






torchvision.dataset 内置分类数据集的简要介绍
- Caltech 101
- Caltech 256
- Large-scale CelebFaces Attributes (CelebA) Dataset
- CIFAR10
- CIFAR100
- Country211
- Describable Textures Dataset (DTD) 纹理识别数据集
- MNIST
- EMNIST
- QMNIST
- FashionMNIST
- EuroSAT Dataset
- FakeData
- FER2013
- FGVC Aircraft Dataset
- Flickr8k Entities Dataset
- Flickr30k Entities Dataset
- Oxford 102 Flower Dataset
- The Food-101 DataSet
- German Traffic Sign Recognition Benchmark (GTSRB) Dataset 德国交通标志检测数据集
- iNaturalist Dataset
- ImageNet 2012 Classification Dataset
- Kuzushiji-MNIST Dataset
- LFW Dataset
- LSUN dataset
- Omniglot
- Oxford-IIIT Pet Dataset
- Places365 classification dataset
- PCAM Dataset
- The Rendered SST2 Dataset
- SEMEION Dataset
- SBU Captioned Photo Dataset
- Stanford Cars Dataset
- STL10 Dataset
- The SUN397 DataSet
- SVHN Dataset
torchvision.dataset提供了一些常用的数据集,本篇简要介绍其中的分类数据集和调用方法(见DTD)。
Caltech 101
有101+1(背景)个类别,包括面孔,手表,蚂蚁,钢琴等等。每个类别有40-800张图片(存在类别不均衡问题),图片尺寸在200-300pixel之间。

Caltech 256
256+1个类别,每个类别的图片至少80张,总图片数量30000+。三通道均值和标准差如下:
# 三通道均值和标准差如下
0.5520 0.5336 0.5050
0.2353 0.2345 0.2372
Large-scale CelebFaces Attributes (CelebA) Dataset
CelebA 数据集包含10177个名人的202599张图片,每个图像有40个标注属性。

CIFAR10
包含10个类别的RGB 图像:飞机、汽车、鸟类、猫、鹿、狗、蛙类、马、船和卡车。每个类别6000张图像,一共60000张,其中50000张属于训练集,10000张属于测试集。图像尺寸32×32 。

CIFAR100
有100个类别,每个类有600张大小为32×32的RGB图像,其中500张作为训练集,100张作为测试集。每一张图像都有fine_labels和coarse_labels两个标签,分别代表图像的细粒度和粗粒度标签。
Country211
Country211数据集YFCC100m的子集。
# 下载地址
wget https://openaipublic.azureedge.net/clip/data/country211.tgz
tar zxvf country211.tgz
Describable Textures Dataset (DTD) 纹理识别数据集
DTD由5640幅图像组成,包含47个类别,每个类别有120张图片,图像大小在300x300到640x640之间,图像包含至少90%的表面表示类别属性。

from torchvision.dataset import DTD
import torchvision.transform as transform
from torch.utils.data import DataLoader
train_dataset = DTD(root='/pretrain/DTD', split='train', download=True, transform=transform.Compose([transform.ToTensor(), transform.Resize([512,512])]))
val_dataset = DTD(root='/pretrain/DTD', split='val', download=True, transform=transform.Compose([transform.ToTensor(), transform.Resize([512,512])]))
train_loader = DataLoader(train_dataset, batch_size=bs, num_workers=2)
val_dataloader = DataLoader(val_dataset, batch_size=bs, num_workers=2)
MNIST
手写数字分类数据集,包含训练集图像60000张,测试集图像10000张,尺寸28×28,单通道灰度图像(像素值为0或255的黑白图像)。每个标签是长度为10的一维数组,代表其为0-9数字的概率。

EMNIST
Extended MNIST(MNIST数据集的扩展版),图像尺寸28x28,数据量是 MNIST的4倍。

QMNIST
FashionMNIST
Fashion-MNIST数据集涵盖了来自 10 种类别的共 7 万个不同商品的正面灰度图片(通道数为1),图像尺寸28x28。
10种类别分别为:t-shirt(T恤),trouser(牛仔裤),pullover(套衫),dress(裙子),coat(外套),sandal(凉鞋),shirt(衬衫),sneaker(运动鞋),bag(包),ankle boot(短靴)。

EuroSAT Dataset
数据集基于Sentinel-2卫星拍摄的图像收集而成,覆盖13个光谱带,由10个分类组成,每类包含2000~3000张图片,总共27000张带标签和地理参考的土地使用图像,图像尺寸64x64。
10个类别分别为:Industrial Buildings 工业建筑、Residential Buildings 居民楼、Annual Crop 庄稼作物、Permanent Crop 永久性作物、River 河、Sea & Lake 海洋湖泊、Herbaceous Vegetation 草本植被、Highway 高速公路、Pasture 牧场、Forest 森林。

FakeData
FER2013
Fer2013人脸表情数据集由35886张人脸表情灰度图片(通道数1)组成,其中训练集28708张图片,测试集和验证集各3589张,每张图片大小固定为48×48。
共有7种表情,分别对应于数字标签0-6:0 anger 生气; 1 disgust 厌恶; 2 fear 恐惧; 3 happy 开心; 4 sad 伤心;5 surprised 惊讶; 6 normal 中性。

FGVC Aircraft Dataset
FGVC-Aircraft包含10200张飞机图像,其中有100 种不同的飞机型号,每个型号都有102张图像,数据集等分为训练、验证、测试数据集。
飞机标签按四个级别的层次结构进行组织:Model-Varient-Family-Manufacturer,Varient有102个类别,Family有70个类别,Manufacturer有41个类别。

Flickr8k Entities Dataset
Flickr30k Entities Dataset
Oxford 102 Flower Dataset
数据集包含102 种花类,每个类别包含40-258张图像,总共8189张图片。图像尺寸不等,在500-700pixel之间。
这些图像在比例、姿势以及光照方面有着丰富的变化。

The Food-101 DataSet
包含101 种食品类别的图像数据集,共有101000张图像,平均每个类别拥有 250 张测试图像和 750 张训练图像,尺寸统一为512×512。

German Traffic Sign Recognition Benchmark (GTSRB) Dataset 德国交通标志检测数据集
包括43个类别的交通标志,超过50000张图像,其中训练集39209张,测试集12630张。

iNaturalist Dataset
iNaturalist系列数据集是美国加州理工、康奈尔大学和Google等机构联合构建的,以植物、鸟类、昆虫和菌类等13个自然生物大类下属的上千种物种细分类类别组成的细粒度级别图像数据集(fine-grained dataset),图像量多达近百万张。
以iNaturalist 2017为例,该数据集包含5089个细粒度的675170张图片,粗分为13个种类(植物、鸟类、昆虫和菌类等),数据集存在严重类别不均衡为题。
ImageNet 2012 Classification Dataset
Kuzushiji-MNIST Dataset
LFW Dataset
LSUN dataset
Omniglot
Oxford-IIIT Pet Dataset
Places365 classification dataset
PCAM Dataset
The Rendered SST2 Dataset
SEMEION Dataset
SBU Captioned Photo Dataset
Stanford Cars Dataset
该数据集包含196 种汽车类别的16185张图像,训练集8144 张,测试集8041张。

STL10 Dataset
The SUN397 DataSet
SVHN Dataset
街景字符串数据集,训练、测试、额外(难度稍低)数据集分别包含33402、13068、202353张标记图片。
该数据集包含两种格式:
Format1图片尺寸不统一且差异较大;Format2将图像裁剪为32×32的小图像。
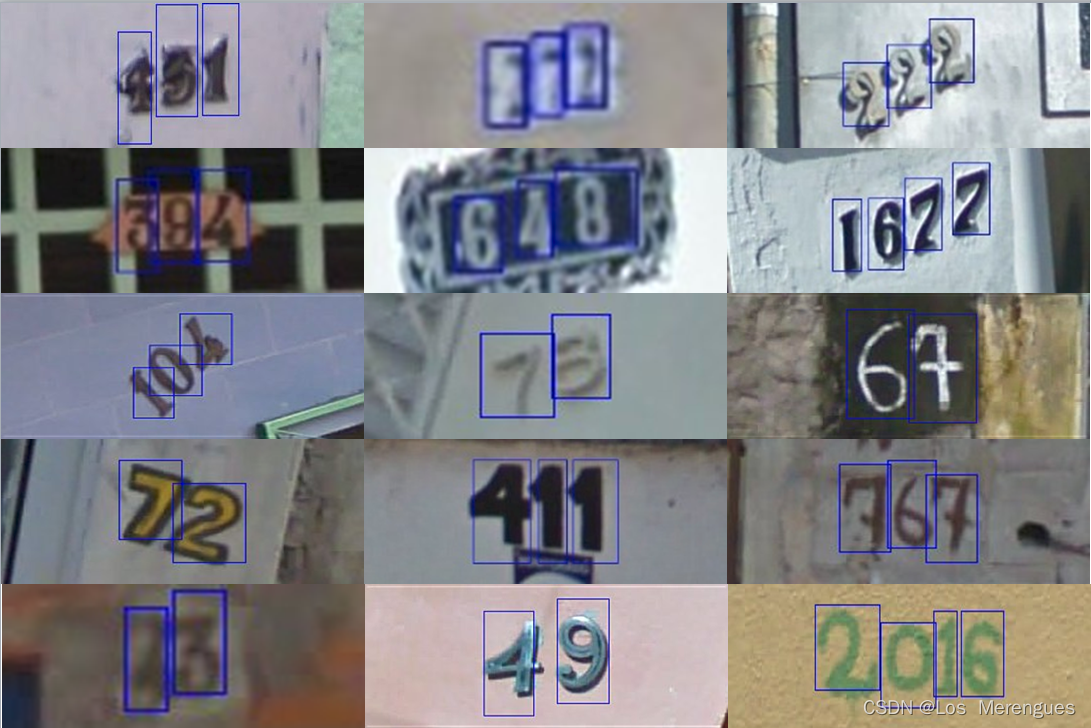


















 3440
3440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









