







持续学习+元学习文章调研(一)
- 文章
- Understanding the Role of Training Regimes in Continual Learning. NeurIPS 2020
- Meta-Consolidation for Continual Learning. NeurIPS 2020
- Online Fast Adaptation and Knowledge Accumulation (OSAKA): a New Approach to Continual Learning. NeurIPS 2020
- Meta-Learning with Sparse Experience Replay for Lifelong Language Learning. CoRR abs/2009.04891 (2020)
最近因为相关研究,想要调研一下关于持续学习+元学习的一些文章。找了一些进行阅读,由于是为了我的相关研究做的资料收集,所以暂时不在研究范围内的文章就不进行精度,在此整理。
文章
Understanding the Role of Training Regimes in Continual Learning. NeurIPS 2020
简介
这篇文章详细研究了不同的训练策略(学习率、正则化、batch size、dropout等),说明他们对于局部最优解损失平面宽度影响(不排除其它因素)同时对于持续学习能力有所影响,经过调整的学习策略可以媲美特别设计的持续学习算法,但是和持续学习算法仍然兼容。
Meta-Consolidation for Continual Learning. NeurIPS 2020
简介
将持续学习的视角放在“从任务生成权重的过程”上,基于在生物智能中任务本身被表示在“meta-space”的假设。每一个任务的解来自于一个分布 p ( ψ ∣ t ) p(\bm{\psi}|\bm{t}) p(ψ∣t),其中 t t t为任务的descriptioin向量,可以来自embedding或简单的one-hot, ψ \psi ψ为任务权重。
核心方法

- 在每一个任务上训练一些网络获得权重,使用VAE(变分自编码器)来(在每一个任务中)学习这些权重,编码器的隐空间 z z z符合 t t t控制的先验分布。
- Consolidate,每次在一个任务上学完,在所有任务的分布上做consolidate,避免过分偏向某一个任务。(为什么不直接在所有任务上训练许多个模型来训练VAE而要一个个学然后进行consolidation?应该是因为这样无法添加新任务,同时在所有旧任务的分布上做,只需要记录分布参数,不需要样本,存储开销更小)
Online Fast Adaptation and Knowledge Accumulation (OSAKA): a New Approach to Continual Learning. NeurIPS 2020
简介
这篇文章对于持续学习能力提出了更广泛的要求,设计评估了模型的抗遗忘、快速适应等能力的。简略来说,模型不仅应该学习新任务时不遗忘旧任务,还应该在面对旧任务时快速回想。提出的持续学习设置(OSAKA)具有以下特点:
- 任务随机采样,旧人物可重复访问
- 任务边界不可知
- 使用的时累积平均表现而非模型的最终表现来评估模型
为了解决这个新的持续学习场景,作者基于元学习,提出了Continual-MAML算法,借助元学习方式,通过让模型对于distribution change具有感知能力。相比于BGD或借助memory的方法,Continual-MAML更加节省资源。
核心方法
Continual-MAML算法完整伪代码如下图:

- 检测任务变化在第21行,根据从当前开始学的结果是否优于从头开始学的结果来判断是否有Context变化,L差距小于γ则认为没有变化。如果差距小则相当于MAML的inner loop继续。否则已经认为xt-1到xt发生了任务切换,那么相当于MAML的一个更新流程完成(inner loop结束),就要使用xt-1和θt-2来优化全局的Φ。
Meta-Learning with Sparse Experience Replay for Lifelong Language Learning. CoRR abs/2009.04891 (2020)
简介
使用持续学习+元学习方法在NLP上进行实验的文章。针对无任务边界的情况做了分析。设计了Episode Generation和Experience Replay的元学习测试场景,对OML和ANML做了改进,为他们加上了Experience Replay的模块。
元学习方法对于持续学习的促进作用
以MAML为代表的基于梯度的元学习方法通过为梯度下降过程增加了梯度一致性的损失(点乘),从而鼓励梯度的Transfer而抑制Interfere,从而也能够增强模型的持续学习能力。(这部分关于元学习梯度的推到很有分量,尤其是对多batch的inner-loop的近似推断,以往我只看了单一batch的情况,对于梯度点积的实际意义的分析也很有启发)
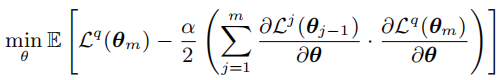
上式是一阶MAML中对于outer-loop的优化目标的计算,可以看到增加了对于梯度不一致性的惩罚项(鼓励点积更大,即一致性更强)。
Episode Generation和Experience Replay
本文对于持续学习的stream做了更加规范的定义,对于replay的间隔、buffer的大小等也有了具体的描述。 m m m个大小为 b b b的batch构成了一个Support Set,后一个batch则为Query Set,这m+1个batch构成了一个episode。
- b b b:batch size
- m m m:num_batches(buffer size)
- R I R_I RI:重放间隔,表示多少样本之后来一个带有重放的Query Set。
- r r r:重放比例,表示多少样本进行重放。重放样本数量为 r ∗ R I r*R_I r∗RI
-
R
F
R_F
RF:重放频率,表示多少个Episode进行一次重放(其实我觉得应该是叫重放周期才对),计算方法为
R
F
=
⌈
R
I
/
b
+
1
m
+
1
⌉
R_F=\lceil \frac{R_I/b+1}{m+1}\rceil
RF=⌈m+1RI/b+1⌉

本文提出的OML-ER和ANML-ER实际上就是这两个算法在这个流程下的学习过程,因此不额外介绍了。
















 3784
3784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









