







目录
文章导航
一、集中趋势
1、均值
均值(也称为平均值)是统计学中描述数据集中趋势的一种常用统计量,它表示一组数据中所有数值的总和除以数据个数的结果。均值能够反映数据的中心位置。
import pandas as pd
df = pd.read_csv('train.csv')
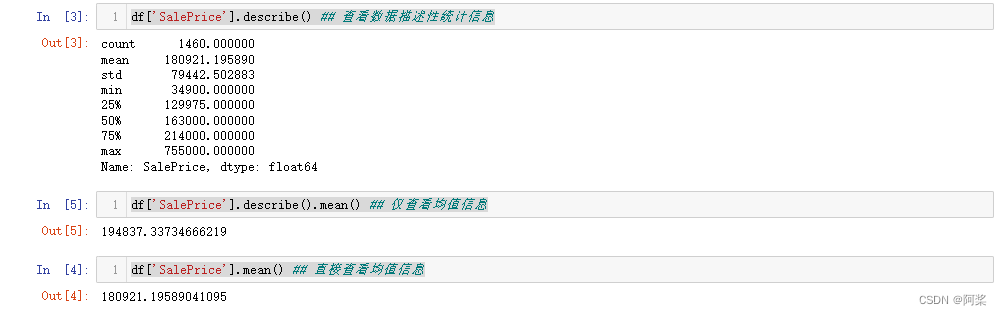
df['SalePrice'].describe() ## 查看数据描述性统计信息
df['SalePrice'].describe().mean() ## 仅查看均值信息
df['SalePrice'].mean() ## 直接查看均值信息
2、中位数
中位数是按顺序排列的一组数据中居于中间位置的数,代表一个样本、种群或概率分布中的一个数值。对于有限的数集,可以通过把所有观察值高低排序后找出正中间的一个作为中位数。如果观察值有偶数个,通常取最中间的两个数值的平均数作为中位数。
df['SalePrice'].median()

3、众数
众数是一组数据中出现次数或出现频率最多的数值。它是一种位置平均数,不受极端变量值的影响。众数主要用于测度分类数据的集中趋势,也可以用来测度顺序数据和数值型数据的集中趋势。
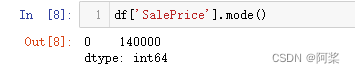
df['SalePrice'].mode()
二、分散性
1、全距(极差Range)
数据集中最大值与最小值的差,用于量度数据集的分散程度。不过,极差仅仅描述了数据的宽度,并没有描述数据在上、下界之间的分布形态。如果数据中存在异常值,极差可能会极具误导性。
range_SalePrice = df['SalePrice'].max() - df['SalePrice'].min()
range_SalePrice

2、四分位距(Interquartile Range,IQR)
上四分位数与下四分位数之差,反映了中间50%数据的离散程度。四分位距是一个不受异常值影响的“迷你距”,能更稳健地描述数据的分散性。
iqr_SalePrice = df['SalePrice'].quantile(0.75) - df['SalePrice'].quantile(0.25)
iqr_SalePrice

3、百分位数(Percentile)
第k百分位Pk表示位于数据范围k%处的数值,用于描述数据在不同百分位上的分布情况。
df['SalePrice'].quantile(0.66) #取值范围0-1

4、中位数
df['SalePrice'].quantile(0.5)

三、变异性
1、方差(Variance)
每个数据与平均值的差值的平方和的均值,用于描述数据偏离平均值的程度。方差是量度数据分布形态的重要指标。
variance_SalePrice = df['SalePrice'].var()
variance_SalePrice

2、标准差(Standard Deviation)
方差的平方根,与方差一样,用于描述数据的变异性。标准差具有与原始数据相同的单位,因此更容易理解。
std_dev_SalePrice = df['SalePrice'].std()
std_dev_SalePrice

3、标准分(Z分数或标准化得分)
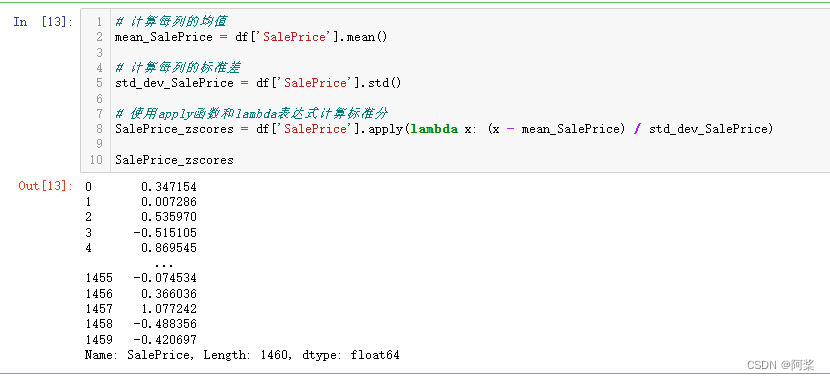
测量值相对于均值的标准偏差数。它表示一个原始分数与团体平均数之差,再除以标准差所得的商数。标准分是一种能够反映某一分数在团体中所处相对位置的量数。它将原始分数转换为平均数为0,标准差为1的标准分数,用公式表示为:Z = (x - μ) / σ。其中,x是某一具体分数,μ是平均数,σ是标准差。
# 计算每列的均值
mean_SalePrice = df['SalePrice'].mean()
# 计算每列的标准差
std_dev_SalePrice = df['SalePrice'].std()
# 使用apply函数和lambda表达式计算标准分
SalePrice_zscores = df['SalePrice'].apply(lambda x: (x - mean_SalePrice) / std_dev_SalePrice)
SalePrice_zscores
4、离散系数(Coefficient of Variation)
标准差与平均值之比,用于比较不同数据集之间的变异程度,可以消除不同数据集之间的单位差异。
# 计算每列的均值
mean_SalePrice = df['SalePrice'].mean()
# 计算每列的标准差
std_dev_SalePrice = df['SalePrice'].std()
# 使用apply函数和lambda表达式计算标准分
SalePrice_coef_var = std_dev_SalePrice / mean_SalePrice
SalePrice_coef_var

5、偏态系数(Skewness)
衡量数据分布形态的偏斜程度。偏态系数越大,说明数据分布越偏斜;反之,偏态系数越小,说明数据分布越接近对称。
skewness_SalePrice = df['SalePrice'].skew()
skewness_SalePrice

6、峰态系数(Kurtosis)
描述数据分布形态的陡峭或扁平程度。峰态系数大于3表示数据分布比正态分布更陡峭;峰态系数小于3表示数据分布比正态分布更扁平。
kurtosis_SalePrice = df['SalePrice'].kurtosis()
kurtosis_SalePrice

















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









