






-
点到超平面的距离
设n维空间的超平面方程为: w T x + b = 0 w^Tx+b=0 wTx+b=0, 其中w是这个超平面的法向量 w = ( w 1 , w 2 , w 3 , . . ) T w=(w_1,w_2,w_3,..)^T w=(w1,w2,w3,..)T, 有点x0到超平面的距离为:
∣ w T x 0 + b ∣ ∣ ∣ w ∣ ∣ \frac{|w^Tx_0+b|}{||w||} ∣∣w∣∣∣wTx0+b∣
推导过程:
令x’是超平面上的一点,点x到超平面的距离就是向量(x-x’)在法线方向上的投影,即 ||x-x’||cos(a) ,a是(x-x’)与法向量的夹角。我们知道两个向量的內积 w T ( x − x ′ ) = ∣ ∣ w ∣ ∣ . ∣ ∣ ( x − x ′ ) ∣ ∣ . c o s ( a ) w^T(x-x')= ||w|| .||(x-x')||. cos(a) wT(x−x′)=∣∣w∣∣.∣∣(x−x′)∣∣.cos(a),所以有 点到超平面的距离d
d = w T ( x − x ′ ) ∣ ∣ w ∣ ∣ d=\frac{w^T(x-x')}{||w||} d=∣∣w∣∣wT(x−x′)
x’ 满足 w T x + b = 0 w^Tx+b=0 wTx+b=0 ,所有
d = w T x + b ∣ ∣ w ∣ ∣ d=\frac{w^Tx+b}{||w||} d=∣∣w∣∣wTx+b -
变形:两个平行超平面之间的距离
w T x 1 + b = 1 w^Tx_1+b=1 wTx1+b=1, w T x 2 + b = − 1 w^Tx_2+b=-1 wTx2+b=−1 是两个平行的超平面,则这两个平面的距离是 2 ∣ ∣ w ∣ ∣ \frac{2}{||w||} ∣∣w∣∣2
w T ( x 1 − x 2 ) = 2 w^T(x_1-x_2)=2 wT(x1−x2)=2
w T ( x 1 − x 2 ) ∣ ∣ w ∣ ∣ = 2 ∣ ∣ w ∣ ∣ \frac{w^T(x_1-x_2)}{||w||}=\frac{2}{||w||} ∣∣w∣∣wT(x1−x2)=∣∣w∣∣2
支持向量机
- 目标是最大化 2 ∣ ∣ w ∣ ∣ \frac{2}{||w||} ∣∣w∣∣2 同时保证所有样本正确分类 , w是超平面的参数。样本正确分类 等价于 满足等式 y i ( ∑ w i x i + b ) > = 1 y_i(\sum w_ix_i+b)>=1 yi(∑wixi+b)>=1.
- 最大化 2 ∣ ∣ w ∣ ∣ \frac{2}{||w||} ∣∣w∣∣2 可以等价为 最小化 1 / 2 ∣ ∣ w ∣ ∣ 2 1/2||w||^2 1/2∣∣w∣∣2, 最小化 1 / 2 ∣ ∣ w ∣ ∣ 2 1/2||w||^2 1/2∣∣w∣∣2会使问题变得简单。
- 类似于 最小化w的长度的平方,并限制于某些条件 这种形式的最优化问题 称为二次规划(quadratic programming)问题。
求解二次规划问题,人们已经有了直截了当的方式。 - 还可以将上面二次规划问题再次转化为 标准的二次规划的问题形式。最大化
W
(
α
)
W(\alpha)
W(α) ,
α
\alpha
α是新参数
W ( α ) = ∑ i α − 1 / 2 ∑ i , j α i α j y i y j x i T x j W(\alpha)=\sum_i \alpha-1/2\sum_{i,j} \alpha_i\alpha_jy_iy_jx_i^Tx_j W(α)=i∑α−1/2i,j∑αiαjyiyjxiTxj
s t . α i > 0 , ∑ i α i y i = 0 st. \alpha_i>0,\sum_i\alpha_iy_i=0 st.αi>0,i∑αiyi=0 - 找到最大化这个方程的 α \alpha α后,可以还原原方程的w参数(超平面的参数): w = ∑ i α i x i y i w=\sum_i\alpha_ix_iy_i w=∑iαixiyi
- 绝大部分的 α i \alpha_i αi都是 0 , α i \alpha_i αi不为0的那些点就被称为支持向量
核函数
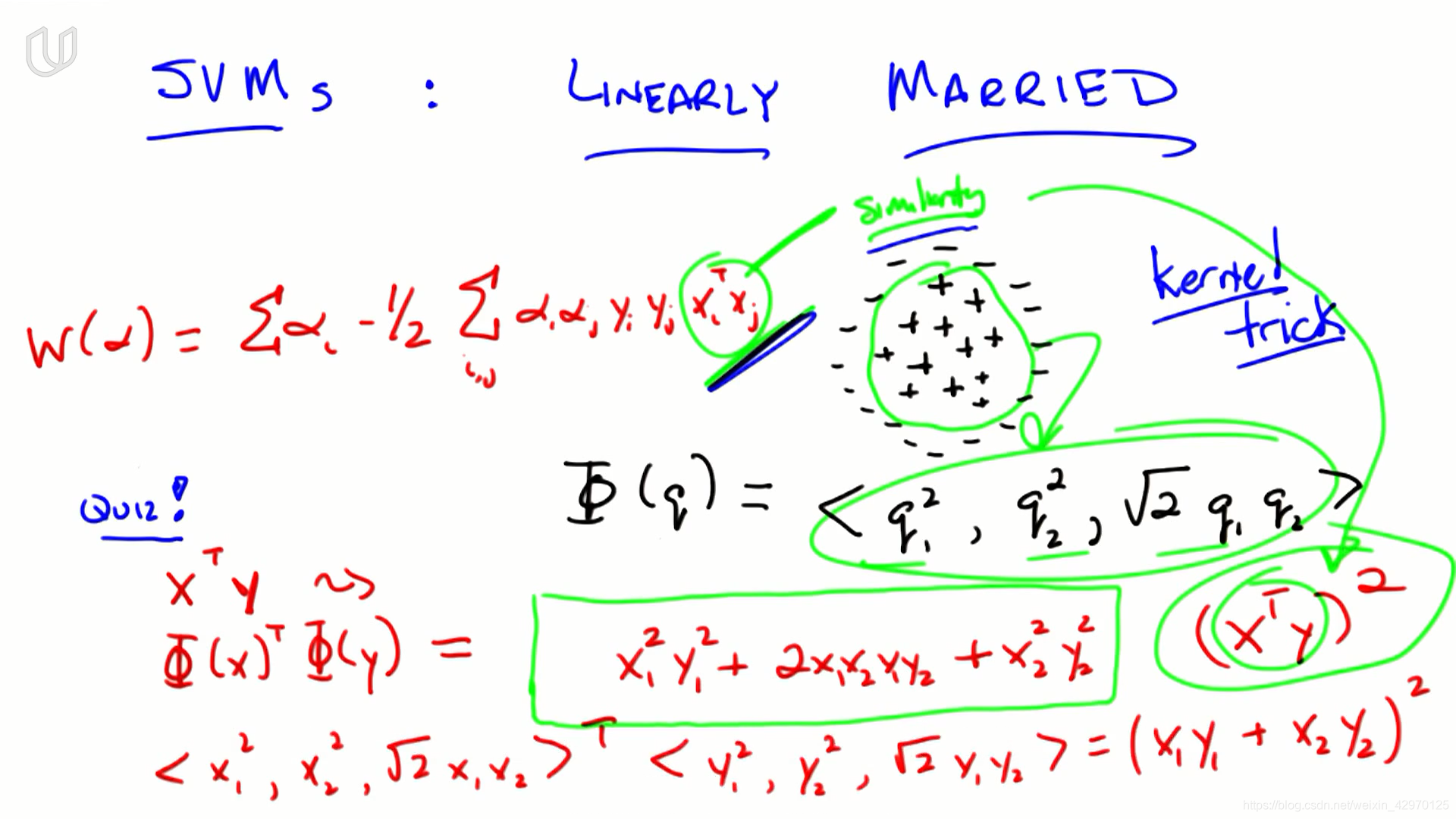
- 向量q 在平面上,因而它有两个分量(q1,q2),利用q 产生一个三维向量:
Φ ( q ) = < q 1 2 , q 2 2 , 2 q 1 q 2 > \Phi (q)=<q_1^2,q_2^2,\sqrt2q_1q_2> Φ(q)=<q12,q22,2q1q2>
这个过程实际上并没有增加新的信息。 - 将这些点从两个维度投影到三个维度,基本上获得所有正点并将它们沿第三个维度上移,所有的负点下移,这样就可以用超平面分割
- 內积是我们定义相似度similarity的方式,
- 将数据投影到更高维度的空间中,在那里进行比较,只需对算法做一点小小改变。点积可以转化成其他相似性度量,称之为核函数: x i T x j x_i^Tx_j xiTxj --> K ( x i , x j ) K(x_i,x_j) K(xi,xj)
- 核函数必须满足mercer condition
11-SVM
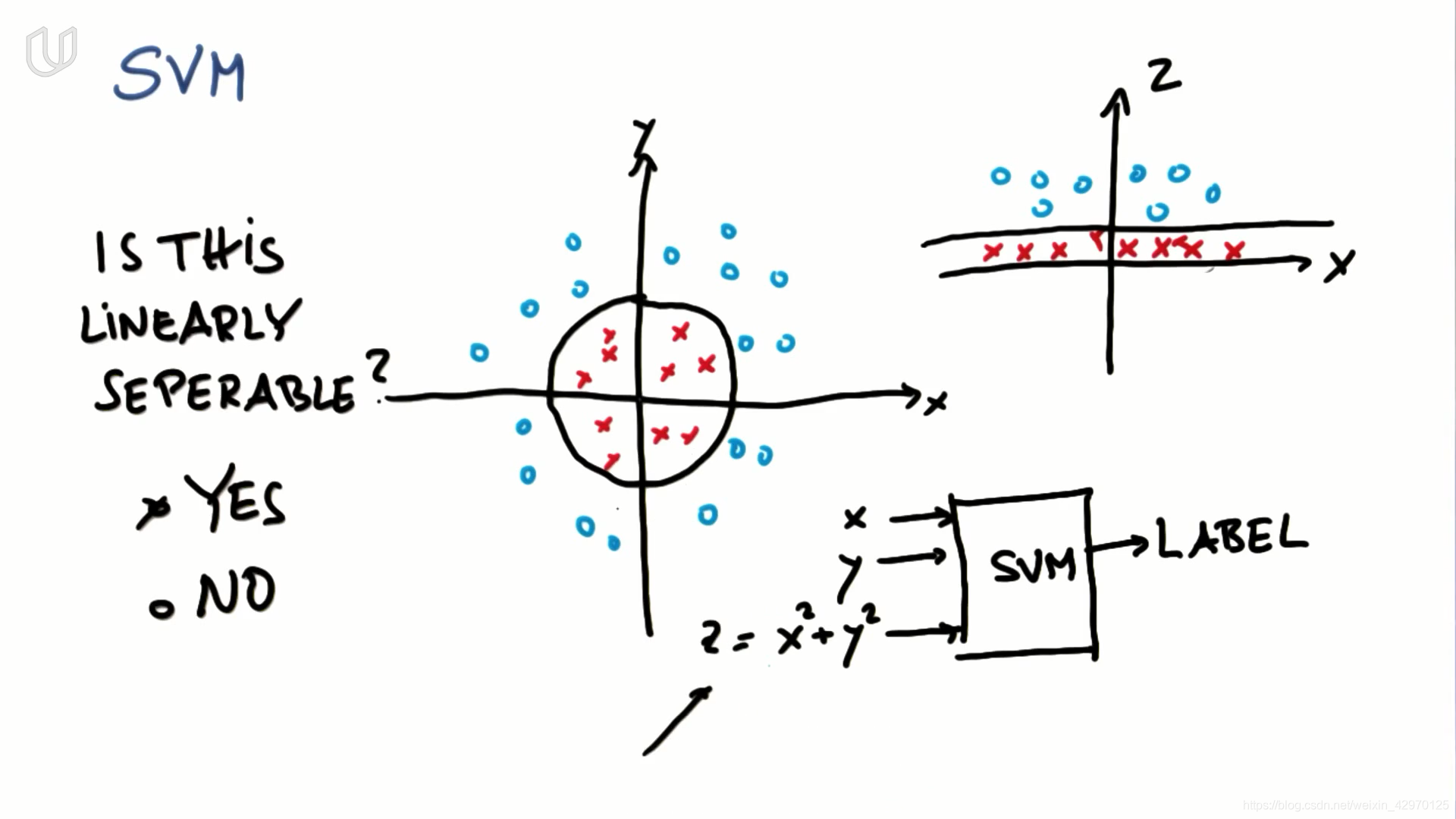
- 增加一个新特征 z = x 2 + y 2 z=x^2+y^2 z=x2+y2, SVM能够以圆的形式学习出非线性的决策边界
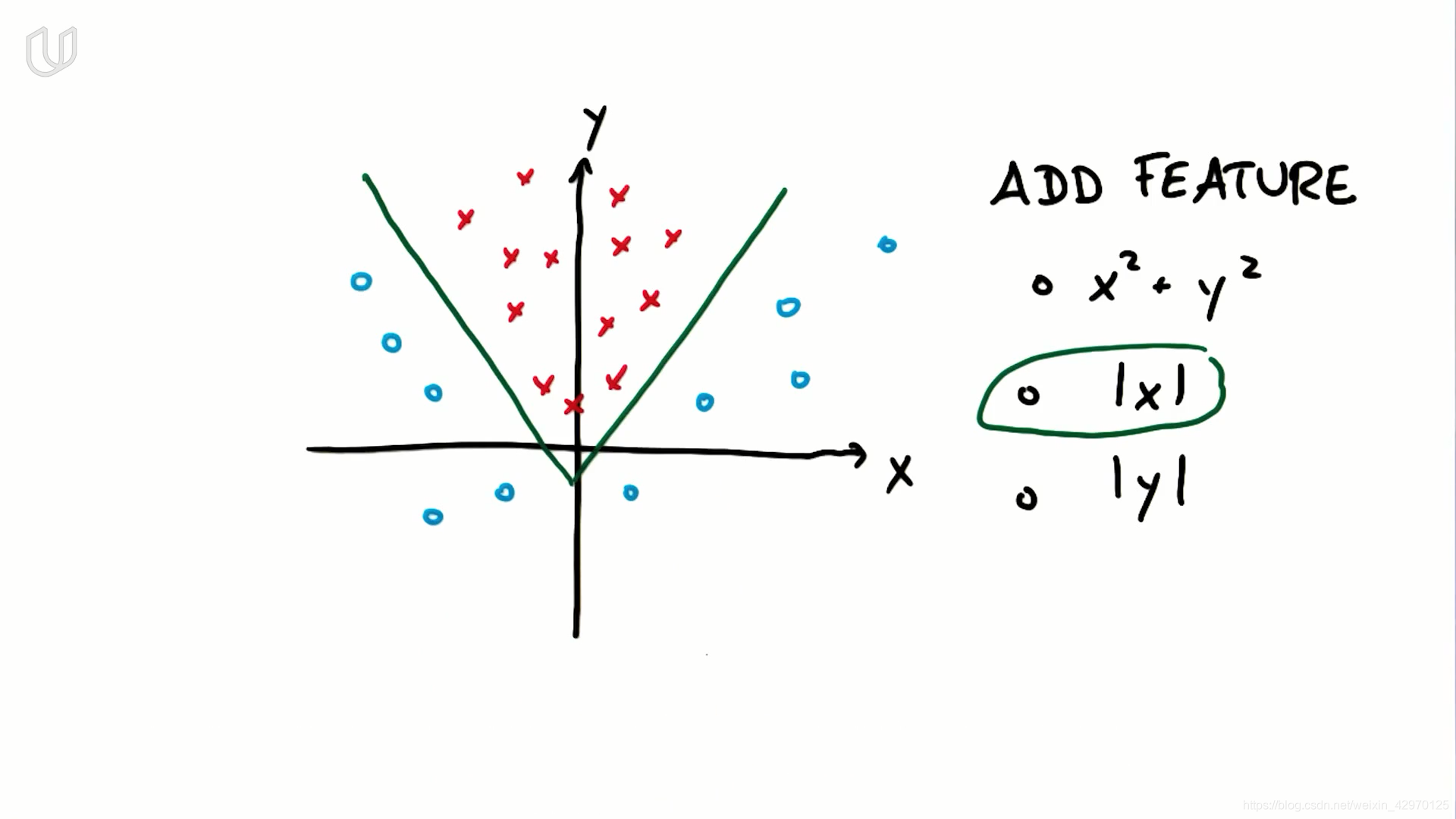
- 对于以上数据集,应增加新特征 |x|
class sklearn.svm.SVC(C=1.0, kernel=’rbf’, degree=3, gamma=’auto_deprecated’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=’ovr’, random_state=None)
gamma : float, optional (default=’auto’)
Kernel coefficient for ‘rbf’, ‘poly’ and ‘sigmoid’.
- 参数C: 决策边界的平滑度和训练数据分类的正确性 的折中,C的值越大,越偏向分类的正确性,越不能容忍出现误差,容易过拟合
- 参数gamma:gamma是选择RBF函数作为kernel后,该函数自带的一个参数。隐含地决定了数据映射到新的特征空间后的分布,gamma越大,支持向量越少,gamma值越小,支持向量越多。支持向量的个数影响训练与预测的速度
拉格朗日乘子法
拉格朗日乘数法是 求多元函数在在其变量受到一个或多个约束条件下的极值的方法。通过引入拉格朗日算子,将d个变量,k个约束条件的最优化问题转化为k+d个变量的无约束优化问题。
无约束优化
对于变量
x
∈
R
N
x\in\R^N
x∈RN的函数 f(x) ,无约束优化问题如下:
min
x
f
(
x
)
\min_xf(x)
xminf(x)
根据 Fermat 定理,直接找到使目标函数得 0 的点即可 即
∇
x
f
(
x
)
=
0
∇_xf(x)=0
∇xf(x)=0 ,如果没有解析解的话,可以使用梯度下降或牛顿方法等迭代的手段来使 x 沿负梯度方向逐步逼近极小值点。
等式约束优化
当目标函数加上约束条件之后,问题就变成如下形式:
min
x
f
(
x
)
\min_x f(x)
xminf(x)
s
.
t
.
h
i
(
x
)
=
0
,
i
=
1
,
2
,
.
.
.
,
m
s.t. \ h_i(x)=0,i=1,2,...,m
s.t. hi(x)=0,i=1,2,...,m
- 约束条件会将解的范围限定在一个可行域,此时不一定能找到使得 ∇ x f ( x ) ∇_xf(x) ∇xf(x)为 0 的点,只需找到在可行域内使得 f(x) 最小的值即可
- 常用的方法即为拉格朗日乘子法,该方法首先引入拉格朗日乘子( Lagrange Multiplier)
α
∈
R
m
α∈\R^m
α∈Rm ,构建 Lagrangian 如下:
L ( x , α ) = f ( x ) + ∑ i m α i h ( x ) L(x,α)=f(x)+\sum_i^mα_ih(x) L(x,α)=f(x)+i∑mαih(x) - 绿线是约束条件h(x),在最优点处,h(x)的法向量(梯度)与f(x)的法向量必定平行(即两者相切),于是有(或+):
∇
x
f
(
x
)
−
α
∇
x
h
(
x
)
=
0
∇_xf(x)-α∇_xh(x)=0
∇xf(x)−α∇xh(x)=0
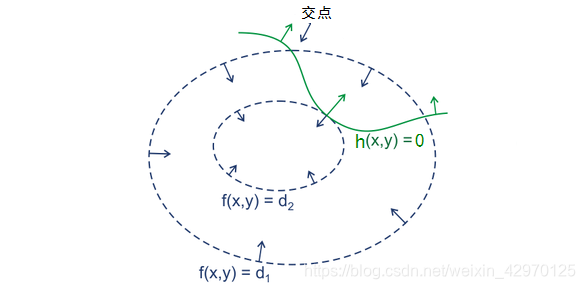
- 求解:(其中
∇
α
L
(
x
,
α
)
=
h
(
x
)
=
0
∇_αL(x,α)=h(x)=0
∇αL(x,α)=h(x)=0即约束条件)
{ ∇ x L ( x , α ) = 0 ∇ α L ( x , α ) = 0 \begin{cases} ∇_xL(x,α)=0\\ ∇_αL(x,α)=0& \end{cases} {∇xL(x,α)=0∇αL(x,α)=0
那么一个带等式约束的优化问题就通过拉格朗日乘子法转化成无约束的优化问题求解
不等式约束优化
- 任何原始问题约束条件无非最多3种,等式约束,大于号约束,小于号约束,而这三种最终通过将约束方程化简化为两类:约束方程等于0和约束方程小于0
- 不等式约束优化:
min x f ( x ) \min_x f(x) xminf(x)
s . t . h ( x ) ≤ 0 s.t.\\ h(x)\le0 s.t.h(x)≤0 - 拉格朗日函数为: L ( x , λ ) = f ( x ) + λ h ( x ) L(x,\lambda)=f(x)+\lambda h(x) L(x,λ)=f(x)+λh(x)
- 当可行解 x 落在 g(x)<0 的区域内,此时直接极小化 f(x) 即可,即约束条件不起作用,即 λ = 0 \lambda=0 λ=0
- 当可行解 x 落在 g(x)=0 即边界上,此时等价于等式约束优化问题。即 h ( x ) = 0 h(x)=0 h(x)=0
- 于是有: λ h ( x ) = 0 \lambda h(x)=0 λh(x)=0
- 在等式约束优化中,约束函数与目标函数的梯度只要满足平行即可,而在不等式约束中则不然,若 λ≠0,这便说明 可行解 x 是落在约束区域的边界上的,这时可行解应尽量靠近无约束时的解
- 梯度方向就是函数值增大的方向,我们的目标是要最小化目标函数,如果最优解在约束边界上,表明g(x)<0 的区域内的目标函数的值要大于目标函数在边界上的值,所以目标函数的梯度应该与约束函数的梯度方向相反,有:
f
(
x
)
+
λ
h
(
x
)
=
0
λ
>
0
f(x)+\lambda h(x)=0\\\lambda >0
f(x)+λh(x)=0λ>0

- 形式化的不等式约束优化问题: min x f ( x ) s . t . h i ( x ) = 0 , i = 1 , 2 , . . . , m g j ( x ) ≤ 0 , j = 1 , 2 , . . . , n \begin{aligned} &\min_x \ f(x) \\ &s.t. \ \ \ h_i(x) = 0 , \ i = 1,2,...,m \ \\ & \ \ \ \ \ \ \ \ \ \ g_j(x) \le 0, \ j = 1,2,...,n \end{aligned} xmin f(x)s.t. hi(x)=0, i=1,2,...,m gj(x)≤0, j=1,2,...,n
- 列出 Lagrangian 得到无约束优化问题:
L ( x , α , β ) = f ( x ) + ∑ i = 1 m α i h i ( x ) + ∑ j = 1 n β i g i ( x ) L(x,\alpha,\beta) =f(x) + \sum_{i=1}^m \alpha_i h_i(x) + \sum_{j=1}^n\beta_ig_i(x) L(x,α,β)=f(x)+i=1∑mαihi(x)+j=1∑nβigi(x) - 加上不等式约束后可行解 x 需要满足的就是以下的 KKT 条件:
∇ x L ( x , α , β ) = 0 β j g j ( x ) = 0 , j = 1 , 2 , . . . , n h i ( x ) = 0 , i = 1 , 2 , . . . , m g j ( x ) ≤ 0 , j = 1 , 2 , . . . , n β j ≥ 0 , j = 1 , 2 , . . . , n \begin{aligned} \nabla_x L(x,\alpha,\beta) &= 0 \\ \beta_jg_j(x) &= 0 , \ j=1,2,...,n\\ h_i(x)&= 0 , \ i=1,2,...,m \\ g_j(x) &\le 0 , \ j=1,2,...,n \\ \beta_j &\ge 0 , \ j=1,2,...,n \\ \end{aligned} ∇xL(x,α,β)βjgj(x)hi(x)gj(x)βj=0=0, j=1,2,...,n=0, i=1,2,...,m≤0, j=1,2,...,n≥0, j=1,2,...,n
例子
-
等式约束:
- 1 问题
m i n f = 2 x 1 2 + 3 x 2 2 + 7 x 3 2 s . t . 2 x 1 + x 2 = 1 2 x 2 + 3 x 3 = 2 min \quad f = 2x_1^2+3x_2^2+7x_3^2 \\s.t. \quad 2x_1+x_2 = 1 \\ \quad \quad \quad 2x_2+3x_3 = 2 minf=2x12+3x22+7x32s.t.2x1+x2=12x2+3x3=2 - 2
m i n f = 2 x 1 2 + 3 x 2 2 + 7 x 3 2 + α 1 ( 2 x 1 + x 2 − 1 ) + α 2 ( 2 x 2 + 3 x 3 − 2 ) min \quad f = 2x_1^2+3x_2^2+7x_3^2 +\alpha _1(2x_1+x_2- 1)+\alpha _2(2x_2+3x_3 - 2) minf=2x12+3x22+7x32+α1(2x1+x2−1)+α2(2x2+3x3−2) - 3
∂ f ∂ x 1 = 4 x 1 + 2 α 1 = 0 ⇒ x 1 = − 0.5 α 1 ∂ f ∂ x 2 = 6 x 2 + α 1 + 2 α 2 = 0 ⇒ x 2 = − α 1 + 2 α 2 6 ∂ f ∂ x 3 = 14 x 3 + 3 α 2 = 0 ⇒ x 3 = − 3 α 2 14 \dfrac{\partial f}{\partial x_1}=4x_1+2\alpha_1=0\Rightarrow x_1=-0.5\alpha_1 \\ \dfrac{\partial f}{\partial x_2}=6x_2+\alpha_1+2\alpha_2=0\Rightarrow x_2=-\dfrac{\alpha_1+2\alpha_2}{6} \\ \dfrac{\partial f}{\partial x_3}=14x_3+3\alpha_2=0\Rightarrow x_3=-\dfrac{3\alpha_2}{14} ∂x1∂f=4x1+2α1=0⇒x1=−0.5α1∂x2∂f=6x2+α1+2α2=0⇒x2=−6α1+2α2∂x3∂f=14x3+3α2=0⇒x3=−143α2 - 4 把它在代到约束条件中去,可以看到,2个变量两个等式,可以求解,最终可以得到 α 1 = − 0.39 , α 2 = − 1.63 \alpha_1=-0.39,\alpha_2=-1.63 α1=−0.39,α2=−1.63
- 1 问题
-
不等式约束:
- 1 问题: m i n f = x 1 2 − 2 x 1 + 1 + x 2 2 + 4 x 2 + 4 s . t . x 1 + 10 x 2 > 10 10 x 1 − 10 x 2 < 10 min \quad f = x_1^2-2x_1+1+x_2^2+4x_2+4 \\s.t. \quad x_1+10x_2 > 10 \\ \quad \quad \quad 10 x_1-10x_2 < 10 minf=x12−2x1+1+x22+4x2+4s.t.x1+10x2>1010x1−10x2<10
- 2 L ( x , α ) = f ( x ) + α 1 g 1 ( x ) + α 2 g 2 ( x ) = x 1 2 − 2 x 1 + 1 + x 2 2 + 4 x 2 + 4 + α 1 ( 10 − x 1 − 10 x 2 ) + α 2 ( 10 x 1 − x 2 − 10 ) L(x,\alpha) = f(x) + \alpha_1g1(x)+\alpha_2g2(x)\\ =x_1^2-2x_1+1+x_2^2+4x_2+4+ \alpha_1(10-x_1-10x_2 ) +\\\alpha_2(10x_1-x_2 - 10) L(x,α)=f(x)+α1g1(x)+α2g2(x)=x12−2x1+1+x22+4x2+4+α1(10−x1−10x2)+α2(10x1−x2−10)
- 3 此时分别对x1、x2求导数: ∂ L ∂ x 1 = 2 x 1 − 2 − α 1 + 10 α 2 = 0 ⇒ x 1 = 0.5 ( α 1 − 10 α 2 + 2 ) ∂ L ∂ x 2 = 2 x 2 + 4 − 10 α 1 − α 2 = 0 ⇒ x 2 = 0.5 ( 10 α 1 + α 2 − 4 ) \dfrac{\partial L}{\partial x_1}=2x_1-2-\alpha_1+10\alpha_2=0\Rightarrow x_1=0.5(\alpha_1-10\alpha_2+2) \\ \dfrac{\partial L}{\partial x_2}=2x_2+4-10\alpha_1-\alpha_2=0\Rightarrow x_2=0.5(10\alpha_1+\alpha_2-4) ∂x1∂L=2x1−2−α1+10α2=0⇒x1=0.5(α1−10α2+2)∂x2∂L=2x2+4−10α1−α2=0⇒x2=0.5(10α1+α2−4)
- 4 还有一个条件就是α∗g(x)=0,那么也就是 α 1 ∗ g 1 ( x ) = α 1 ∗ ( 10 − x 1 − 10 x 2 ) = 0 α 2 ∗ g 2 ( x ) = α 2 ∗ ( 10 x 1 − x 2 − 10 ) = 0 \alpha_1*g_1(x)=\alpha_1*(10-x_1-10x_2)=0\\\alpha_2*g_2(x)=\alpha_2*(10x_1-x_2 - 10)=0 α1∗g1(x)=α1∗(10−x1−10x2)=0α2∗g2(x)=α2∗(10x1−x2−10)=0
- (1)α1=α2=0α1=α2=0,那么看上面的关系可以得到x1=1,x2=−1x1=1,x2=−1,再把两个x带到不等式约束,发现第一个就是需要满足(10-1+20=29<0)显然不行,29>0的。舍弃
(2)g1(x)=g2(x)=0g1(x)=g2(x)=0,带进去解得,x1=110/101;x2=90/101,再带回去求解α1,α2α1,α2,发现α1=58/101,α2=4/101α1=58/101,α2=4/101,它们满足大于0的条件,那么显然这组解是可以的。
(3)其他两种情况再去讨论发现是不行的。
拉格朗日对偶
L
(
x
,
α
,
β
)
=
f
(
x
)
+
∑
i
=
1
m
α
i
h
i
(
x
)
+
∑
j
=
1
n
β
i
g
i
(
x
)
L(x,\alpha,\beta) =f(x) + \sum_{i=1}^m \alpha_i h_i(x) + \sum_{j=1}^n\beta_ig_i(x)
L(x,α,β)=f(x)+i=1∑mαihi(x)+j=1∑nβigi(x)
因为
h
i
(
x
)
≤
0
,
α
≥
0
,
g
i
(
x
)
=
0
h_i(x)\le0,\alpha\ge0,g_i(x)=0
hi(x)≤0,α≥0,gi(x)=0,所以如果把
L
(
x
,
α
,
β
)
L(x,\alpha,\beta)
L(x,α,β) 看作是
α
i
,
β
i
\alpha_i,\beta_i
αi,βi的函数,有:
max
α
,
β
:
α
i
≥
0
L
(
x
,
α
,
β
)
=
{
f
(
x
)
,
if
x
满足原始问题约束
+
∞
,
if 其他
\max_ {\alpha,\beta:\alpha_i\ge0} L(x,\alpha,\beta) = \begin{cases} f(x), & \text{if $x$ 满足原始问题约束} \\ +\infty, & \text{if 其他} \end{cases}
α,β:αi≥0maxL(x,α,β)={f(x),+∞,if x 满足原始问题约束if 其他
- 原问题(primal problem): p ∗ = min x max α , β L ( x , α , β ) p^*=\min_x\max_{\alpha,\beta}L(x,\alpha,\beta) p∗=xminα,βmaxL(x,α,β)
- 对偶问题(dual problem): d ∗ = max α , β min x L ( x , α , β ) d^*=\max_{\alpha,\beta}\min_xL(x,\alpha,\beta) d∗=α,βmaxxminL(x,α,β)
- 通常, p ∗ ≥ d ∗ p^*\ge d^* p∗≥d∗ 即对偶问题的最优解是原始问题最优解的下限(弱对偶性)
- 但如果是满足KKT条件的方程组的解
∇
x
,
α
,
β
L
(
x
,
α
,
β
)
=
0
β
j
g
j
(
x
)
=
0
,
j
=
1
,
2
,
.
.
.
,
n
g
j
(
x
)
≤
0
,
j
=
1
,
2
,
.
.
.
,
n
β
j
≥
0
,
j
=
1
,
2
,
.
.
.
,
n
\begin{aligned} \nabla_{x,\alpha,\beta} L(x,\alpha,\beta) &= 0 \\ \beta_jg_j(x) &= 0 , \ j=1,2,...,n\\ g_j(x) &\le 0 , \ j=1,2,...,n \\ \beta_j &\ge 0 , \ j=1,2,...,n \\ \end{aligned}
∇x,α,βL(x,α,β)βjgj(x)gj(x)βj=0=0, j=1,2,...,n≤0, j=1,2,...,n≥0, j=1,2,...,n
此时, p ∗ = d ∗ p^*=d^* p∗=d∗强对偶性,原始问题和对偶问题的最优解严格相等
当f(x)和g(x)为凸函数,h(x)为仿射函数时,p*= d* - 因为 β g ( x ) = 0 \beta g(x) = 0 βg(x)=0,即 L ( x , α , β ) = f ( x ) L(x,\alpha,\beta) =f(x) L(x,α,β)=f(x),所以具有强对偶性
支持向量机的对偶
- 支持向量机最大间隔化下的损失函数:
min 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , . . . , m \min \frac{1}{2}||w||^2\\ s.t.\ y_i(w^Tx_i+b)\ge1,i=1,2,...,m min21∣∣w∣∣2s.t. yi(wTxi+b)≥1,i=1,2,...,m
约束条件可以写成:
g i ( w ) = 1 − y i ( w T x i + b ) ≤ 0 g_i(\mathbf w)=1-y_i(\mathbf w^T\mathbf x_i+b)\le0 gi(w)=1−yi(wTxi+b)≤0 - 构造拉格朗日函数: L ( w , b , λ ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i m λ i ( 1 − y i ( w T x i + b ) ) L(\mathbf w,b,\mathbf \lambda) = \frac{1}{2}||w||^2+\sum_i^m \lambda_i(1-y_i(\mathbf w^T\mathbf x_i+b)) L(w,b,λ)=21∣∣w∣∣2+i∑mλi(1−yi(wTxi+b))
- 对偶问题的形式,先求
L
(
w
,
b
,
λ
)
L(\mathbf w,b,\mathbf \lambda)
L(w,b,λ)对w,b的极小,再求对
λ
\lambda
λ的极大
- 1 求
min
w
,
b
L
(
w
,
b
,
λ
)
\min_{w,b} L(\mathbf w,b,\mathbf \lambda)
minw,bL(w,b,λ),将拉格朗日函数分别对 w,b 求偏导并令其等于0:
∇ w L ( w , b , λ ) = w − ∑ i m λ i y i x i = 0 , w = ∑ i m λ i y i x i ∇ b L ( w , b , λ ) = ∑ i m λ i y i = 0 \nabla_wL(\mathbf w,b,\mathbf \lambda)=\mathbf w-\sum_i^m \lambda_iy_i\mathbf x_i=0,\\ \mathbf w=\sum_i^m \lambda_iy_i\mathbf x_i\\ \nabla_bL(\mathbf w,b,\mathbf \lambda)=\sum_i^m \lambda_iy_i=0 ∇wL(w,b,λ)=w−i∑mλiyixi=0,w=i∑mλiyixi∇bL(w,b,λ)=i∑mλiyi=0 - 2 将以上求得代入拉格朗日函数:
L ( w , b , λ ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i m λ i ( 1 − y i ( w T x i + b ) ) = 1 2 ∑ i m ∑ j m λ i λ j y i y j ( x i ⋅ x j ) + ∑ i m λ i − ∑ i m ∑ j m λ i λ j y i y j ( x i ⋅ x j ) = − 1 2 ∑ i m ∑ j m λ i λ j y i y j ( x i ⋅ x j ) + ∑ i m λ i L(\mathbf w,b,\mathbf \lambda) = \frac{1}{2}||w||^2+\sum_i^m \lambda_i(1-y_i(\mathbf w^T\mathbf x_i+b)) \\ = \frac{1}{2}\sum_i^m \sum_j^m \lambda_i\lambda_jy_iy_j(\mathbf x_i\cdot\mathbf x_j)+\sum_i^m \lambda_i-\sum_i^m \sum_j^m \lambda_i\lambda_jy_iy_j(\mathbf x_i\cdot\mathbf x_j)\\ =- \frac{1}{2}\sum_i^m \sum_j^m \lambda_i\lambda_jy_iy_j(\mathbf x_i\cdot\mathbf x_j)+\sum_i^m \lambda_i L(w,b,λ)=21∣∣w∣∣2+i∑mλi(1−yi(wTxi+b))=21i∑mj∑mλiλjyiyj(xi⋅xj)+i∑mλi−i∑mj∑mλiλjyiyj(xi⋅xj)=−21i∑mj∑mλiλjyiyj(xi⋅xj)+i∑mλi - 3 以上得出的式子就是
L
(
w
,
b
,
λ
)
L(\mathbf w,b,\mathbf \lambda)
L(w,b,λ)对w,b的极小:
m
i
n
w
,
b
L
(
w
,
b
,
λ
)
min_{\mathbf w,b} L(\mathbf w,b,\mathbf \lambda)
minw,bL(w,b,λ);下面需要继续求这个式子对
λ
\lambda
λ的极大:
max λ W ( λ ) = max λ − 1 2 ∑ i m ∑ j m λ i λ j y i y j ( x i ⋅ x j ) + ∑ i m λ i \max_\lambda W(\lambda)=\max_\lambda - \frac{1}{2}\sum_i^m \sum_j^m \lambda_i\lambda_jy_iy_j(\mathbf x_i\cdot\mathbf x_j)+\sum_i^m \lambda_i λmaxW(λ)=λmax−21i∑mj∑mλiλjyiyj(xi⋅xj)+i∑mλi
或可以将求极大转换为求极小:
min λ W ( λ ) = min λ 1 2 ∑ i m ∑ j m λ i λ j y i y j ( x i ⋅ x j ) − ∑ i m λ i \min_\lambda W(\lambda)=\min_\lambda \frac{1}{2}\sum_i^m \sum_j^m \lambda_i\lambda_jy_iy_j(\mathbf x_i\cdot\mathbf x_j)-\sum_i^m \lambda_i λminW(λ)=λmin21i∑mj∑mλiλjyiyj(xi⋅xj)−i∑mλi
s . t . ∑ i m λ i y i = 0 λ ≥ 0 , i = 1 , 2 , . . . , m s.t.\ \ \sum_i^m \lambda_iy_i=0\\ \lambda\ge0,i=1,2,...,m s.t. i∑mλiyi=0λ≥0,i=1,2,...,m
并且满足KKT条件 1 − y i f ( x i ) ≤ 0 λ ( 1 − y i f ( x i ) ) = 0 λ ≥ 0 1-y_if(\mathbf x_i)\le0\\ \lambda(1-y_if(\mathbf x_i))=0\\ \lambda\ge0 1−yif(xi)≤0λ(1−yif(xi))=0λ≥0
- 1 求
min
w
,
b
L
(
w
,
b
,
λ
)
\min_{w,b} L(\mathbf w,b,\mathbf \lambda)
minw,bL(w,b,λ),将拉格朗日函数分别对 w,b 求偏导并令其等于0:
线性可分支持向量机的学习算法 r4p106
输入:线性可分训练集
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
m
,
y
m
)
,
}
T=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m),\}
T={(x1,y1),(x2,y2),...,(xm,ym),},其中
x
u
∈
R
n
,
y
∈
{
−
1
,
1
}
,
i
=
1
,
2
,
.
.
.
,
m
x_u \in\R^n,y\in\{-1,1\},i=1,2,...,m
xu∈Rn,y∈{−1,1},i=1,2,...,m
输出:分离超平面和分类决策函数
1) 构造并求解约束最优化问题
min
λ
W
(
λ
)
=
min
λ
1
2
∑
i
m
∑
j
m
λ
i
λ
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
m
λ
i
s
.
t
.
∑
i
m
λ
i
y
i
=
0
λ
≥
0
,
i
=
1
,
2
,
.
.
.
,
m
\min_\lambda W(\lambda)=\min_\lambda \frac{1}{2}\sum_i^m \sum_j^m \lambda_i\lambda_jy_iy_j(\mathbf x_i\cdot\mathbf x_j)-\sum_i^m \lambda_i\\ s.t.\ \ \sum_i^m \lambda_iy_i=0\\ \lambda\ge0,i=1,2,...,m
λminW(λ)=λmin21i∑mj∑mλiλjyiyj(xi⋅xj)−i∑mλis.t. i∑mλiyi=0λ≥0,i=1,2,...,m
求得最优解
λ
∗
=
(
λ
1
∗
,
λ
2
∗
)
,
.
.
.
,
λ
m
∗
)
\lambda^*=(\lambda_1^*,\lambda_2^*),...,\lambda_m^*)
λ∗=(λ1∗,λ2∗),...,λm∗)
这是一个二次规划问题,可通过二次规划算法求解;然而该问题的规模正比于训练样本数,在实际任务中会有很大的开销
SMO(Sequential Minimal Optimization)算法是解决这个问题的一个高效的算法
- 计算
w
∗
=
∑
i
m
λ
i
∗
y
i
x
i
\mathbf w^*=\sum_i^m \lambda_i^*y_i\mathbf x_i
w∗=i∑mλi∗yixi
选取 λ ∗ \lambda^* λ∗的任一正分量 λ j ∗ > 0 \lambda^*_j>0 λj∗>0,计算 b ∗ = y j − ∑ i m λ i y i ( x i ⋅ x j ) b^*=y_j-\sum_i^m\lambda_iy_i(x_i\cdot x_j) b∗=yj−i∑mλiyi(xi⋅xj)
b ∗ b^* b∗的求解过程:
在最优解 λ ∗ \lambda^* λ∗中至少有一个 λ j ∗ > 0 \lambda_j^*>0 λj∗>0,根据KKT条件 λ ( 1 − y i f ( x i ) ) = 0 \lambda(1-y_if(\mathbf x_i))=0 λ(1−yif(xi))=0 有:
λ j ( 1 − y j ( w ⋅ x j + b ) ) = 0 1 − y j ( ∑ i m λ i y i ( x i ⋅ x j ) + b ) = 0 \lambda_j(1-y_j(\mathbf w\cdot\mathbf x_j+b))=0\\ 1-y_j(\sum_i^m\lambda_i y_i(\mathbf x_i\cdot\mathbf x_j)+b)=0 λj(1−yj(w⋅xj+b))=01−yj(i∑mλiyi(xi⋅xj)+b)=0
因为总有 y j 2 = 1 y_j^2=1 yj2=1
所以: b = y j − ∑ i m λ i y i ( x i ⋅ x j ) b=y_j-\sum_i^m\lambda_i y_i(\mathbf x_i\cdot\mathbf x_j) b=yj−i∑mλiyi(xi⋅xj)
- 求得分离超平面:
w
∗
⋅
x
+
b
∗
=
0
\mathbf w^*\cdot \mathbf x +b^*=0
w∗⋅x+b∗=0
分类决策函数: f ( x ) = s i g n ( w ∗ ⋅ x + b ∗ ) f(x)=sign(\mathbf w^*\cdot \mathbf x +b^*) f(x)=sign(w∗⋅x+b∗)
- 示例见r4p107
- 在最大化决策间隔时,必然有一些点落在间隔的边界上,这些点就是支持向量。有KKT条件
λ
∗
(
y
i
(
w
∗
⋅
x
i
+
b
)
−
1
)
=
0
\lambda^*(y_i(\mathbf w^*\cdot \mathbf x_i+b)-1)=0
λ∗(yi(w∗⋅xi+b)−1)=0
对于 λ ∗ > 0 \lambda^*>0 λ∗>0的实例 x i \mathbf x_i xi,有 y i ( w ∗ ⋅ x i + b ) − 1 = 0 y_i(\mathbf w^*\cdot \mathbf x_i+b)-1=0 yi(w∗⋅xi+b)−1=0 或 w ∗ ⋅ x i + b = ± 1 \mathbf w^*\cdot \mathbf x_i+b=\pm1 w∗⋅xi+b=±1
可见 支持向量是一定落在间隔边界上














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









