







文章目录
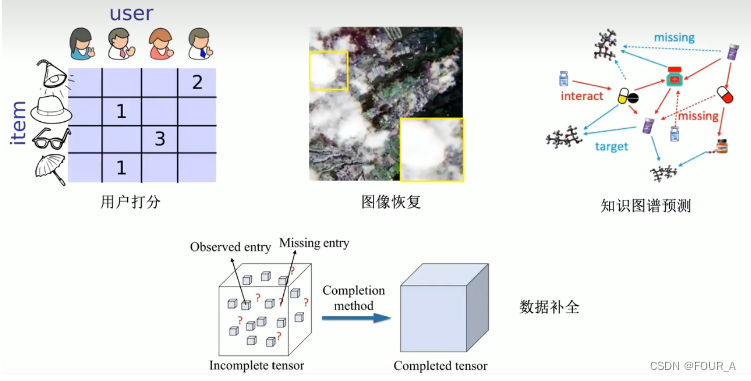
张量补全场景
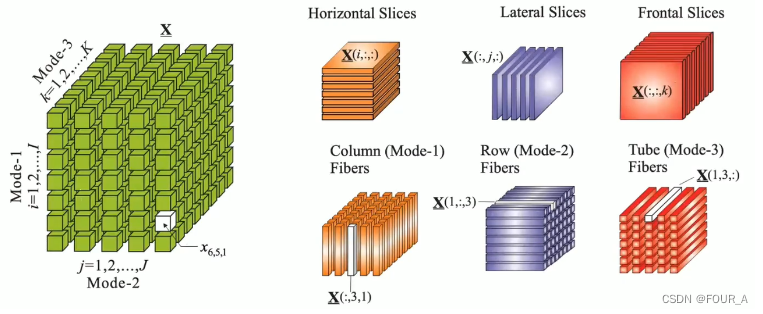
三阶张量
张量运算
内积
给定两个张量 X \mathcal{X} X 和 Y \mathcal{Y} Y ,它们的内积定义为它们对应元素的乘积的总和。形式化地,张量内积可以表示为:
⟨ X , Y ⟩ = ∑ i 1 , i 2 , … , i N x i 1 , i 2 , … , i N ⋅ y i 1 , i 2 , … , i N \langle \mathcal{X}, \mathcal{Y} \rangle = \sum_{i_1, i_2, \dots, i_N} x_{i_1, i_2, \dots, i_N} \cdot y_{i_1, i_2, \dots, i_N} ⟨X,Y⟩=∑i1,i2,…,iNxi1,i2,…,iN⋅yi1,i2,…,iN
其中, x i 1 , i 2 , … , i N 和 y i 1 , i 2 , … , i N x_{i_1, i_2, \dots, i_N} 和 y_{i_1, i_2, \dots, i_N} xi1,i2,…,iN和yi1,i2,…,iN 分别表示张量 X \mathcal{X} X 和 Y \mathcal{Y} Y 在相应位置的元素。
张量内积的计算可以用于衡量两个张量之间的相似度或相关性。例如,在张量分解中,我们**可以使用内积来度量原始张量与分解后的张量之间的近似程度。**此外,张量内积还可以用于张量的正交化、投影等操作,类似于向量的内积在向量空间中的应用。
需要注意的是,张量内积的计算通常需要考虑张量的高阶性质,因此计算复杂度较高,尤其是在处理大规模高阶张量时。
外积
对于高阶张量的外积【是线性代数中的外积而非解析几何中的外积(叉乘Cross Product)】,若
B
∈
R
m
1
×
.
.
.
×
m
f
,
C
∈
R
n
1
×
.
.
.
×
n
g
B∈R^{m_1 \times ...\times m_f},C∈R^{n_1 \times ... \times n_g}
B∈Rm1×...×mf,C∈Rn1×...×ng,则张量
B
B
B 和张量
C
C
C 做外积运算
将生成一个
f
+
g
f+ g
f+g 阶张量
A
\mathcal A
A, 并且张量
A
\mathcal A
A, 中的元素:
A = B ⊗ C , 1 ≤ i ≤ m , 1 ≤ j ≤ n \mathcal A = B \otimes C , 1\le i \le m, 1 \le j \le n A=B⊗C,1≤i≤m,1≤j≤n
Kronecker 积 (Kronecker Product)
一种用于组合两个矩阵的运算,产生一个新的矩阵的操作。
让我们来举一个简单的例子,假设有两个矩阵 A A A 和 B B B 如下:
A = ( 1 2 3 4 ) A = \begin{pmatrix} 1 & 2 \\ 3 & 4 \end{pmatrix} A=(1324) , B = ( 0 5 6 7 ) ,B = \begin{pmatrix} 0 & 5 \\ 6 & 7 \end{pmatrix} ,B=(0657)
它们的 K r o n e c k e r Kronecker Kronecker 积 A ⊗ B A \otimes B A⊗B 可以如下计算:
首先,我们计算 A A A 和 B B B 的每个元素的乘积:
A ⊗ B = ( 1 ⋅ B 2 ⋅ B 3 ⋅ B 4 ⋅ B ) A \otimes B = \begin{pmatrix} 1 \cdot B & 2 \cdot B \\ 3 \cdot B & 4 \cdot B \end{pmatrix} A⊗B=(1⋅B3⋅B2⋅B4⋅B) = ( 1 ⋅ 0 1 ⋅ 5 2 ⋅ 0 2 ⋅ 5 1 ⋅ 6 1 ⋅ 7 2 ⋅ 6 2 ⋅ 7 3 ⋅ 0 3 ⋅ 5 4 ⋅ 0 4 ⋅ 5 3 ⋅ 6 3 ⋅ 7 4 ⋅ 6 4 ⋅ 7 ) = \begin{pmatrix} 1 \cdot 0 & 1 \cdot 5 & 2 \cdot 0 & 2 \cdot 5 \\ 1 \cdot 6 & 1 \cdot 7 & 2 \cdot 6 & 2 \cdot 7 \\ 3 \cdot 0 & 3 \cdot 5 & 4 \cdot 0 & 4 \cdot 5 \\ 3 \cdot 6 & 3 \cdot 7 & 4 \cdot 6 & 4 \cdot 7 \end{pmatrix} = 1⋅01⋅63⋅03⋅61⋅51⋅73⋅53⋅72⋅02⋅64⋅04⋅62⋅52⋅74⋅54⋅7 = ( 0 5 0 10 6 7 12 14 0 15 0 20 18 21 24 28 ) = \begin{pmatrix} 0 & 5 & 0 & 10 \\ 6 & 7 & 12 & 14 \\ 0 & 15 & 0 & 20 \\ 18 & 21 & 24 & 28 \end{pmatrix} = 0601857152101202410142028
因此, A ⊗ B A \otimes B A⊗B 的结果为:
A ⊗ B = ( 0 5 0 10 6 7 12 14 0 15 0 20 18 21 24 28 ) A \otimes B = \begin{pmatrix} 0 & 5 & 0 & 10 \\ 6 & 7 & 12 & 14 \\ 0 & 15 & 0 & 20 \\ 18 & 21 & 24 & 28 \end{pmatrix} A⊗B= 0601857152101202410142028
这就是 A A A 和 B B B 的 K r o n e c k e r Kronecker Kronecker积。
Hadamard乘积(Hadamard Product)
H a d a m a r d Hadamard Hadamard 乘积(Hadamard Product)是指**两个具有相同维度的矩阵(或者向量)的对应元素相乘的运算。**也就是说,给定两个相同维度的矩阵 A A A 和 B B B ,它们的 H a d a m a r d Hadamard Hadamard 乘积 A ∘ B A \circ B A∘B 是一个新的矩阵,其每个元素由矩阵 A A A 和矩阵 B B B 对应位置的元素相乘而得。
具体来说,如果 A A A 和 B B B 是两个相同维度的矩阵,其元素分别为 a i j a_{ij} aij 和 b i j b_{ij} bij ,那么它们的 H a d a m a r d Hadamard Hadamard 乘积 A ∘ B A \circ B A∘B 的元素为 c i j = a i j ⋅ b i j c_{ij} = a_{ij} \cdot b_{ij} cij=aij⋅bij 。
H a d a m a r d Hadamard Hadamard 乘积通常用符号 ∘ \circ ∘ 表示,以区别于矩阵的标准矩阵乘积。它与矩阵乘积的不同之处在于, H a d a m a r d Hadamard Hadamard 乘积只考虑两个矩阵相同位置上的元素,而不涉及行列之间的乘积。
让我们来举一个简单的例子,假设有两个 2 × 2 2 \times 2 2×2 的矩阵 A A A 和 B B B 如下:
A = ( 1 2 3 4 ) A = \begin{pmatrix} 1 & 2 \\ 3 & 4 \end{pmatrix} A=(1324) B = ( 0 5 6 7 ) B = \begin{pmatrix} 0 & 5 \\ 6 & 7 \end{pmatrix} B=(0657)
它们的 H a d a m a r d Hadamard Hadamard 乘积 A ∘ B A \circ B A∘B 可以如下计算:
A ∘ B = ( 1 2 3 4 ) ∘ ( 0 5 6 7 ) A \circ B = \begin{pmatrix} 1 & 2 \\ 3 & 4 \end{pmatrix} \circ \begin{pmatrix} 0 & 5 \\ 6 & 7 \end{pmatrix} A∘B=(1324)∘(0657) = ( 1 ⋅ 0 2 ⋅ 5 3 ⋅ 6 4 ⋅ 7 ) = \begin{pmatrix} 1 \cdot 0 & 2 \cdot 5 \\ 3 \cdot 6 & 4 \cdot 7 \end{pmatrix} =(1⋅03⋅62⋅54⋅7) = ( 0 10 18 28 ) = \begin{pmatrix} 0 & 10 \\ 18 & 28 \end{pmatrix} =(0181028)
因此, A A A 和 B B B 的 H a d a m a r d Hadamard Hadamard 乘积 A ∘ B A \circ B A∘B 的结果为:
A ∘ B = ( 0 10 18 28 ) A \circ B = \begin{pmatrix} 0 & 10 \\ 18 & 28 \end{pmatrix} A∘B=(0181028)
这就是 A A A 和 B B B 的 H a d a m a r d Hadamard Hadamard 乘积的结果。
Khatri-Rao乘积 (Khatri-Rao Product)
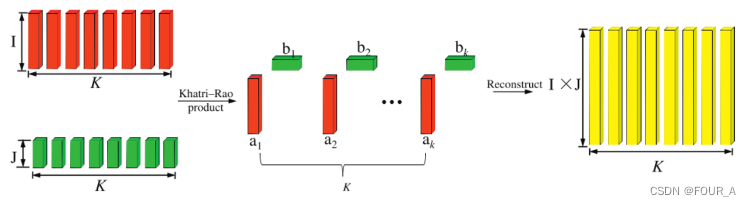
K h a t r i − R a o Khatri-Rao Khatri−Rao 乘积(Khatri-Rao Product)是一种用于组合两个矩阵列的运算,产生一个新的矩阵的操作。该运算通常用于张量分解和因子分解等应用中。
给定两个矩阵 A A A 和 B B B,它们的 K h a t r i − R a o Khatri-Rao Khatri−Rao 乘积 A ⊙ B A \odot B A⊙B 是一个新的矩阵,其每一列是矩阵 A A A 的列向量与矩阵 B B B 的对应列向量的外积结果。
具体地,假设矩阵 A A A 和 B B B 分别是 m × r m \times r m×r 和 n × r n \times r n×r 的矩阵,其中 r r r 是矩阵的列数(或者向量的长度)。那么它们的 K h a t r i − R a o Khatri-Rao Khatri−Rao 乘积 A ⊙ B A \odot B A⊙B 是一个 m n × r mn \times r mn×r 的矩阵,其每一列 j j j 由矩阵 A A A 的第 j j j 列与矩阵 B B B 的第 j j j 列的外积组成。
数学上, K h a t r i − R a o Khatri-Rao Khatri−Rao 乘积可以表示为:
A ⊙ B = [ a 1 ⊗ b 1 a 2 ⊗ b 2 ⋯ a r ⊗ b r ] A \odot B = \begin{bmatrix} a_1 \otimes b_1 & a_2 \otimes b_2 & \cdots & a_r \otimes b_r \end{bmatrix} A⊙B=[a1⊗b1a2⊗b2⋯ar⊗br]
其中, a i a_i ai 和 b i b_i bi 分别是矩阵 A A A 和 B B B 的第 i i i 列向量, ⊗ \otimes ⊗ 表示向量的外积运算。
K h a t r i − R a o Khatri-Rao Khatri−Rao 乘积常用于张量分解和因子分解等问题中,用于构造张量的模式矩阵(模式张量)以及重构原始张量。它可以有效地表示数据的结构和关联信息,用于分析和理解多维数据。
让我们来举一个简单的例子,假设有两个 3 × 2 3 \times 2 3×2 的矩阵 A A A 和 B B B 如下:
A = ( 1 2 3 4 5 6 ) A = \begin{pmatrix} 1 & 2 \\ 3 & 4 \\ 5 & 6 \end{pmatrix} A= 135246 , B = ( 7 8 9 10 11 12 ) ,B = \begin{pmatrix} 7 & 8 \\ 9 & 10 \\ 11 & 12 \end{pmatrix} ,B= 791181012
它们的 K h a t r i − R a o Khatri-Rao Khatri−Rao 乘积 A ⊙ B A \odot B A⊙B 可以如下计算:
首先,我们将矩阵 A A A 和矩阵 B B B 的每一列向量做外积:
a 1 ⊗ b 1 = ( 1 3 5 ) ⊗ ( 7 9 11 ) = ( 1 × 7 1 × 9 1 × 11 3 × 7 3 × 9 3 × 11 5 × 7 5 × 9 5 × 11 ) = ( 7 9 11 21 27 33 35 45 55 ) a_1 \otimes b_1 = \begin{pmatrix} 1 \\ 3 \\ 5 \end{pmatrix} \otimes \begin{pmatrix} 7 \\ 9 \\ 11 \end{pmatrix} = \begin{pmatrix} 1 \times 7 \\ 1 \times 9 \\ 1 \times 11 \\ 3 \times 7 \\ 3 \times 9 \\ 3 \times 11 \\ 5 \times 7 \\ 5 \times 9 \\ 5 \times 11 \end{pmatrix} = \begin{pmatrix} 7 \\ 9 \\ 11 \\ 21 \\ 27 \\ 33 \\ 35 \\ 45 \\ 55 \end{pmatrix} a1⊗b1= 135 ⊗ 7911 = 1×71×91×113×73×93×115×75×95×11 = 7911212733354555
a 2 ⊗ b 2 = ( 2 4 6 ) ⊗ ( 8 10 12 ) = ( 2 × 8 2 × 10 2 × 12 4 × 8 4 × 10 4 × 12 6 × 8 6 × 10 6 × 12 ) = ( 16 20 24 32 40 48 48 60 72 ) a_2 \otimes b_2 = \begin{pmatrix} 2 \\ 4 \\ 6 \end{pmatrix} \otimes \begin{pmatrix} 8 \\ 10 \\ 12 \end{pmatrix} = \begin{pmatrix} 2 \times 8 \\ 2 \times 10 \\ 2 \times 12 \\ 4 \times 8 \\ 4 \times 10 \\ 4 \times 12 \\ 6 \times 8 \\ 6 \times 10 \\ 6 \times 12 \end{pmatrix} = \begin{pmatrix} 16 \\ 20 \\ 24 \\ 32 \\ 40 \\ 48 \\ 48 \\ 60 \\ 72 \end{pmatrix} a2⊗b2= 246 ⊗ 81012 = 2×82×102×124×84×104×126×86×106×12 = 162024324048486072
因此, A A A 和 B B B 的 K h a t r i − R a o Khatri-Rao Khatri−Rao 乘积 A ⊙ B A \odot B A⊙B 的结果为:
A ⊙ B = ( 7 16 9 20 11 24 21 32 27 40 33 48 35 48 45 60 55 72 ) A \odot B = \begin{pmatrix} 7 & 16 \\ 9 & 20 \\ 11 & 24 \\ 21 & 32 \\ 27 & 40 \\ 33 & 48 \\ 35 & 48 \\ 45 & 60 \\ 55 & 72 \end{pmatrix} A⊙B= 7911212733354555162024324048486072
这就是 A A A 和 B B B 的 K h a t r i − R a o Khatri-Rao Khatri−Rao 乘积的结果。
n-mode 乘积
n − m o d e n-mode n−mode 乘积是张量分析中的一个重要操作,用于**将一个张量的某个模态(mode)与一个矩阵相乘,生成一个新的张量。**在 n − m o d e n-mode n−mode 乘积中,张量的每个元素都会与矩阵的对应元素相乘,并根据乘积的结果进行组合。
假设我们有一个 n n n 维张量 X \mathcal{X} X ,其维度为 I 1 × I 2 × ⋯ × I n I_1 \times I_2 \times \cdots \times I_n I1×I2×⋯×In ,以及一个矩阵 A A A ,其维度为 J × I k J \times I_k J×Ik 。那么 X \mathcal{X} X 在第 k k k 模态上与矩阵 A A A 的乘积,记为 X × k A \mathcal{X} \times_k A X×kA ,可以定义为一个新的张量 Y \mathcal{Y} Y ,其维度为 I 1 × ⋯ × I k − 1 × J × I k + 1 × ⋯ × I n I_1 \times \cdots \times I_{k-1} \times J \times I_{k+1} \times \cdots \times I_n I1×⋯×Ik−1×J×Ik+1×⋯×In ,其元素 y i 1 , … , j , … , i n y_{i_1, \dots, j, \dots, i_n} yi1,…,j,…,in 计算如下:
y i 1 , … , j , … , i n = ∑ i k x i 1 , … , i k , … , i n × a j i k y_{i_1, \dots, j, \dots, i_n} = \sum_{i_k} x_{i_1, \dots, i_k, \dots, i_n} \times a_{ji_k} yi1,…,j,…,in=∑ikxi1,…,ik,…,in×ajik
换句话说, X × k A \mathcal{X} \times_k A X×kA 的第 k k k 维度的每个元素都是 X \mathcal{X} X 在第 k k k 维度上的切片与矩阵 A A A 的对应列的点积。
n − m o d e n-mode n−mode 乘积在张量分解、张量压缩、特征提取等领域有着广泛的应用,是处理高维数据的重要工具。
张量与矩阵的模乘(Mode-n Product)
当我们谈到张量与矩阵的模乘时,我们实际上是在说:**将张量的某一维度与一个矩阵相乘,以转换那个维度的信息。**这个操作被称为“ M o d e − n Mode-n Mode−n P r o d u c t Product Product”,其中“ n n n”表示张量的哪一个维度正在被转换。
示例
假设你有一个三维张量 X \mathcal{X} X (想象为一个学生-科目-学期的数据立方体),和一个矩阵 A \mathbf{A} A (可能是一个新的学期的映射矩阵)。 m o d e − n mode-n mode−n 乘积允许你通过矩阵 A \mathbf{A} A 来转换张量 X \mathcal{X} X 中的“学期”这一维度。
数学示例
先将张量矩阵化,再将张量和矩阵相乘。不同的 m o d e − n mode-n mode−n 矩阵化会使得相乘结果不同。
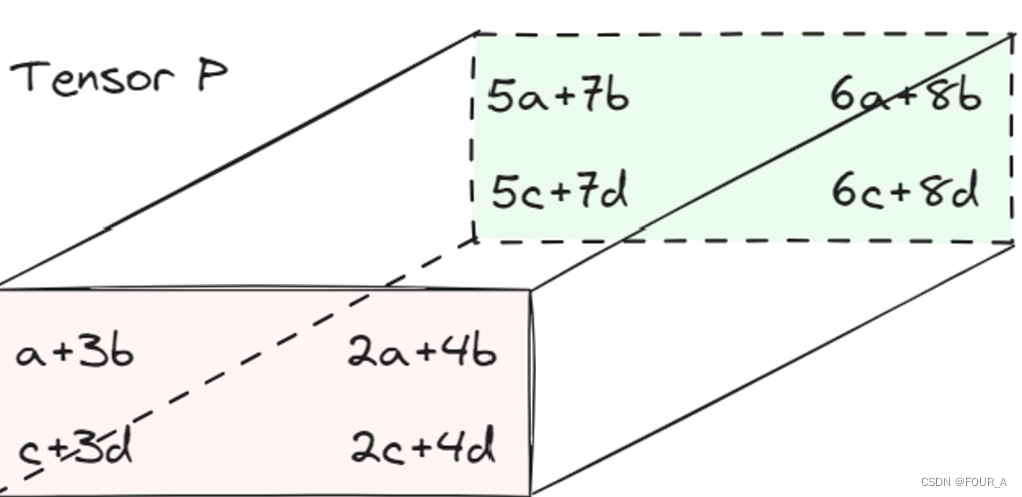
假设有一个张量: T \mathcal{T} T
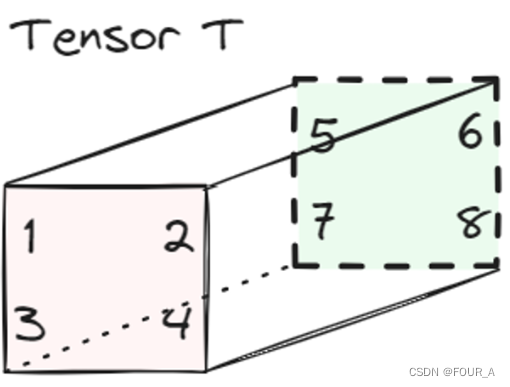
和一个矩阵: A = ( a b c d ) A = \begin{pmatrix} a & b \\ c & d \end{pmatrix} A=(acbd)
我们可以将张量 T \mathcal{T} T 按照 m o d e − 1 mode-1 mode−1 m a t r i c i z a t i o n matricization matricization 进行操作,得到的结果是:
T ( 1 ) = ( 1 2 3 4 ) 、 ( 5 6 7 8 ) \mathcal{T}_{(1)} = \begin{pmatrix} 1 & 2 \\3 &4 \end{pmatrix}、\begin{pmatrix} 5 & 6 \\7 & 8 \end{pmatrix} T(1)=(1324)、(5768)
再将得到的矩阵 T ( 1 ) \mathcal{T}_{(1)} T(1) 和矩阵 A A A 相乘:
P = T × 1 A ⇒ P ( 1 ) = ( a b c d ) ( 1 2 3 4 ) 、 ( a b c d ) ( 5 6 7 8 ) ⇒ P : \mathcal{P} = \mathcal{T \times _1}A \Rightarrow \mathcal{P}_{(1)} = \begin{pmatrix} a & b \\ c & d \end{pmatrix} \begin{pmatrix} 1 & 2 \\3 &4 \end{pmatrix}、\begin{pmatrix} a & b \\ c & d \end{pmatrix} \begin{pmatrix} 5 & 6 \\7 & 8 \end{pmatrix} \Rightarrow \mathcal{P:} P=T×1A⇒P(1)=(acbd)(1324)、(acbd)(5768)⇒P:
具体步骤
- 选择维度:确定你想要转换的维度,这里我们选择“学期”(假设它是第三维)。
- 应用矩阵:将矩阵 A \mathbf{A} A 应用于张量 X \mathcal{X} X 的第三维。这意味着,对于张量中的每一“页”(学生-科目的每一层),你都用矩阵 A \mathbf{A} A 去乘这一页,相当于在更新每个学生在新学期中的科目表现预期。
数学表达
如果 X \mathcal{X} X 是一个 I × J × K I \times J \times K I×J×K 的张量, A \mathbf{A} A 是一个 L × K L \times K L×K 的矩阵,那么 m o d e − 3 mode-3 mode−3 乘积 X × 3 A \mathcal{X} \times_3 \mathbf{A} X×3A 将会产生一个新的 I × J × L I \times J \times L I×J×L 的张量。这个操作在数学上通常表示为: X ( 3 ) × A \mathcal{X}_{(3)} \times \mathbf{A} X(3)×A
- 张量 X \mathcal{X} X 的第三维有 K K K 个元素。
- 矩阵 A \mathbf{A} A 必须有 K K K 列,因为每一列将与 X \mathcal{X} X 第三维的每一个元素相乘。
- 结果是, A \mathbf{A} A 的每一行产生的新张量 Y \mathcal{Y} Y 的一个条目,通过将 X \mathcal{X} X 第三维的所有 K K K 个元素与 A \mathbf{A} A 相应行的 K K K 个元素相乘然后求和得到。
- Y i , j , l = ∑ k = 1 K X i , j , k ⋅ A l , k \mathcal{Y}_{i,j,l} = \sum_{k=1}^K \mathcal{X}_{i,j,k} \cdot \mathbf{A}_{l,k} Yi,j,l=∑k=1KXi,j,k⋅Al,k
因此, A \mathbf{A} A 的列数必须与 X \mathcal{X} X 正在被转换的维度的元素数量相匹配,以**保证矩阵乘法的合法性和逻辑上的一致性。**这是矩阵乘法中的基本要求,保证了操作的可行性和结果的正确性。
m o d e − n mode-n mode−n 乘积的一般数学表达式如下:
( X × n A ) i 1 , … , i n − 1 , j , i n + 1 , … , i N = ∑ i n = 1 I n X i 1 , … , i N ⋅ A j , i n (\mathcal{X} \times_n \mathbf{A})_{i_1,\ldots,i{n-1},j,i_{n+1},\ldots,i_N} = \sum_{i_n=1}^{I_n} \mathcal{X}_{i_1,\ldots,i_N} \cdot \mathbf{A}_{j,i_n} (X×nA)i1,…,in−1,j,in+1,…,iN=∑in=1InXi1,…,iN⋅Aj,in
这里 I n I_n In 是张量 X \mathcal{X} X 在第 n n n 维的长度。
张量与向量的模积(Mode-n Product)
张量与向量的 Mode-n Product 是一个特殊情况的张量运算,其中张量的一个特定维度通过与一个向量相乘被压缩。这种操作经常用于降低张量的维度,从而集成或汇总某维度上的信息。
概念理解
想象你有一个箱子,箱子里有多层不同颜色的珠子,每层珠子代表一个维度的数据。如果你想计算每层珠子的平均颜色(假设颜色可以数值化),你可能会用一个特定的向量(在这个例子中,一个等权重向量)来加权每层珠子的颜色,然后计算一个总平均值。
在张量的上下文中,这可以视为将一个高维数据(多层珠子)通过与一个向量(权重)相乘来简化成更低维的数据(颜色的平均值)。
数学描述
对于一个 N-维 张量 X \mathcal{X} X 和一个向量 v \mathbf{v} v ,模-n乘积 X × n v \mathcal{X} \times_n \mathbf{v} X×nv 结果是一个 N − 1 N-1 N−1 维张量。在这个操作中,向量 v \mathbf{v} v 的长度必须与张量 X \mathcal{X} X 第 n n n 维的尺寸相匹配。
公式
如果张量 X \mathcal{X} X 的尺寸为 I 1 × I 2 × … × I N I_1 \times I_2 \times \ldots \times I_N I1×I2×…×IN ,向量 v \mathbf{v} v 的长度为 I n I_n In ,则 模-n 乘积 的结果张量 Y \mathcal{Y} Y 的尺寸为 I 1 × … × I n − 1 × I n + 1 × … × I N I_1 \times \ldots \times I_{n-1} \times I_{n+1} \times \ldots \times I_N I1×…×In−1×In+1×…×IN 。具体计算方法是:
Y i 1 , … , i n − 1 , i n + 1 , … , i N = ∑ i n = 1 I n X i 1 , … , i n , … , i N ⋅ v i n \mathcal{Y}_{i_1, \ldots, i{n-1}, i_{n+1}, \ldots, i_N} = \sum_{i_n=1}^{I_n} \mathcal{X}_{i_1, \ldots, i_n, \ldots, i_N} \cdot v_{i_n} Yi1,…,in−1,in+1,…,iN=∑in=1InXi1,…,in,…,iN⋅vin
这个表达式意味着新的张量 Y \mathcal{Y} Y 在除了第 n n n 维之外的每个维度上的每个条目是原张量 X \mathcal{X} X 第 n n n 维上的条目与向量 v \mathbf{v} v 的相应元素相乘的和。
数学示例
也要先将张量矩阵化
张量与向量的模积(Mode-n Product)是一个高阶张量与向量在某个特定模式上的运算。为了简化理解,我们可以从一个三阶张量和一个向量的模积开始讨论。
假设我们有一个三阶张量 T \mathcal{T} T ,其维度为 2 × 3 × 4 2 \times 3 \times 4 2×3×4 ,意味着该张量有 2 2 2 个层,每个层有 3 3 3 行 4 4 4 列。同时,我们有一个向量 v \mathbf{v} v 长度为 3 3 3。当我们进行第二模态 ( m o d e − 2 ) (mode-2) (mode−2)的乘积时,向量 v \mathbf{v} v 将与张量 T \mathcal{T} T 的每一行进行点积。
举个例子:
设张量
T
\mathcal{T}
T 的两个层分别是:
T
1
=
[
1
2
3
4
5
6
7
8
9
10
11
12
]
\mathcal{T}_1 = \begin{bmatrix} 1 & 2 & 3 & 4 \\ 5 & 6 & 7 & 8 \\ 9 & 10 & 11 & 12 \end{bmatrix}
T1=
159261037114812
T
2
=
[
13
14
15
16
17
18
19
20
21
22
23
24
]
\mathcal{T}_2 = \begin{bmatrix} 13 & 14 & 15 & 16 \\ 17 & 18 & 19 & 20 \\ 21 & 22 & 23 & 24 \end{bmatrix}
T2=
131721141822151923162024
向量 v \mathbf{v} v 为: v = [ 1 2 3 ] \mathbf{v} = \begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix} v= 123
在第二模态下与 T \mathcal{T} T 的模积 T × 2 v \mathcal{T} \times_2 \mathbf{v} T×2v 结果是一个 2 × 4 2 \times 4 2×4 的新张量,计算如下:
对于 T 1 \mathcal{T}_1 T1 :
- 第一行的结果为: 1 × 1 + 5 × 2 + 9 × 3 = 38 1 \times 1 + 5 \times 2 + 9 \times 3 = 38 1×1+5×2+9×3=38
- 第二行的结果为: 2 × 1 + 6 × 2 + 10 × 3 = 44 2 \times 1 + 6 \times 2 + 10 \times 3 = 44 2×1+6×2+10×3=44
- 第三行的结果为: 3 × 1 + 7 × 2 + 11 × 3 = 50 3 \times 1 + 7 \times 2 + 11 \times 3 = 50 3×1+7×2+11×3=50
- 第四行的结果为: 4 × 1 + 8 × 2 + 12 × 3 = 56 4 \times 1 + 8 \times 2 + 12 \times 3 = 56 4×1+8×2+12×3=56
对于 T 2 : \mathcal{T}_2 : T2:
- 第一行的结果为: 13 × 1 + 17 × 2 + 21 × 3 = 110 13 \times 1 + 17 \times 2 + 21 \times 3 = 110 13×1+17×2+21×3=110
- 第二行的结果为: 14 × 1 + 18 × 2 + 22 × 3 = 116 14 \times 1 + 18 \times 2 + 22 \times 3 = 116 14×1+18×2+22×3=116
- 第三行的结果为: 15 × 1 + 19 × 2 + 23 × 3 = 122 15 \times 1 + 19 \times 2 + 23 \times 3 = 122 15×1+19×2+23×3=122
- 第四行的结果为: 16 × 1 + 20 × 2 + 24 × 3 = 128 16 \times 1 + 20 \times 2 + 24 \times 3 = 128 16×1+20×2+24×3=128
因此,结果张量是:
T
×
2
v
=
[
38
44
50
56
110
116
122
128
]
\mathcal{T} \times_2 \mathbf{v} = \begin{bmatrix} 38 & 44 & 50 & 56 \\ 110 & 116 & 122 & 128 \end{bmatrix}
T×2v=[38110441165012256128]
张量分解模型
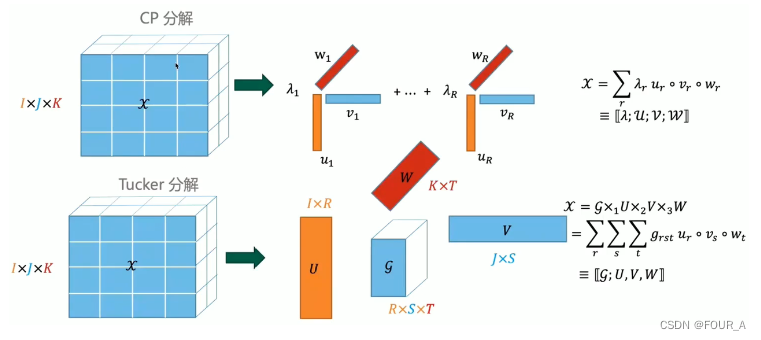
CP 分解
张量CP分解,也称为 CANDECOMP/PARAFAC(CP)分解,是一种常用的高阶张量分解方法。它将一个高阶张量表示为若干低阶张量的加权和,其中每个低阶张量是因子张量的外积。CP分解的形式可以表示为:
X = ∑ r = 1 R λ r ⋅ a r ⊗ b r ⊗ c r \mathcal{X} = \sum_{r=1}^{R} \lambda_r \cdot \mathbf{a}_r \otimes \mathbf{b}_r \otimes \mathbf{c}_r X=∑r=1Rλr⋅ar⊗br⊗cr
其中, X \mathcal{X} X 是要分解的 I 1 × I 2 × ⋯ × I N I_1 \times I_2 \times \cdots \times I_N I1×I2×⋯×IN 的高阶张量, R R R 是分解的秩(rank), λ r \lambda_r λr 是权重因子, a r \mathbf{a}_r ar 、 b r \mathbf{b}_r br 和 c r \mathbf{c}_r cr 分别是第一、第二和第三模态的因子向量, ⊗ \otimes ⊗ 表示外积运算。
CP 分解可以通过多种优化算法进行求解,其中最常见的是交替最小二乘法(Alternating Least Squares, ALS)和梯度下降法(Gradient Descent)。这些算法迭代更新因子向量和权重因子,直至达到收敛条件。
CP 分解在许多领域都有广泛的应用,比如信号处理、图像处理、推荐系统、生物信息学等。它可以用于数据压缩、特征提取、异常检测等任务,同时也可以提供对数据的解释和可解释性。
Tucker 分解
T u c k e r Tucker Tucker 分解是一种多线性代数方法,主要用于对高阶张量(多维数据)进行分解和简化。这种分解方法可以看作是高阶数据的主成分分析(PCA),它将一个高阶张量分解为一组核心张量和一系列因子矩阵的乘积。
在具体操作中,给定一个 N − N- N−阶张量 X \mathcal{X} X, T u c k e r Tucker Tucker 分解将其分解为一个核心张量 G \mathcal{G} G 和 N N N 个因子矩阵 A ( 1 ) , A ( 2 ) , … , A ( N ) \mathbf{A}^{(1)}, \mathbf{A}^{(2)}, \ldots, \mathbf{A}^{(N)} A(1),A(2),…,A(N)。这种分解可以表示为:
X ≈ G × 1 A ( 1 ) × 2 A ( 2 ) × 3 ⋯ × N A ( N ) \mathcal{X} \approx \mathcal{G} \times_1 \mathbf{A}^{(1)} \times_2 \mathbf{A}^{(2)} \times_3 \cdots \times_N \mathbf{A}^{(N)} X≈G×1A(1)×2A(2)×3⋯×NA(N)
其中 × n \times_n ×n 表示张量与矩阵的第 n n n 模 ( m o d e ) (mode) (mode)乘积。
每个因子矩阵 A ( n ) \mathbf{A}^{(n)} A(n) 对应于张量 X \mathcal{X} X 在第 n 维度上的线性变换,而核心张量 G \mathcal{G} G 则**指定了这些因子矩阵如何相互作用来近似原始张量。**通过选择适当大小的核心张量, T u c k e r Tucker Tucker 分解可以用于数据降维、特征提取或数据压缩。
T u c k e r Tucker Tucker 分解在许多应用领域都非常有用,如信号处理、计算机视觉、推荐系统等。通过这种方法,研究者可以从复杂的多维数据中提取有用的信息,或者更有效地处理大规模数据集。
低秩假设模型
一个基本的张量低秩补全问题可以表示为:
min X rank ( X ) s.t. X i j k = T i j k ∀ ( i , j , k ) ∈ Ω \min_{\mathcal{X}} \quad \text{rank}(\mathcal{X}) \quad \text{s.t.} \quad \mathcal{X}_{ijk} = \mathcal{T}_{ijk} \quad \forall (i, j, k) \in \Omega Xminrank(X)s.t.Xijk=Tijk∀(i,j,k)∈Ω
这里:
- X \mathcal{X} X 是我们想要恢复的完整张量。
- rank ( X ) \text{rank}(\mathcal{X}) rank(X) 指的是张量 X \mathcal{X} X 的秩,通常定义为张量分解中核心张量的秩或是分解中各个因子的维度。
- T \mathcal{T} T 是部分观测到的张量,即包含已知元素的张量。
- Ω \Omega Ω 是已知元素的索引集合。
- s . t s.t s.t 后面会跟随一系列条件,指定了优化变量需要满足的规则或属性
优化考虑和挑战
实际应用中,直接优化秩是非常困难的,因为秩函数是非凸且不连续的。因此,通常采用秩的凸松弛,例如使用核范数(矩阵的奇异值之和)作为代替,从而将问题转化为一个凸优化问题:
min X [ n ] ∥ X [ n ] ∥ ∗ s.t. X i j = M i j ∀ ( i , j ) ∈ Ω \min_{X_{[n]}} \quad \|X_{[n]}\|_* \quad \text{s.t.} \quad X_{ij} = M_{ij} \quad \forall (i, j) \in \Omega X[n]min∥X[n]∥∗s.t.Xij=Mij∀(i,j)∈Ω
其中, ∥ X ∥ ∗ \|X\|_* ∥X∥∗ 是矩阵 X X X 的核范数。
-
标准的 m o d e − n mode-n mode−n 展开: X ( n ) ∈ R I n × I 1 . . . I n − 1 I n + 1 . . . I N X_{(n)} \in \mathbb{R}^{I_n \times I_1 ... I_{n-1}I_{n+1}...I_{N}} X(n)∈RIn×I1...In−1In+1...IN
-
T T − m o d e − n TT-mode-n TT−mode−n 展开: X [ n ] ∈ R I 1 . . . I n × I n + 1 . . . I N X_{[n]} \in \mathbb{R}^{I_1 ... I_n \times I_{n+1}...I_{N}} X[n]∈RI1...In×In+1...IN
- 更加平衡,维数相差不是很大
- 数据挖掘丢失的信息会较少
-
**“秩函数是非凸且不连续的”**怎么理解
理解“秩函数是非凸且不连续的”这句话,需要从秩函数的数学性质和在优化问题中的行为角度来探讨。以下是对这两个方面的详细解释:
- 非凸性(Non-convexity)
- 凸集与凸函数:
- 凸集:如果一个集合中任意两点的连线段上的所有点也属于这个集合,则该集合是凸的。
- 凸函数:一个函数是凸的,如果对于其定义域内的任意两点,函数在这两点之间的线段上的值不大于这两点的函数值的线性插值。形式上,对于任意 x , y x, y x,y 和 θ ∈ [ 0 , 1 ] \theta \in [0,1] θ∈[0,1] ,有: f ( θ x + ( 1 − θ ) y ) ≤ θ f ( x ) + ( 1 − θ ) f ( y ) f(\theta x + (1-\theta)y) \leq \theta f(x) + (1-\theta) f(y) f(θx+(1−θ)y)≤θf(x)+(1−θ)f(y)
- 秩函数的非凸性:
- 对于矩阵的秩函数 rank ( X ) \text{rank}(X) rank(X) ,考虑两个具有不同秩的矩阵 A A A 和 B B B 。如果我们取 θ \theta θ 为非零和非一的任意值,通常 rank ( θ A + ( 1 − θ ) B ) \text{rank}(\theta A + (1-\theta) B) rank(θA+(1−θ)B) 不会等于 θ rank ( A ) + ( 1 − θ ) rank ( B ) \theta \text{rank}(A) + (1-\theta) \text{rank}(B) θrank(A)+(1−θ)rank(B) 。实际上, rank ( θ A + ( 1 − θ ) B ) \text{rank}(\theta A + (1-\theta) B) rank(θA+(1−θ)B) 可能会比两者的秩都大或都小,这表明秩函数不满足凸函数的定义。
- 凸集与凸函数:
- 不连续性(Discontinuity)
- 连续函数:
- 一个函数在某点连续,如果其在该点的极限值与函数值相等。即,当输入值趋向于某点时,输出值也应相应连续地趋向于该点的函数值。
- 秩函数的不连续性:
- 考虑一个矩阵序列,其中矩阵元素逐渐趋近于某个极限矩阵。如果极限矩阵的秩突然从序列中其他矩阵的秩跳跃到一个不同的值(例如,由于微小的扰动导致线性依赖关系的改变),则表明秩函数在该点不连续。这种情况在矩阵元素经微小变动导致线性独立变为线性依赖时尤为常见。
- 连续函数:
总结
因此,“秩函数是非凸且不连续的”这句话的意义在于,当使用秩函数作为优化目标时,找到全局最优解或稳定的解变得困难,这是因为非凸性导致可能存在多个局部最优解,而不连续性则意味着小的输入变化可能导致输出结果的大幅跳跃。这些特性使得直接优化秩函数成为一个复杂且挑战性的任务。在实际应用中,通常采用一些替代方法(如核范数最小化)来避免这些问题。
- 非凸性(Non-convexity)
-
秩的凸松弛是什么
“秩的凸松弛”(rank convex relaxation)通常指的是在优化问题中,用来近似秩函数(rank function)的一种凸函数。
常用的秩的凸松弛方法包括核范数松弛(nuclear norm relaxation),它是秩函数的最优凸近似。核范数是矩阵奇异值的和,它可以有效地用来近似矩阵的秩,并且是一个凸函数,便于优化求解。
奇异值收缩算法
奇异值收缩算法(Singular Value Thresholding, SVT)是一种用于解决低秩矩阵恢复和矩阵补全问题的有效方法。该算法主要应用于数据压缩、图像恢复、协同过滤等领域,特别是在处理数据丢失或噪声干扰较大的情况下。
算法描述
奇异值收缩算法的基本思想是对矩阵进行奇异值分解(SVD),**然后通过一个阈值操作来修改奇异值,最后重构矩阵以实现数据的恢复或降噪。**具体步骤如下:
-
奇异值分解(SVD):
对给定的矩阵 A A A 进行奇异值分解,表示为:A = U Σ V T A = U \Sigma V^T A=UΣVT
其中 U U U 和 V V V 是正交矩阵, Σ \Sigma Σ 是对角矩阵,其对角线元素即为 A A A 的奇异值。
-
奇异值收缩(Thresholding):
对所有奇异值应用阈值函数 τ \tau τ ,该函数可以定义为:σ i ′ = max ( σ i − τ , 0 ) \sigma'_i = \max(\sigma_i - \tau, 0) σi′=max(σi−τ,0)
这里 σ i \sigma_i σi 是原始的奇异值, σ i ′ \sigma'_i σi′ 是经过阈值处理后的奇异值。阈值 τ \tau τ 控制了收缩的程度,通常与问题的特定要求和噪声水平有关。
-
矩阵重构:
使用修改后的奇异值 σ i ′ \sigma'_i σi′ 和原始的正交矩阵 U 、 V U 、 V U、V 重构矩阵: A ′ = U Σ ′ V T A' = U \Sigma' V^T A′=UΣ′VT其中 Σ ′ \Sigma' Σ′ 是修改后的对角矩阵,只包含收缩后的奇异值。
应用示例
奇异值收缩算法在图像处理领域特别有用,比如在去除图像中的噪声或填补缺失像素时。例如,对于一个受损的图像,可以先对其进行 S V D SVD SVD,然后通过适当选择阈值去除那些较小的奇异值(通常与噪声相关),最后重构图像以恢复原始图像的主要特征。
优势与局限
优势:
- 鲁棒性:对噪声和数据丢失具有较好的容忍度。
- 灵活性:通过调整阈值 τ \tau τ ,可以控制降噪或数据恢复的程度。
局限:
- 参数依赖:阈值 τ \tau τ 的选择对结果有显著影响,且往往需要根据具体问题手动调整。
- 计算成本:进行完整的奇异值分解可能在大规模数据集上非常耗时。


















 5397
5397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











