推理得到图片的输入数据以及推理后的输出数据,以此可以在软件仿真时,或者部署时提供一个参照:
pegasus inference --model face.json --model-data face.data --batch-size 1 --device CPU --with-input-meta face_inputmeta.yml --postprocess-file face_postprocessmeta.yml
这会生成一个输入文件和两个输出文件。
(5)导出部署模型:
此步骤即可一键导出network_binary.nb格式的部署模型以及部署的模板代码:
pegasus export ovxlib --model face.json --model-data face.data --dtype quantized --model-quantize face.quantize --batch-size 1 --save-fused-graph --target-ide-project 'linux64' --with-input-meta face_inputmeta.yml --output-path ovxilb/face-simprj --pack-nbg-unify --postprocess-file face_postprocessmeta.yml --optimize "VIP9000PICO_PID0XEE" --viv-sdk ${VIV_SDK}
接下来将按照提供的模板代码写个部署demo:
2.模型部署
首先确定全志NPU提供的lib为VIPLite,上个步骤导出的模板代码中也都是调用的VIPLite的接口;建个工程,结构大概如下所示:
└── 3rd
├──libjpeg
├── include
└── lib
└── viplite-driver
├── include
└── lib
├── build
├── CMakeLists.txt
├── inc
│ ├── image_utils.h
│ ├── ssd_helper.h
│ ├── vnn_global.h
│ ├── vnn_logicprocess.h
│ ├── vnn_postprocess.h
│ ├── vnn_preprocess.h
│ └── vnn_runtime.h
└── src
├── image_utils.cpp
├── main.cpp
├── vnn_logicprocess.cpp
├── vnn_postprocess.cpp
├── vnn_preprocess.cpp
└── vnn_runtime.cpp
3rd中主要是存放使用到的两个库的头文件库文件,可以直接从全志提供的TinaSDK中copy就行;
CMakeLists.txt如下:
cmake_minimum_required(VERSION 3.16)
project(v853demo)
set(CMAKE_SYSTEM_NAME Linux)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE "Release")
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fPIC")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -O2 -pthread -fopenmp")
# set arm cross-compiler toolchain
set(TOOLCHAIN_PATH /home/wangxu/wangxu_test/tina-v853/prebuilt/gcc/linux-x86/arm/toolchain-sunxi-musl/toolchain/bin)
set(CMAKE_C_COMPILER ${TOOLCHAIN_PATH}/arm-openwrt-linux-gcc)
set(CMAKE_CXX_COMPILER ${TOOLCHAIN_PATH}/arm-openwrt-linux-g++)
include_directories(${CMAKE_CURRENT_SOURCE_DIR}/3rd/viplite-driver/include)
include_directories(${CMAKE_CURRENT_SOURCE_DIR}/3rd/libjpeg/include)
include_directories(${CMAKE_CURRENT_SOURCE_DIR}/inc)
aux_source_directory(${CMAKE_CURRENT_SOURCE_DIR}/src SRC_LIST)
add_executable(test ${SRC_LIST})
target_link_libraries(test ${CMAKE_CURRENT_SOURCE_DIR}/3rd/viplite-driver/lib/libVIPlite.so
${CMAKE_CURRENT_SOURCE_DIR}/3rd/viplite-driver/lib/libVIPuser.so
${CMAKE_CURRENT_SOURCE_DIR}/3rd/libjpeg/lib/libjpeg.so.9
)
这里需要注意的主要就是交叉编译工具链的设置路径,对于Tina4.0的SDK,可以直接在SDK源码路径下ctoolchain即可一键进入工具链的路径中;
主函数:
int main(int argc, char **argv)
{
vip_status_e status = VIP_SUCCESS;
vip_uint32_t version = 0;
vip_network_items *network_items = VIP_NULL;
if (argc < 3)
{
cout << usage << endl;
printf("Arguments count %d is incorrect!\n", argc);
return -1;
}
VNNPreProcess *VNNPreP = new VNNPreProcess();
VNNPostProcess *VNNPostP = new VNNPostProcess();
VNNRuntime *VNNRun = new VNNRuntime();
version = vip_get_version();
printf("init vip lite, driver version=0x%08x...\n", version);
_CHECK_IF_ERROR(vip_init(1*3*448*448));
_CHECK_IF_ERROR(VNNPreP->vnn_InitNetworkItem(&network_items, argc, argv));
_CHECK_IF_ERROR(VNNPreP->vnn_CreateNeuralNetwork(network_items));
_CHECK_IF_ERROR(VNNPreP->vnn_PreProcessNeuralNetwork(network_items));
_CHECK_IF_ERROR(VNNRun->vnn_RunNeuralNetwork(network_items));
_CHECK_IF_ERROR(VNNPostP->vnn_PostProcessNeuralNetwork(network_items));
_CHECK_IF_ERROR(VNNPostP->vnn_ReleaseNeuralNetwork(network_items));
delete VNNPreP;
delete VNNPostP;
delete VNNRun;
return status;
}
这里基本按照提供的模板代码结构来写的;
然后中间的代码基本和提供的模板代码相同,需要更改的地方:
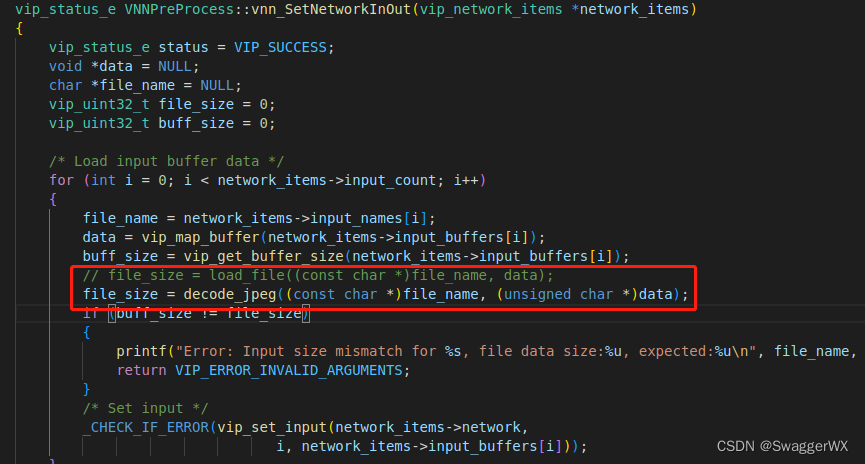
(a)因为我使用的是图片作为直接输入,而模板代码是文本数据作为输入,此处可以换成libjpeg解码的函数,这个函数可以在TinaSDK中的vpm_run部分找到,就是一个jpeg解压缩的操作;
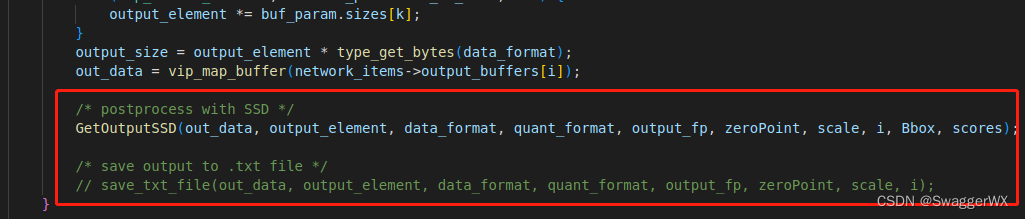
(b)主要就是加上人脸检测的后处理部分代码,可以在vnn_PostProcessNeuralNetwork函数中添加,可以根据需要选择以txt格式存储,还是按照SSD后处理的方式处理out_data,然后紧接着做NMS等操作即可;
运行代码:
首先在x86平台对程序进行编译生成可执行文件,然后将可执行文件push到v853板子上,同时也将上面第一步骤生成的network_binary.nb模型文件push到板子上;还要准备一张resize好的人脸图片(这里吐槽一下全志没有提供相关的硬件解码的resize api,只能事先做resize,这对结果的精度以及工程化应用不太友好),准备完毕执行代码:
./test network_binary.nb obama_resized.jpg
打印log如下:
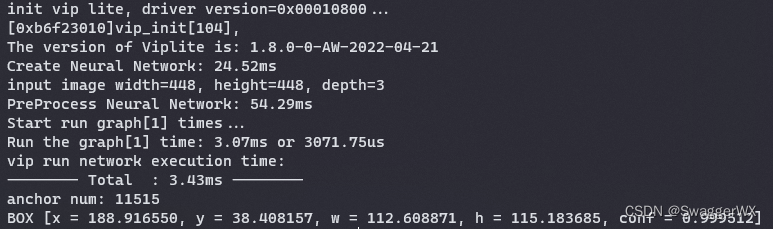
可以看到这里创建网络对象耗时24ms左右,前处理耗时54ms左右,推理耗时3.43ms,最后经过后处理的检测框以及置信度输出为[x = 188.916550, y = 38.408157, w = 112.608871, h = 115.183685, conf = 0.999512],我们使用python脚本,调用opencv的rectengle函数将检测框在原图中画出:

















 1257
1257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









