







1 算法简介
RANSAC算法的基本假设是样本中包含正确数据(inliers,可以被模型描述的数据),也包含异常数据(outlies,偏离正常范围很远、无法适应数学模型的数据),即数据集中含有噪声。这些异常数据可能是由于错误的测量、错误的假设、错误的计算等产生的。同时RANSAC也假设,给定一组正确的数据,存在可以计算出符合这些数据的模型参数的方法。
2 基本思想
RANSAC基本思想描述如下:
- 考虑一个最小抽样集的势为n的模型(n为初始化模型参数所需的最小样本数)和一个样本集P,集合P的样本数#§>n,从P中随机抽取包含n个样本的P的子集S,来初始化模型M;
- 余集SC=P\S中与模型M的误差小于某一设定阈值t的样本集以及S构成S*。S*认为是内点集,它们构成S的一致集(Consensus Set);
- 若#(S*)≥N,认为得到正确的模型参数,并利用集S*(内点inliers)采用最小二乘等方法重新计算新的模型M*;重新随机抽取新的S,重复以上过程。
- 在完成一定的抽样次数后,若未找到一致集则算法失败,否则选取抽样后得到的最大一致集判断内外点,算法结束。
3 参数
t —— 用于决定数据是否适应于模型的阀值
N —— 判定模型是否适用于数据集的数据数目
k —— 迭代次数
我们不得不根据特定的问题和数据集,通过实验来确定参数t和N。然而参数k(迭代次数)可以从理论结果推断。当我们在估计模型参数时,用p表示一些迭代过程中从数据集内随机选取出的点均为局内点的概率;此时,结果模型很可能有用,因此p也表征了算法产生有用结果的概率。用w表示每次从数据集中选取一个局内点的概率,如下式所示:
w = 局内点的数目 / 数据集的数目
通常情况下,我们事先并不知道w的值,但是可以给出一些鲁棒的值。假设估计模型需要选定n个点, 是所有n个点均为局内点的概率;1− 是n个点中至少有一个点为局外点的概率,此时表明我们从数据集中估计出了一个不好的模型。表示算法永远都不会选择到n个点均为局内点的概率,它和1-p相同。因此,
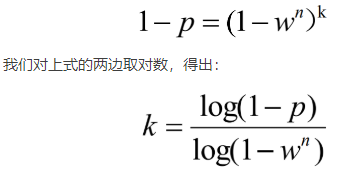
值得注意的是,这个结果假设n个点都是独立选择的;也就是说,某个点被选定之后,它可能会被后续的迭代过程重复选定到。这种方法通常都不合理,由此推导出的k值被看作是选取不重复点的上限。例如,RANSAC算法拟合直线时,通常在每次迭代时选取2个点,计算通过这两点的直线maybe_model,要求这两点必须唯一。
为了得到更可信的参数,标准偏差或它的乘积可以被加到k上。k的标准偏差定义为: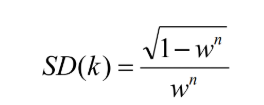
4 应用案例(直线拟合)
- 随机选取2个点
- 由这2个点计算直线方程
- 计算所有点到直线的距离
- 得到满足条件(点到直线的距离小于预先设定的某个值)的点的数量
- 循环1-4步骤,记录点数最多的那组直线

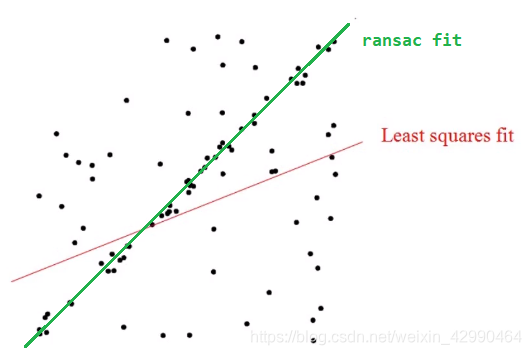
与最小二乘法拟合直线的对比如下图:
其他应用
-
特征点匹配滤除误匹配的点
-
相机位姿估计
-
图像拼接和点云匹配融合等















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











