






AWS Glue 是 Amazon 的一项 ETL 服务,可让您轻松准备和加载数据以进行存储和分析。 使用 PySpark 模块和 AWS Glue,您可以创建通过 JDBC 连接处理数据的作业,将数据直接加载到 AWS 数据存储中。 在本文中,我们将介绍将 BigQuery 的 CData JDBC 驱动程序上传到 Amazon S3 存储桶,并创建和运行 AWS Glue 作业以提取 BigQuery 数据并将其作为 CSV 文件存储在 S3 中。
Upload the CData JDBC Driver for BigQuery to an Amazon S3 Bucket
为了在 AWS Glue 中使用适用于 BigQuery 的 CData JDBC 驱动程序,您需要将其(以及任何相关的许可证文件)存储在 Amazon S3 存储桶中。
- 打开 Amazon S3 控制台。
- 选择一个现有存储桶(或创建一个新存储桶)。
- 点击上传
- 选择驱动程序安装位置的 lib 目录中的 JAR 文件 (cdata.jdbc.googlebigquery.jar)。
Configure the Amazon Glue Job
- 从 AWS Glue 控制台导航到 ETL -> 作业。
- 单击添加作业以创建新的Glue作业。
3.填写作业属性:
-
名称: 填写作业的名称,例如:GoogleBigQueryGlueJob。
-
IAM 角色: 选择(或创建)具有 AWSGlueServiceRole 和 AmazonS3FullAccess 权限策略的 IAM 角色。后一种策略是访问 JDBC 驱动程序和 Amazon S3 中的输出目标所必需的。
-
类型: 选择“Spark”。
-
胶水版本: 选择“Spark 2.4, Python 3 (Glue Version 1.0)”。
-
此作业运行: 选择“A new script to be authored by you”。
填充脚本属性: -
- 脚本文件名: 脚本文件的名称,例如:GlueGoogleBigQueryJDBC
- 存储脚本的 S3 路径: 填写或浏览到 S3 存储桶。
- 临时目录: 填写或浏览到 S3 存储桶。
-
展开安全配置、脚本库和作业参数(可选)。对于 Dependent jars path,填写或浏览到您上传 JAR 文件的 S3 存储桶。请务必在路径中包含 JAR 文件本身的名称,即:s3://mybucket/cdata.jdbc.googlebigquery.jar
-
单击下一步。在这里,您可以选择添加与其他 AWS 端点的连接。因此,如果您的目标是 Redshift、MySQL 等,您可以创建和使用与这些数据源的连接。
-
单击“保存作业并编辑脚本”以创建作业。
-
在打开的编辑器中,为该作业编写一个 python 脚本。您可以使用示例脚本(见下文)作为示例。
Sample Glue Script
要使用 CData JDBC 驱动程序连接到 BigQuery,您需要创建一个 JDBC URL,填充必要的连接属性。 此外,您需要在 JDBC URL 中设置 RTK 属性(除非您使用的是 Beta 驱动程序)。 您可以查看安装中包含的许可文件以获取有关如何设置此属性的信息。
Google 使用 OAuth 身份验证标准。 要代表个人用户访问 Google API,您可以使用嵌入式凭据,也可以注册自己的 OAuth 应用程序。
OAuth 还允许您使用服务帐户代表 Google Apps 域中的用户进行连接。 要使用服务帐户进行身份验证,您需要注册应用程序以获取 OAuth JWT 值。
除了 OAuth 值之外,您还需要指定 DatasetId 和 ProjectId。 有关使用 OAuth 的指南,请参阅帮助文档的“入门”一章。
Built-in Connection String Designer
如需帮助构建 JDBC URL,请使用 BigQuery JDBC 驱动程序中内置的连接字符串设计器。 双击 JAR 文件或从命令行执行 JAR 文件。
view sourcejava -jar cdata.jdbc.googlebigquery.jar
Fill in the connection properties and copy the connection string to the clipboard.
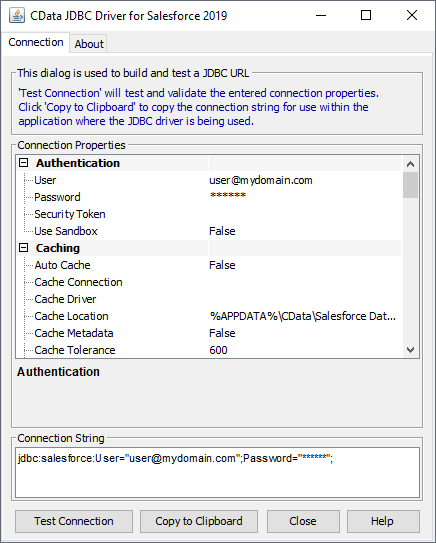
要在 Amazon S3 中托管 JDBC 驱动程序,您需要一个许可证(完整版或试用版)和一个运行时密钥 (RTK)。 有关获取此许可证(或试用)的更多信息,联系我们的销售团队。
下面是一个示例脚本,它使用带有 PySpark 和 AWSGlue 模块的 CData JDBC 驱动程序来提取 BigQuery 数据并将其写入 CSV 格式的 S3 存储桶。 对脚本进行任何必要的更改以满足您的需要并保存作业。
view sourceimport sysfrom awsglue.transforms import *from awsglue.utils import getResolvedOptionsfrom pyspark.context import SparkContextfrom awsglue.context import GlueContextfrom awsglue.dynamicframe import DynamicFramefrom awsglue.job import Job args = getResolvedOptions(sys.argv, ['JOB_NAME']) sparkContext = SparkContext()glueContext = GlueContext(sparkContext)sparkSession = glueContext.spark_session ##Use the CData JDBC driver to read BigQuery data from the Orders table into a DataFrame##Note the populated JDBC URL and driver class namesource_df = sparkSession.read.format("jdbc").option("url","jdbc:googlebigquery:RTK=5246...;DataSetId=MyDataSetId;ProjectId=MyProjectId;").option("dbtable","Orders").option("driver","cdata.jdbc.googlebigquery.GoogleBigQueryDriver").load() glueJob = Job(glueContext)glueJob.init(args['JOB_NAME'], args) ##Convert DataFrames to AWS Glue's DynamicFrames Objectdynamic_dframe = DynamicFrame.fromDF(source_df, glueContext, "dynamic_df") ##Write the DynamicFrame as a file in CSV format to a folder in an S3 bucket.##It is possible to write to any Amazon data store (SQL Server, Redshift, etc) by using any previously defined connections.retDatasink4 = glueContext.write_dynamic_frame.from_options(frame = dynamic_dframe, connection_type = "s3", connection_options = {"path": "s3://mybucket/outfiles"}, format = "csv", transformation_ctx = "datasink4") glueJob.commit()
Run the Glue Job
编写好脚本后,我们就可以运行 Glue 作业了。 单击运行作业并等待提取/加载完成。 您可以从 AWS Glue 控制台的作业页面查看作业的状态。 作业成功后,您的 S3 存储桶中将有一个 CSV 文件,其中包含 BigQuery Orders 表中的数据。
使用 AWS Glue 中用于 BigQuery 的 CData JDBC 驱动程序,您可以轻松地为 BigQuery 数据创建 ETL 作业,无论是将数据写入 S3 存储桶还是将其加载到任何其他 AWS 数据存储中。
任何程序错误,以及技术疑问或需要解答的

















 1037
1037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









