







算法(三·四):分治思想——快速排序
算法介绍
快速排序是基于分治策略的一个经典算法。通过选择一个元素作为基准(也称“主元”)(pivot),将待排序的数组分成两个子数组,一个包含所有小于基准的元素,另一个包含所有大于基准的元素,然后递归地对这两个子数组进行快速排序,从而达到整个数组的排序。由于其高效性,快速排序被广泛认为是实际应用中最快的通用排序算法。其与归并排序在分治思想上的不同点在于,归并排序是“简化分解,侧重合并”,而快速排序是“侧重分解,简化合并”。
算法步骤
- 分(Divide):
- 选择基准值(也称“主元”) (Pivot): 在待排序的数组或子数组中选择一个元素作为基准值(也称“主元”)。可以选择第一个元素、最后一个元素、中间元素或使用其他选择策略,如随机选择或“三数中值”法。
- 划分 (Partition): 通过与基准值(也称“主元”)的比较,重新排列数组使得:基准值左边的所有元素都不大于它;基准值(也称“主元”)右边的所有元素都不小于它。
- 经过这一步骤后,基准值(也称“主元”)将被放在其最终排序位置。
- 治(Conquer):分别对基准值(也称“主元”)左、右两边的子数组递归地应用快速排序。
- 合(Merge):对于快速排序,这一步实际上是不必要的。这是因为在“分”阶段中,数组或子数组已经被原地调整到了部分排序的状态。所以在治的步骤完成后,整个数组或子数组已经完全排序。换言之合的过程较为简单,只是将左右两个有序子数组合并上即可。
- 返回结果:返回合并结果,即为快速排序最终结果。
- 特殊说明:快速排序的关键点在于“分的过程”,因此在执行“分”的算法过程时,选择不同的基准值(这也是我在上述介绍基准值时,将其颜色加深的原因),会为整个算法带来不同的效率。具体情况后续会说明。
算法图示
分治
- 基本思想
-
选择基准值:任选元素𝒙作为分界线,称为主元(pivot)

-
划分:交换重排,满足𝒙左侧元素小于右侧

-
- 实现方法一:选取固定位置为主元
- 选择基准值:选取固定位置主元𝒙(如尾元素)

- 划分:
- 维护两个部分的右端点变量𝒊,𝒋,图中为𝒊,𝒋的初始位置。

- 考察数组元素𝑨[𝒋] ,只和主元比较。
①若𝑨[𝒋] ≤ 𝒙,则交换𝑨[𝒋]和𝑨[𝒊 + 𝟏],𝒊,𝒋右移。
②若𝑨[𝒋] > 𝒙,则𝒋右移。









······以此类推

- 把主元放在中间作分界线。



- 维护两个部分的右端点变量𝒊,𝒋,图中为𝒊,𝒋的初始位置。
- 递归实现分

- 选择基准值:选取固定位置主元𝒙(如尾元素)
合

实现方法一:选取固定位置为主元
伪代码
ALGORITHM QuickSort(A, low, high)
// 如果剩下的数组有两个或更多元素
IF low < high THEN
// 分区操作 - pivot是分区后基准元素的索引位置
pivot = Partition(A, low, high)
// 递归地对基准左侧元素排序
QuickSort(A, low, pivot - 1)
// 递归地对基准右侧元素排序
QuickSort(A, pivot + 1, high)
END IF
END ALGORITHM
ALGORITHM Partition(A, low, high)
// 选择一个基准元素,这里我们选择最后一个元素
pivot = A[high]
// i 是跟踪小于基准的元素的“边界”
i = low - 1
// 通过检查所有元素并与基准比较来进行分区
FOR j = low TO high - 1 DO
IF A[j] <= pivot THEN
i = i + 1
// 交换 A[i] 和 A[j]
SWAP(A[i], A[j])
END IF
END FOR
// 把基准元素放到正确的位置
SWAP(A[i + 1], A[high])
// 返回基准的索引位置
RETURN i + 1
END ALGORITHM
算法时间复杂度分析
- 最好情况:数组划分后,每次主元都在中间。
- 时间复杂度:𝑻(𝒏) = 𝟐𝑻(𝒏/𝟐) + 𝑶(𝒏) = 𝑶(𝒏𝐥𝐨𝐠𝒏)
- 图示



- 最坏情况:数组划分后,每次主元都在一侧。
-
时间复杂度

-
图示
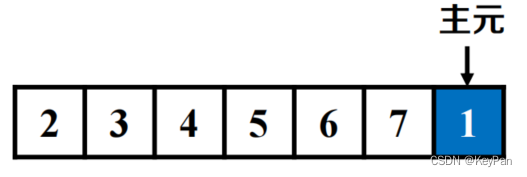



-
- 总结:不同的输入导致此种实现方式不同的算法效率,我们如何摆脱输入导致最坏情况的困境?因为最差的情况是数组划分时选取固定位置主元,因此可以针对性构造最差情况。所以我们可以在数组划分时选取随机位置主元,这样无法针对性构造最差情况。这也是第二种实现方法:随机化快速排序。
实现方法二:随机化快速排序
算法图示






伪代码
ALGORITHM RandomizedQuickSort(A, low, high)
IF low < high THEN
// 随机分区并获取基准的索引
pivot = RandomizedPartition(A, low, high)
// 递归地对基准左侧元素排序
RandomizedQuickSort(A, low, pivot - 1)
// 递归地对基准右侧元素排序
RandomizedQuickSort(A, pivot + 1, high)
END IF
END ALGORITHM
ALGORITHM RandomizedPartition(A, low, high)
// 随机选择一个索引在 [low, high] 范围内
randomIndex = RANDOM(low, high)
// 交换随机选择的元素和最后一个元素
SWAP(A[randomIndex], A[high])
// 使用标准的分区方法进行分区
RETURN Partition(A, low, high)
END ALGORITHM
ALGORITHM Partition(A, low, high)
pivot = A[high]
i = low - 1
FOR j = low TO high - 1 DO
IF A[j] <= pivot THEN
i = i + 1
SWAP(A[i], A[j])
END IF
END FOR
SWAP(A[i + 1], A[high])
RETURN i + 1
END ALGORITHM
算法时间复杂度分析
随机抽取主元之后的时间复杂度是 𝑶(𝒏𝐥𝐨𝐠𝒏)
算法总结
快速排序被广泛认为是实际应用中最快的通用排序算法,并且在很多编程开源包里关于排序功能的实现都选择快速排序。尽管在最坏情况下,它的时间复杂度过高。但通过合适的策略选择基准值,如随机选择或使用“三数中值”法,可以显著地减少这种情况的发生。
排序算法的比较

给读者一个问题,能突破吗?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









