









1. 大数据体系
| 过程 | 内容 | 职位 | |
|---|---|---|---|
| 1 | 数据平台 | Data Platform,构建、维护稳定、安全的大数据平台,按需设计大数据架构,调研选型大数据技术产品、方案,实施部署上线。 | 大数据架构师,数据平台工程师 |
| 2 | 数据采集 | Data Collecting,从Web/Sensor/RDBMS等渠道获取数据,为大数据平台提供数据来源,如Apache Nutch是开源的分布式数据采集组件,大家熟知的Python爬虫框架ScraPy等。 | 爬虫工程师,数据采集工程师 |
| 3 | 数据仓库 | Data Warehouse,有点类似于传统的数据仓库工作内容:设计数仓层级结构、ETL、进行数据建模,但基于的平台不一样,在大数据时代,数据仓库大多基于大数据技术实现,例如Hive就是基于Hadoop的数据仓库。 | ETL工程师,数据仓库工程师 |
| 4 | 数据处理 | 以前做ETL或许是利用工具直接配置处理一些过滤项,写代码部分会比较少,如今在大数据平台上做数据处理可以利用更多的代码方式做更多样化的处理,所需技术有Hive、Hadoop、Spark等。 | Hadoop工程师,Spark工程师 |
| 5 | 数据分析 | 基于统计分析方法做数据分析:例如回归分析、方差分析等。大数据分析例如Ad-Hoc交互式分析、SQL on Hadoop的技术有:Hive 、Impala、Presto、Spark SQL,支持OLAP的技术有:Kylin | |
| 6 | 数据挖掘,机器学习,深度学习 | 主要是设计并在大数据平台上实现数据挖掘算法:分类算法、聚类算法、关联分析等。机器学习是一个计算机与统计学交叉的学科,基本目标是学习一个x->y的函数(映射),来做分类或者回归的工作。之所以经常和数据挖掘合在一起讲是因为现在好多数据挖掘的工作是通过机器学习提供的算法工具实现的,例如个性化推荐,是通过机器学习的一些算法分析平台上的各种购买,浏览和收藏日志,得到一个推荐模型,来预测你喜欢的商品。Deep Learning,是机器学习里面的一个topic(非常火的Topic),从深度学习的内容来看其本身是神经网络算法的衍生,在图像、语音、自然语言等分类和识别上取得了非常好的效果,大部分的工作是在调参 | |
| 7 | 数据可视化 | 数据工程师,BI工程师 | |
| 8 | 数据应用 | 从以上的每个部分可以衍生出的应用,例如广告精准投放、个性化推荐、用户画像等。 |
**以上内容转载自 https://yq.aliyun.com/articles/668820
2. 数据库 与 数据仓库的区别
业务数据库中的数据结构是为了完成交易而设计的,不是为了而查询和分析的便利设计的;数据仓库的作用在于:数据结构为了分析和查询的便利;只读优化的数据库,只要做大量数据的复杂查询的速度足够快就行了。
数据库 比较流行的有:MySQL, Oracle, SqlServer等
数据仓库 比较流行的有:AWS Redshift, Greenplum, Hive等
把数据从业务性的数据库中提取、加工、导入分析性的数据库就是传统的 ETL 工作。面对大数据还有其他的工作方式。
3. hadoop和大数据的关系?和spark的关系?
| nutch | |
|---|---|
| GFS 存储海量搜索数据而设计的专用文件系统 | NDFS 分布式文件存储系统 |
| MapReduce编程模型。这个编程模型,用于大规模数据集(大于1TB)的并行分析运算。 | 基于MapReduce,在Nutch搜索引擎实现了该功能 |
| 加入Yahoo,将NDFS和MapReduce进行了升级改造,并重新命名为Hadoop(NDFS也改名为HDFS) | |
| BigTable。这是一种分布式数据存储系统,一种用来处理海量数据的非关系型数据库。 | 在自己的hadoop系统里面,引入了BigTable,并命名为HBase。 |
Hadoop的最初架构:

2.0版本中,在HDFS之上,增加了YARN(资源管理框架)层。它是一个资源管理模块,为各类应用程序提供资源管理和调度。还提升了系统的安全稳定性。
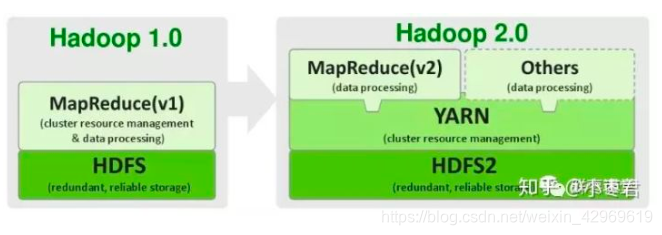
现在由最开始的两三个组件,发展成一个拥有20多个部件的生态系统
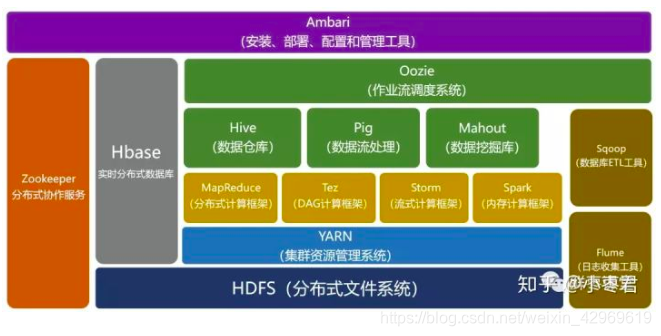
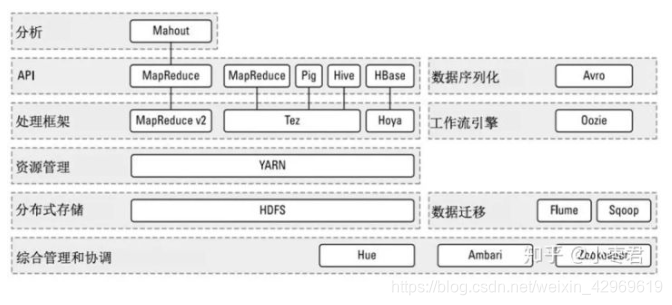
目前,各大公司都根据Hadoop构建自己的大数据系统
spark是面向内存,为多个数据源的数据提供近似实时的数据操作;而MapReduce是面向磁盘的,受限于磁盘的读写性能,在处理迭代,实时计算,交互式数据查询受限。
下图是hadoop生态系统,集成spark生态圈

**转载自https://www.zhihu.com/question/23036370
4. SQL和Hadoop区别:
| 区别 | 说明 |
|---|---|
| SQL(结构化查询语言)是针对结构化数据设计的,而Hadoop最初的许多应用针对的是文本这种非结构化数据。 | 相对于结构化数据(即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据)而言,不方便用数据库二维逻辑表来表现的数据即称为非结构化数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。 |
| 用向外扩展代替向上扩展 | Hadoop集群就是增加更多的机器。一个Hadoop集群的标配是十至数百台计算机。而不是专注于提高单台服务器的性能 |
| 用函数式编程(MapReduce)代替声明式查询(SQL) | hadoop读取出的数据,可以建立复杂的模型或者改变图片格式 |
| 用离线批量处理代替在线处理 | Hadoop是专为离线处理和大规模数据分析而设计的,它并不适合那种对几个记录随机读写的在线事务处理模式。 |
作者:大数据导师
来源:CSDN
原文:https://blog.csdn.net/a814046606/article/details/82351848
5. SQL on Hadoop 八大框架
数据的操作语言是SQL,因此很多工具的开发目标自然就是能够在Hadoop上使用SQL。这些工具有些只是在MapReduce之上做了简单的包装,有些则是在HDFS之上实现了完整的数据仓库,而有些则介于这两者之间。其中有八大模型:
| 名称 | 说明 | 使用情况 | |
|---|---|---|---|
| 1 | Apache Hive | Hive是原始的SQL-on-Hadoop解决方案。它是一个开源的Java项目,能够将SQL转换成一系列可以在标准的Hadoop TaskTrackers上运行的MapReduce任务。 | Hive是一个几乎所有的Hadoop机器都安装了的实用工具。但是需要注意的是,Hive的查询性能通常很低,这是因为它会把SQL转换为运行得较慢的MapReduce任务。 |
| 2 | Cloudera Impala | Impala是一个针对Hadoop的开源的“交互式”SQL查询引擎。和Hive一样,Impala也提供了一种可以针对已有的Hadoop数据编写SQL查询的方法。与Hive不同的是它并没有使用MapReduce执行查询,而是使用了自己的执行守护进程集合,这些进程需要与Hadoop数据节点安装在一起。 | Impala的设计目标是作为Apache Hive的一个补充,因此如果你需要比Hive更快的数据访问那么它可能是一个比较好的选择,特别是当你部署了一个Cloudera、MapR或者Amazon Hadoop集群的时候。但是,为了最大限度地发挥Impala的优势你需要将自己的数据存储为特定的文件格式(Parquet),这个转变可能会比较痛苦。另外,你还需要在集群上安装Impala守护进程,这意味着它会占用一部分TaskTrackers的资源。Impala目前并不支持YARN。 |
| 3 | Presto | Presto是一个用Java语言开发的、开源的“交互式”SQL查询引擎。Presto采用的方法类似于Impala,即提供交互式体验的同时依然使用已有的存储在Hadoop上的数据集。它也需要安装在许多“节点”上,类似于Impala。 | |
| 4 | Shark | Shark是由UC Berkeley大学使用Scala语言开发的一个开源SQL查询引擎。与Impala和Presto相似的是,它的设计目标是作为Hive的一个补充,同时在它自己的工作节点集合上执行查询而不是使用MapReduce。与Impala和Presto不同的是Shark构建在已有的 Apache Spark数据处理引擎之上。 | |
| 5 | Apache Drill | 一个针对Hadoop的、开源的“交互式”SQL查询引擎。Apache Drill的目标与Impala和Presto相似——对大数据集进行快速的交互式查询,同时它也需要安装工作节点(drillbits)。不同的是Drill旨在支持多种后端存储(HDFS、HBase、MongoDB),同时它的一个重点是复杂的嵌套数据集(例如JSON)。 | 仅在Alpha阶段 |
| 6 | HAWQ | EMC Pivotal 公司的一个非开源产品 | |
| 7 | BigSQL | Big Blue 有它自己的Hadoop版本,称为Big Insights。BigSQL作为该版本的一部分提供。BigSQL用于使用MapReduce和其他能够提供低延迟结果的方法(不详)查询存储在HDFS中的数据。 | |
| 8 | Apache Phoenix | Apache Phoenix是一个用于Apache HBase的开源SQL引擎。它的目标是通过一个嵌入的JDBC驱动对存储在HBase中的数据提供低延迟查询。与之前介绍的其他引擎不同的是,Phoenix提供了HBase数据的读、写操作。 | 如果你使用HBase那么就使用它。尽管Hive能够从HBase中读取数据,但是Phoenix还提供了写入功能。 |
| 9 | Apache Tajo | Apache Tajo项目的目的是在HDFS之上构建一个先进的数据仓库系统。它的重点是数据管理,提供低延迟的数据访问,以及为更传统的ETL提供工具。它也需要在数据节点上部署Tajo特定的工作进程。 | 北美没有主要的Hadoop供应商支持它。但是如果你在南韩,使用Gruter的平台,得到他们良好的支持,否则的话最好还是使用Impala或者Presto这些引擎。 |
** 文章来源http://www.infoq.com/cn/news/2014/06/sql-on-hadoop














 729
729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









