






大家好,我是程栩,一个专注于性能的大厂程序员,分享包括但不限于计算机体系结构、性能优化、云原生的知识。
今天我们来聊一聊perf,一个非常重要的Linux性能工具。本文是perf系列的第一篇文章,后续会继续介绍perf,包括用法、原理和相关的经典文章。
perf是什么?
perf是performance的缩写,在perf的文档中,其介绍是一款Linux的性能分析工具(Performance analysis tools)。perf是一个事件驱动的可观测性工具,也是Linux内核的一部分,在内核源码tools/perf目录下即可看到其源码。经过数十年的发展,perf已经逐渐变成了一个功能非常多的工具,可以帮助我们解决性能问题。
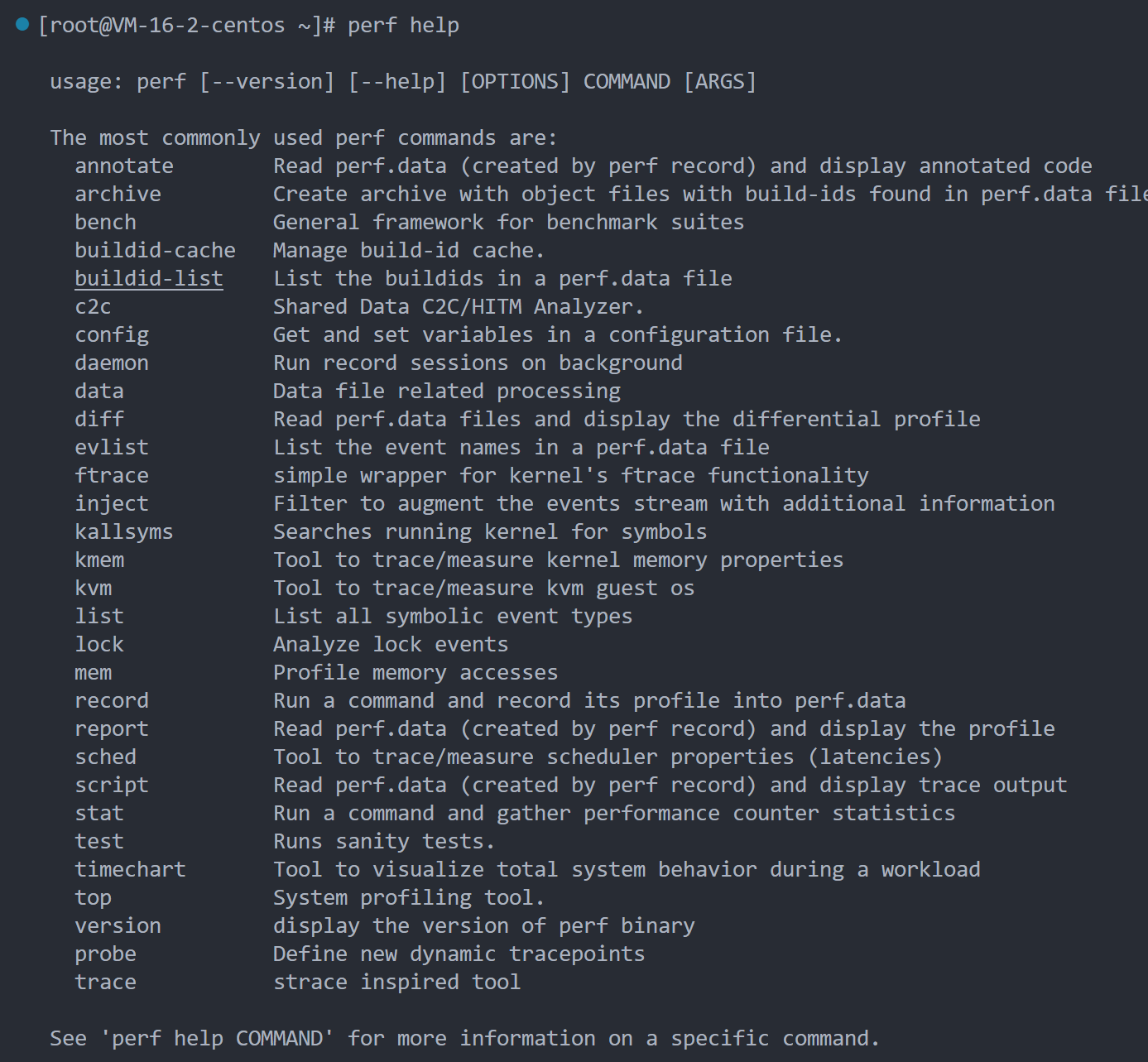
我们执行perf help,可以看到有非常多的选项,这常常给才使用perf的新手造成诸多的困扰,不知道该怎么去使用这些工具:
比如,有如下的一些场景,都可以考虑通过perf来进行性能分析:
- CPU利用率过高;
- CPU cache miss情况过多;
- CPU内存I/O过慢;
- TCP重传过多;
- 是否存在某个函数调用过多;
当然,也有其他非常多的场景,这里只列举了一小部分。
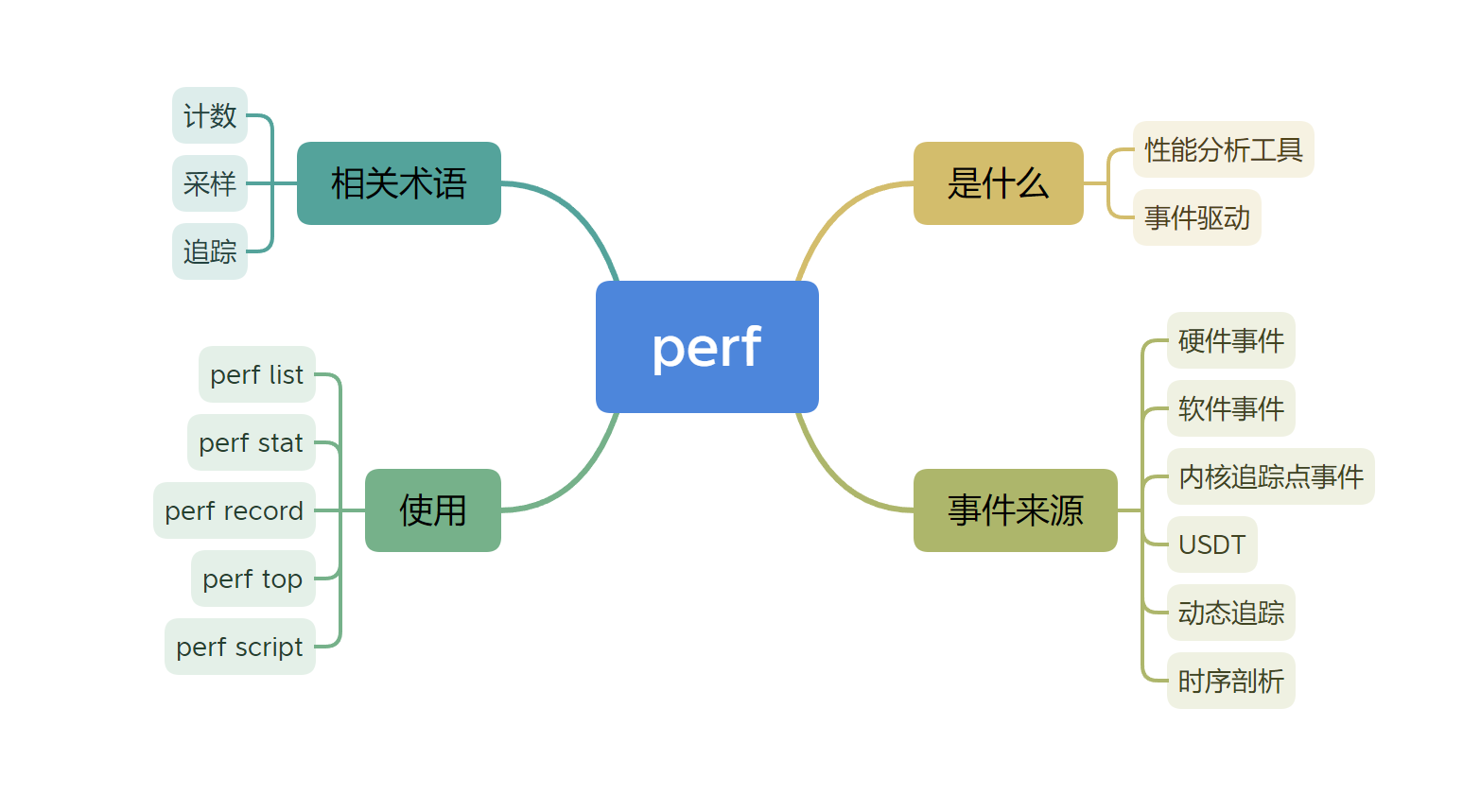
相关术语
在开始之前,我们需要介绍一些术语:
- 计数(statistics/count):表示某个事件发生的次数,比如我们可以通过
perf stat -d command来查看某个命令发生的次数; - 采样剖析(sample):收集一系列调用事件的细节信息,比如某段时间的调用栈情况;
- 追踪(trace):追踪每一个事件的细节,比如追踪上下文切换(
context switch)的相关信息;
事件(events)
前文我们说过,perf是一个事件驱动的性能分析工具,我们就有必要知道perf都有哪些事件。我们可以通过perf list查看支持的事件:
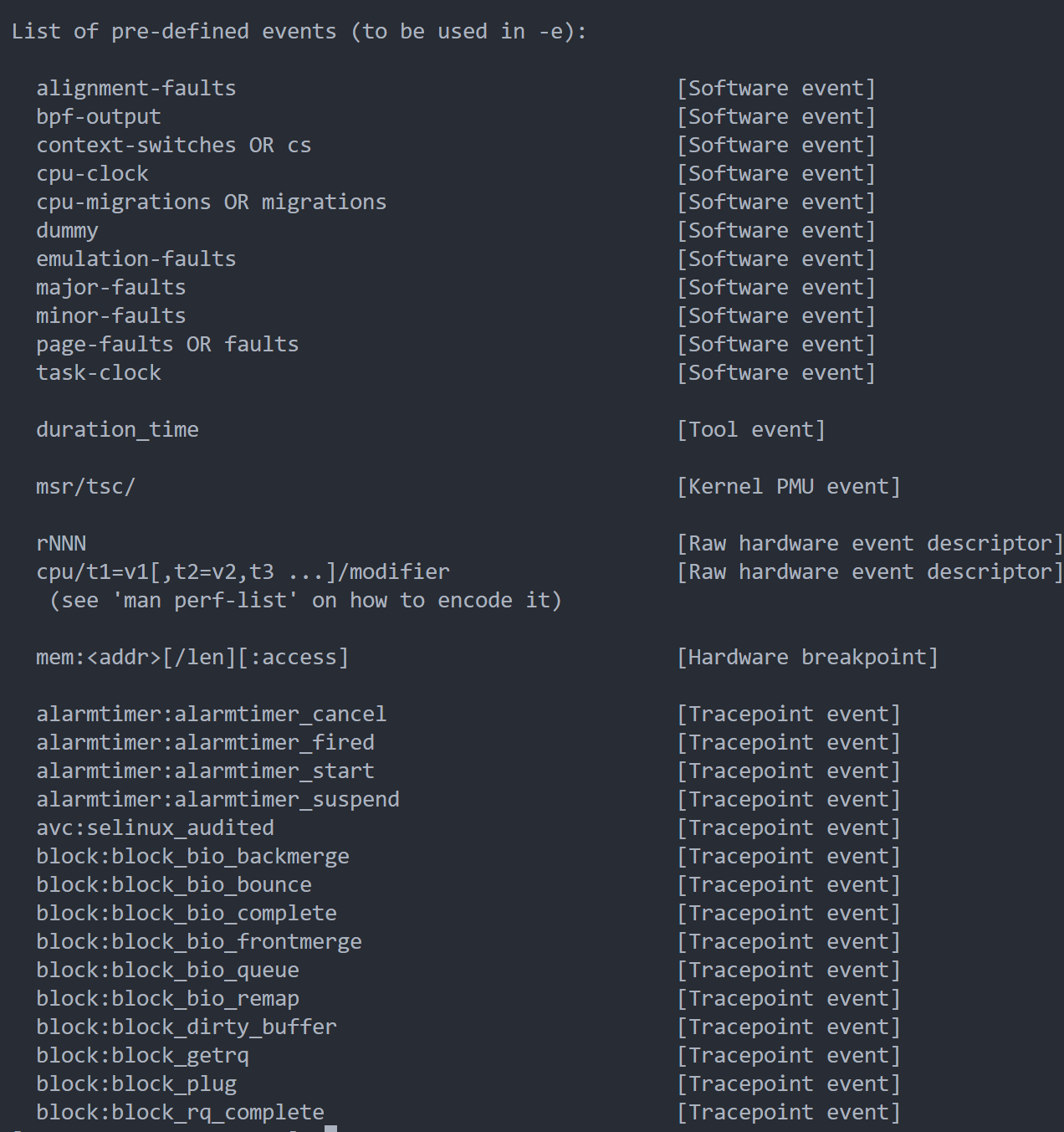
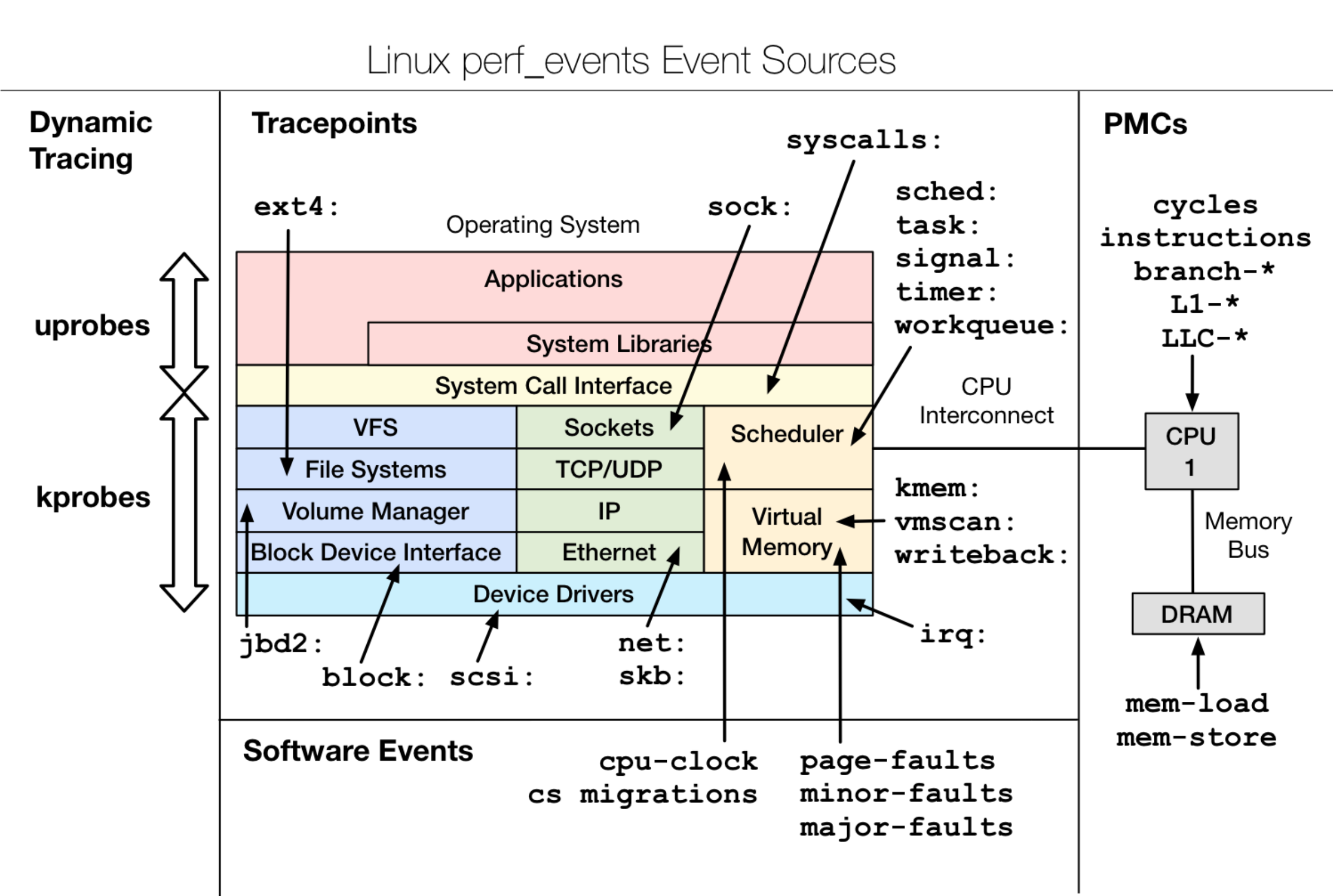
可以看到有非常多的事件,后面都跟着事件的类型。一般来说,事件可以分为六类:
- 硬件事件(Hardware Events):来自于CPU硬件监控计数器(performance monitoring counters);
- 软件事件(Software Events):主要来源于内核计数器;
- 内核追踪点事件(Kernel Tracepoint Events):硬编码在内核中的静态指令点;
- USDT(User Statically-defined Tracing):用户程序和应用的静态追踪点;
- 动态追踪(Dynamic Tracing):软件可以被动态的插桩;
- 时序剖析(Timed Profiling):通过
perf record收集到的按照一定频率的剖析数据;
可以借助Gregg博客中的这张图更好地理解:
例子
作为一个初学者,我们可以借助一些简单的例子来进行学习:
计数(Counting)
我们可以用perf stat来收集一些计数信息,比如我们直接运行perf stat:
[root@VM-16-2-centos ~]# perf stat
^C
Performance counter stats for 'system wide':
6,985.82 msec cpu-clock # 2.000 CPUs utilized
5,787 context-switches # 0.828 K/sec
468 cpu-migrations # 0.067 K/sec
13,423 page-faults # 0.002 M/sec
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
3.492943090 seconds time elapsed
可以看到在这3.49秒钟中,发生了6985次cpu-clock事件,5787次context-switches,468次cpu-migrations和13423次page-faults。在这里cpu-clock是cpu执行的真实时间,比如这里我们并没有指定具体的进程或者命令,我们就可以看到cpu-clock的结果和实际执行时间与CPU核数的乘积是一致的。context-switches就是我们常说的上下文切换,page-faults则是页错误,表示触发了缺页中断,这些都是我们在操作系统中经常见到的名词。cpu-migrations则是CPU的迁移,表示一个进程在CPU上迁移的数量,如果产生了过多的迁移,则可能会导致缓存失效和内存访问延迟。
我们考虑针对具体的命令/进程进行计数,例如:
[root@VM-16-2-centos ~]# perf stat sleep 5
Performance counter stats for 'sleep 5':
0.73 msec task-clock # 0.000 CPUs utilized
1 context-switches # 0.001 M/sec
0 cpu-migrations # 0.000 K/sec
76 page-faults # 0.105 M/sec
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
5.001522424 seconds time elapsed
0.000000000 seconds user
0.001442000 seconds sys
可以看到我们这里对sleep 5这个命令进行了计数,这样的结果也符合我们对sleep命令的理解。
我们也可以对具体的进程进行计数:
[root@VM-16-2-centos ~]# perf stat -p `pgrep -nx dockerd`
^C
Performance counter stats for process id '1188':
0.06 msec task-clock # 0.000 CPUs utilized
4 context-switches # 0.069 M/sec
0 cpu-migrations # 0.000 K/sec
0 page-faults # 0.000 K/sec
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
11.310337191 seconds time elapsed
这里我们使用pgrep -nx来获取进程对应的进程ID。
除了上面看到的这些事件,我们也可以用perf stat来查看更多的事件对应的计数情况:
[root@VM-16-2-centos ~]# perf stat -e alignment-faults
^C
Performance counter stats for 'system wide':
0 alignment-faults
17.330959348 seconds time elapsed
alignment-faults是指内存对齐错误发生的次数。 这里的事件应该是系统支持的事件,我们可以通过前文提到的perf list来查看。
综上,我们可以对命令、进程、事件进行计数,当然也可以合到一起,对某个进程的某个事件进行计数,这就是perf强大的地方,可以让我们从不同维度和不同角度来进行性能分析。
如果想了解更多关于perf stat的内容,可以通过perf stat --help进行查看。
采样
采样和计数是perf最常用的两个功能,我们可以用perf record或者perf top进行对系统的剖析,不妨先用perf top来一个直观的认识,看看和perf stat有什么不同:
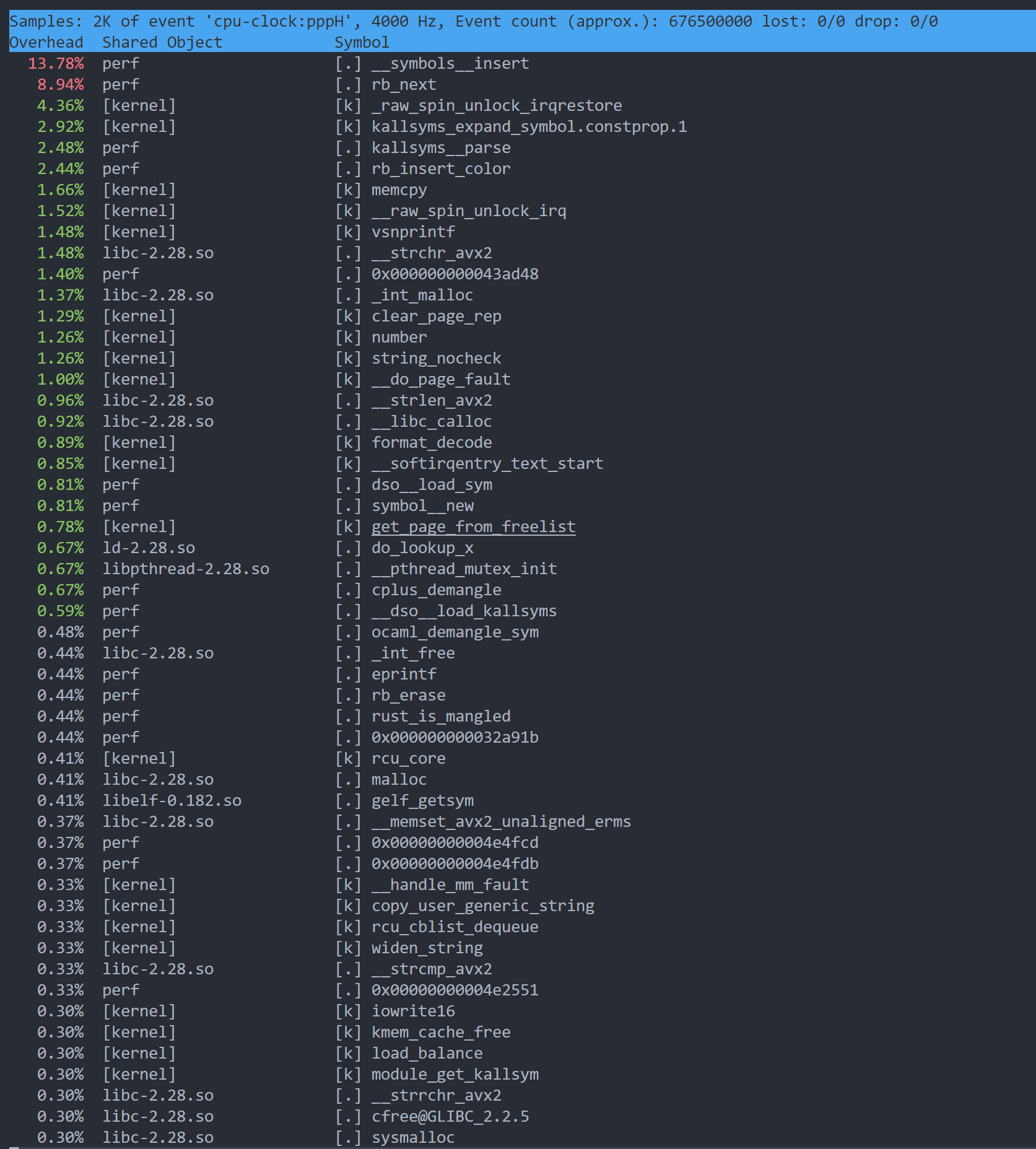
执行perf top,我们就可以看到目前的CPU执行占比情况,该情况会随着时间刷新,这可以帮助我们快速的发现热点。
perf record则像是把多个时间的perf top结果作为切片保存到一个文件里,让我们可以得到一段时间里的执行情况:
# 采样20秒
[root@VM-16-2-centos ~]# perf record -a -g -F 999 -- sleep 20
[ perf record: Woken up 20 times to write data ]
[ perf record: Captured and wrote 5.166 MB perf.data (38313 samples) ]
这里得到的结果数据是无法直接读取的,我们可以用perf script将其转换成可读文件,或者直接用perf report进行图形化展示:
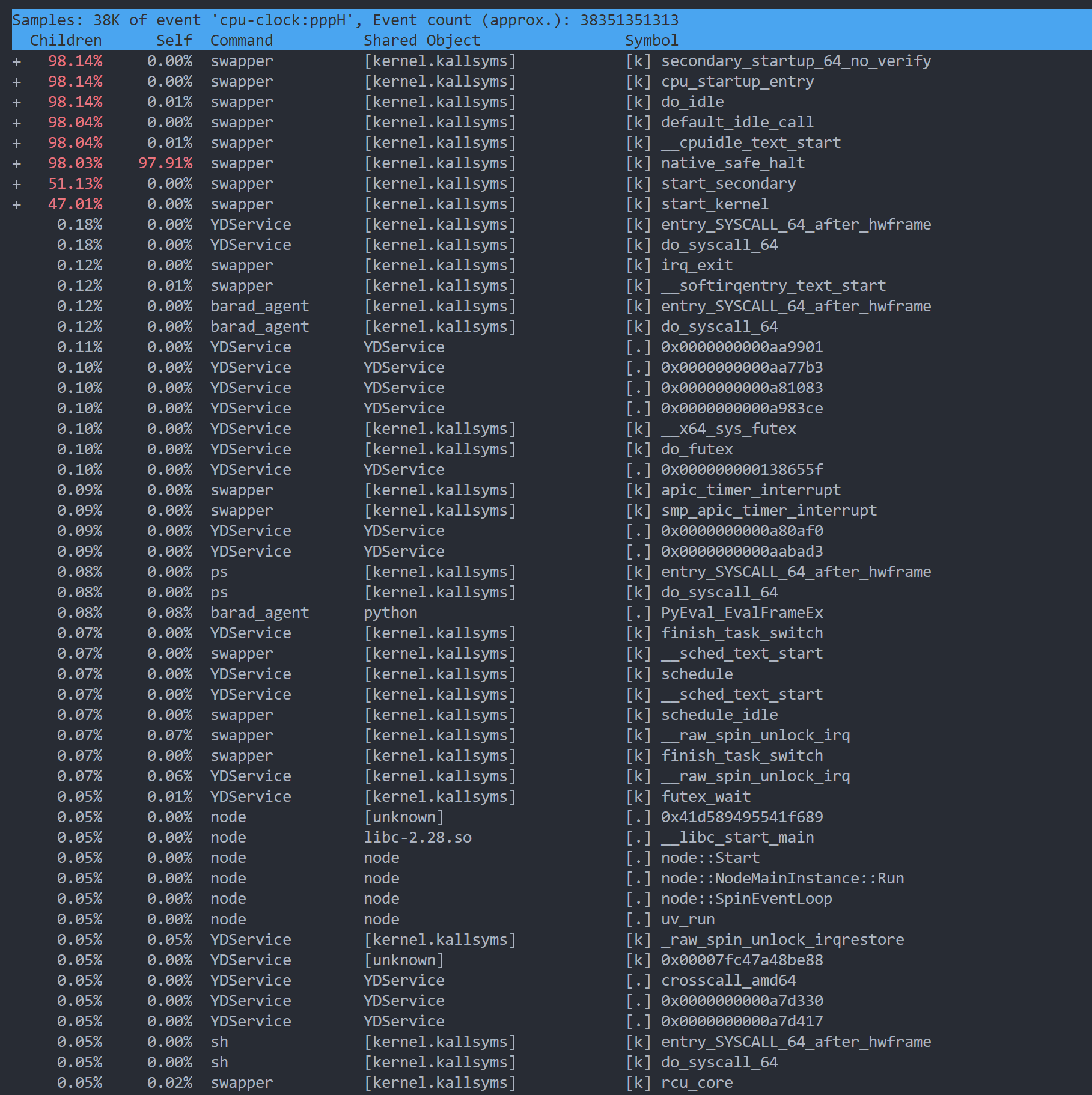
将数据通过perf script解析:
[root@VM-16-2-centos ~]# perf script
swapper 0 [001] 12717072.274705: 1001001 cpu-clock:pppH:
ffffffff8857fece native_safe_halt+0xe ([kernel.kallsyms])
ffffffff8857fd8a __cpuidle_text_start+0xa ([kernel.kallsyms])
ffffffff88580020 default_idle_call+0x40 ([kernel.kallsyms])
ffffffff87d22a44 do_idle+0x1f4 ([kernel.kallsyms])
ffffffff87d22c7f cpu_startup_entry+0x6f ([kernel.kallsyms])
ffffffff87c5929b start_secondary+0x19b ([kernel.kallsyms])
ffffffff87c00107 secondary_startup_64_no_verify+0xc2 ([kernel.kallsyms])
我们可以看到诸多类似这样格式的数据,该数据的第一行告诉我们进程的名字、进程pid、执行的CPU等信息,下面就是其调用栈。基于这个数据,我们可以生成火焰图,这个我们会在后续的文章里讲述。
小结
今天的介绍就到这里,我们今天主要介绍了如下的内容:















 131
131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









