







本文在Tensorflow之TFRecord读写自己的数据(一)的基础之上,稍作修改
- 函数:def get_file()
# 将所有的list分为两部分,一部分用来训练tra,一部分用来验证val
images = []
labels = []
n_sample = len(image_list)
n_val = int(math.ceil(n_sample * 0.2)) #验证集占整个数据集的20%
n_train = n_sample - n_val
tra_images = image_list[0:n_train]
images.append(tra_images)
tra_labels = label_list[0:n_train]
tra_labels = [int(float(i)) for i in tra_labels]
labels.append(tra_labels)
val_images = image_list[n_train:]
images.append(val_images)
val_labels = label_list[n_train:]
val_labels = [int(float(i)) for i in val_labels]
labels.append(val_labels)
# 返回的是一个嵌套的list
# images 的list 中包含:tra_images,val_images两个list
return images,labels
函数:write_train_tfrecord()
def write_train_tfrecord(train_images,train_labels,save_dir,image_size):
filename = os.path.join(save_dir,'train.tfrecords')
n_samples = len(train_labels)
if np.shape(train_images)[0] != n_samples:
raise ValueError('Image size %d does not match labels size %d.'
%(len(train_images),len(train_labels)))
writer = tf.python_io.TFRecordWriter(filename)
print('Train Date Transforming ... ')
m=n=0
for i in np.arange(0,n_samples):
try:
m += 1
image = Image.open(train_images[i])
image = image.resize(image_size)
image_raw = image.tobytes()
label = int(train_labels[i])
example = tf.train.Example(features=tf.train.Features(feature={
'image_raw':_bytes_feature(image_raw),
'label':_int64_feature(label)
}))
writer.write(example.SerializeToString())
# if m % 100 == 0:
# print('Num of successful:',m)
except IOError as e:
n += 1
print('Could not read:',train_images[i])
print('Error type:',e)
print('Skip it !\n')
writer.close()
print('Transform done !')
print('Transformed : %d\t failed : %d\n' % (m,n))
return filename
函数:def write_verify_tfrecord() 和上面的基本一样
def write_verify_tfrecord(val_images,val_labels,save_dir,image_size):
filename = os.path.join(save_dir,'verify.tfrecords')
n_samples = len(val_labels)
if np.shape(val_images)[0] != n_samples:
raise ValueError('Image size %d does not match labels size %d.'
%(val_images.size(),val_labels.szie()))
writer = tf.python_io.TFRecordWriter(filename)
print('Verify Date Transforming ... ')
m=n=0
for i in np.arange(0,n_samples):
try:
m += 1
image = Image.open(val_images[i])
image = image.resize(image_size)
image_raw = image.tobytes()
label = int(val_labels[i])
example = tf.train.Example(features=tf.train.Features(feature={
'image_raw':_bytes_feature(image_raw),
'label':_int64_feature(label)
}))
writer.write(example.SerializeToString())
# if m % 100 == 0:
# print('Num of successful:',m)
except IOError as e:
n += 1
print('Could not read:',val_images[i])
print('Error type:',e)
print('Skip it !\n')
writer.close()
print('Transform done !')
print('Transformed : %d\t failed : %d\n' % (m,n))
return filename
函数:def convet_to_tfrecord()
def convet_to_tfrecord(images,labels,save_dir,image_size):
filename = os.listdir(save_dir)
for f in filename:
if f.endswith('.tfrecords'):
tf_file = save_dir+'/'+f
signal = input('%s already exists, do you want to recover it? (y/n)\n'% f)
if signal == 'y':
os.remove(tf_file)
else:
return (tf_file)
train_tfrecord = write_train_tfrecord(images[0],labels[0],save_dir,image_size)
verify_tfrecord = write_verify_tfrecord(images[1],labels[1],save_dir,image_size)
return train_tfrecord,verify_tfrecord
测试代码
batch_size = 4
image_size = (224,224)
images,labels = get_file('F:/OpenCV-Python/TFRecord/data',100)
print(len(images[0]))
tra,val= convet_to_tfrecord(images,labels,'F:\PycharmProject\VGG\data',image_size)
print(tra,val)
image_batch,label_batch = read_and_decode(tra,batch_size,image_size)
print(image_batch.shape,label_batch.shape)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess,coord)
if not os.path.exists(savePath):
os.makedirs(savePath)
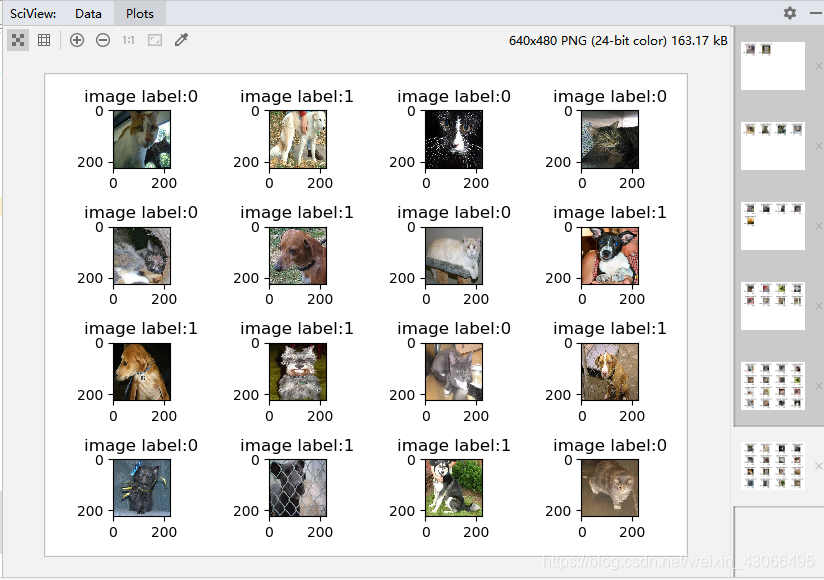
for i in range(4):
image,label = sess.run([image_batch,label_batch])
for j in range(image.shape[0]):
plt.subplot(4,4,4*i+j+1)
plt.imshow(np.array(image[j]))
plt.title('image label:%d'%label[j])
plt.show()
coord.request_stop()
coord.join(threads)
运行结果














 2756
2756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









