









写在前面
最近要做一个基于无监督学习的传统图像分类,需要使用到聚类分析方法,但看到网上大多数都是关于点集的案例分析,基于自然图像的聚类分析实在是难觅,于是乎花了将近一周时间,参照着 Programming Computer Vision with Python 这本书以及相关文章进行了研究1,并实现了MNIST图像的谱聚类小案例(代码已在GitHub开源2),以记录之。
谱聚类简介
谱聚类是从图论中演化出来的算法,后来在聚类中得到了广泛的应用。它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的3。谱聚类的聚类效果通常优于传统的聚类算法(如K-Means算法)。
数据集
本案例使用MNIST手写数字图像数据集,首先选取合适的图像,并整理如下图所示:

代码实现步骤详述
图像预处理
由于谱聚类对图像尺寸和文件名有要求,所以首先对图像进行灰度化和resize操作,分别对应项目中的grayscale_processing.py和picture_resize.py这两个代码文件。
谱聚类操作
在项目中的spectral_clustering.py代码文件中,进行图像的谱聚类。代码如下:
# -*- coding: utf-8 -*-
from PCV.tools import imtools, pca
from PIL import Image, ImageDraw
from pylab import *
from scipy.cluster.vq import *
import os
import random
# imlist = imtools.get_imlist('./dir_my')
imlist = imtools.get_imlist('./dir_my_gray_rescale')
imnbr = len(imlist)
# Load images, run PCA.
immatrix = array([array(Image.open(im)).flatten() for im in imlist], 'f')
V, S, immean = pca.pca(immatrix)
# Project on 2 PCs.
projected = array([dot(V[[0, 1]], immatrix[i] - immean)
for i in range(imnbr)]) # P131 Fig6-3左图
#projected = array([dot(V[[1, 2]], immatrix[i] - immean) for i in range(imnbr)]) # P131 Fig6-3右图
n = len(projected)
# compute distance matrix
S = array([[sqrt(sum((projected[i]-projected[j])**2))
for i in range(n)] for j in range(n)], 'f')
# create Laplacian matrix
rowsum = sum(S, axis=0)
D = diag(1/sqrt(rowsum))
I = identity(n)
L = I - dot(D, dot(S,D))
# compute eigenvectors of L
U, sigma, V = linalg.svd(L)
k = 3
# create feature vector from k first eigenvectors
# by stacking eigenvectors as columns
features = array(V[:k]).T
# k-means
features = whiten(features)
centroids, distortion = kmeans(features,k)
code, distance = vq(features, centroids)
# plot clusters 绘制聚类簇
for c in range(k):
ind = where(code == c)[0] # where函数返回数组的索引值
figure() # 创建figure实例
gray()
for i in range(minimum(len(ind), 39)):
# print(imlist[ind[i]]) # ./dir_my_gray_rescale\5.jpg
im = Image.open(imlist[ind[i]])
# print("im:%s" % im) # im:<PIL.JpegImagePlugin.JpegImageFile image mode=L size=28x28 at 0x241B9DD2EF0>
image_name = imlist[ind[i]].split("\\")[1] # image_name: 5.jpg
image_name_real = image_name.split(".")[0] # image_name_real: 1_1
image_name_new = image_name_real + ".png"
# print(image_name_new) # image_name_new: 1_1.png
# print("image_name: %s" % image_name)
# print("image_name_real: %s" % image_name_real)
subplot(4, 10, i+1)
imshow(array(im)) # 绘图
# print("array(im)的值为%s" % array(im))
# 使用imsave()函数保存图像
pre_savename = "./dir_classfied_my/%02d/" % c # "./dir/00"
# savename = os.path.join(pre_savename, str(random.randint(0, 10000000)))
savename = os.path.join(pre_savename, image_name_new)
imsave(savename, array(im))
axis('equal')
axis('off')
show()
聚类后的MNIST图像数据如下图所示:

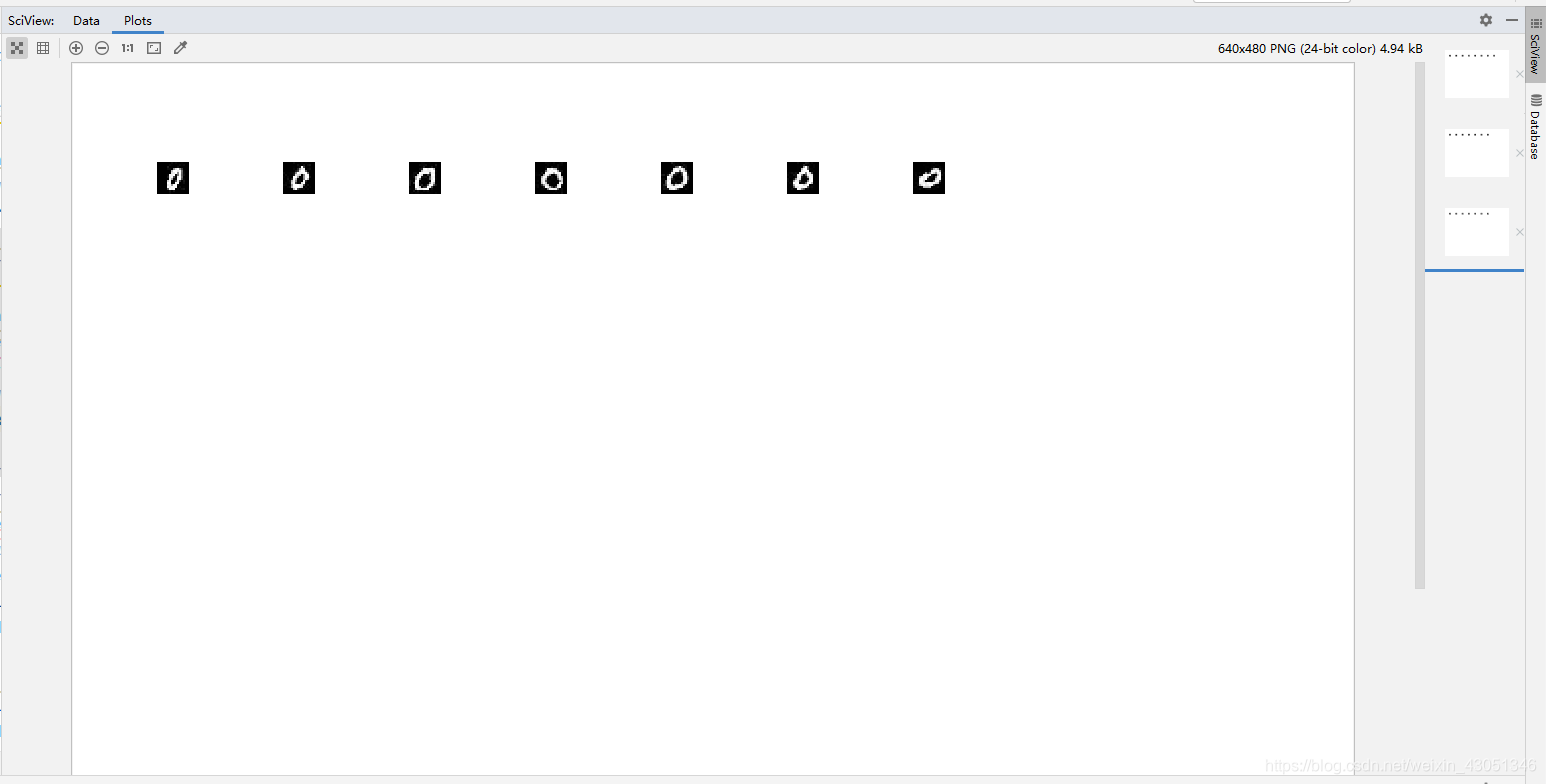
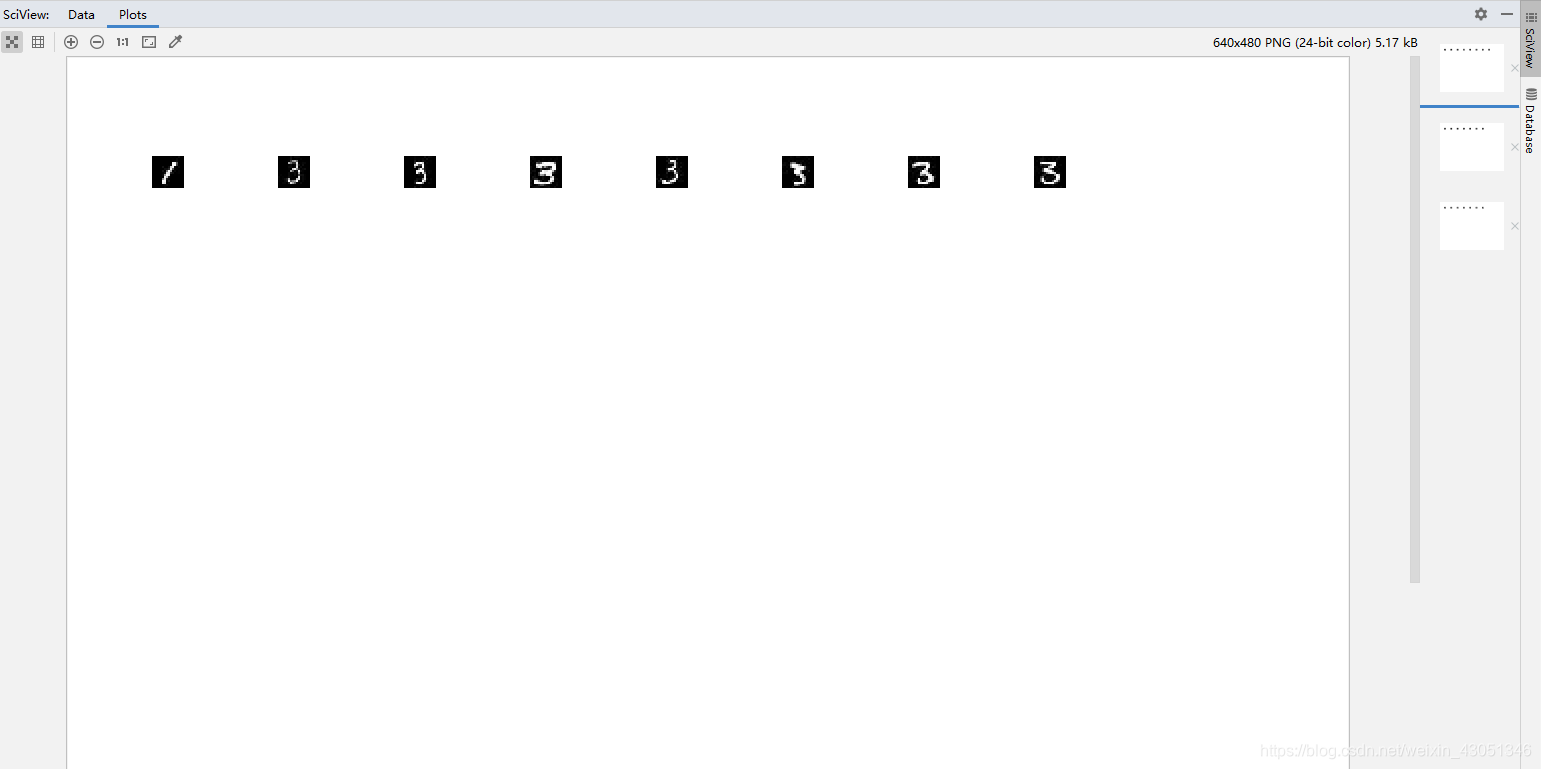
在实现了聚类之后,编写代码实现聚类后图像的分门别类,效果图如下:
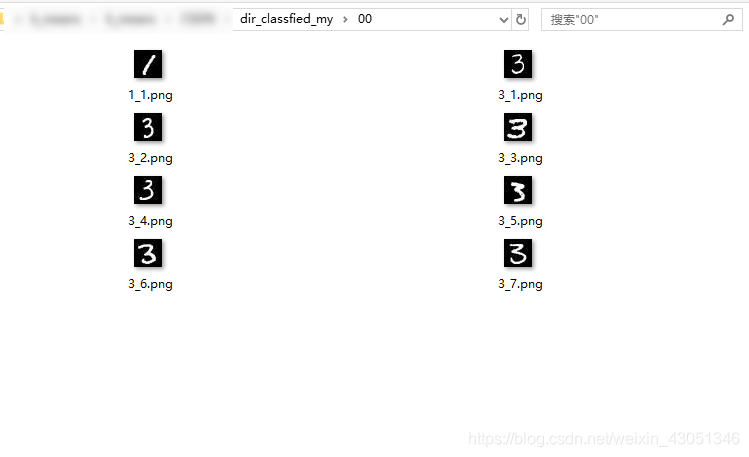
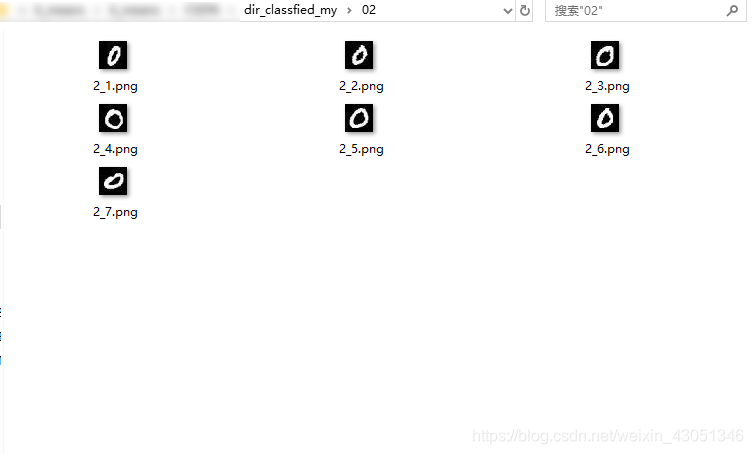
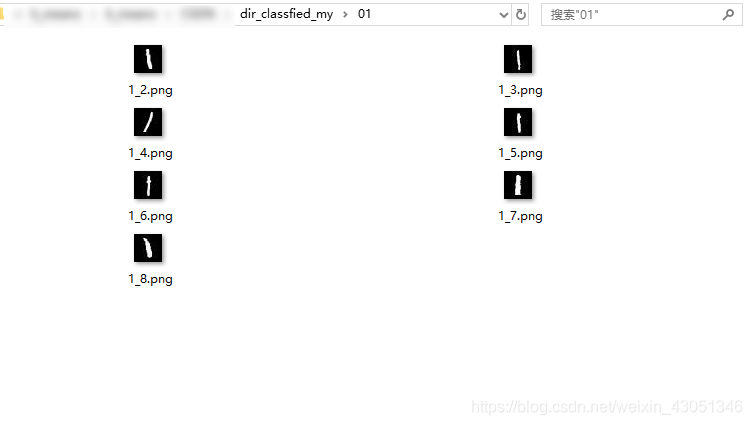
通过观察可以发现,基于无监督的谱聚类进行图像分类还是有一定的效果的,而且通过对比实验发现,待分类的图像数据越多,分类越精确。
聚类后的图像对应还原操作
由于在聚类操作前对数据进行了图像预处理操作,所以如果要保持原来的图像,需要对其进行还原操作,还原的方法有很多种,这里依据图像名来进行,于是乎编写代码如下(对应项目中的returned.py代码文件):
import os
import glob
import shutil
PATH_0 = './dir_my/' # 存放原始图像的文件夹路径
PATH_1 = './dir_classfied_my/' # 存放根据聚类效果来对原始图像重新排布的原始图像文件夹路径
# 1、先遍历图像处理前总文件夹的图像文件
for filename_0 in os.listdir(r"./dir_my"): # listdir的参数是文件夹的路径
# print(filename_0) #此时的filename是文件夹中文件的名称
for filename_1 in os.listdir(r"./dir_classfied_my"):
# print(filename_1) # filename_1: 00 01 02
for filename_2 in os.listdir(r"./dir_classfied_my/%s" % filename_1):
# print(filename_2) # filename_2: '1_2.jpg'
paths = PATH_0 + filename_1 + '/' + filename_2
# print(paths)
if filename_2 == filename_0:
shutil.copy(os.path.join(PATH_0, filename_0), os.path.join(PATH_1, filename_1, filename_0))
这里一心想实现最终效果,所以并没有过多考虑时间复杂度的问题 [手动狗头],代码还有很大的优化空间。
这篇文章写出来,希望能帮助到有需要的人们,同时也是为了日后需要时的查阅方便。文章中项目的代码已开源,点击这里即可查看,如果有帮助到你,请动动你的小手在GitHub上点亮☆ Star。
写到这里,差不多本文就要结束了。如果有问题可以在下方留言区留言交流,错误之处也欢迎小伙伴们的批评指正。如果我的这篇文章帮助到了你,那我也会感到很高兴,一个人能走多远,在于与谁同行。

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









