









1.语言模型(Language Modeling)
1.1 传统语言模型
定义:基于n-grams的概率模型,通过条件概率链式法则不断找出概率最高的单词,以生成句子
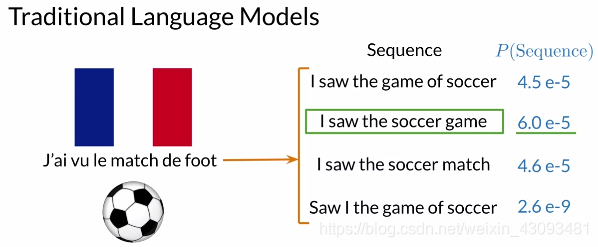
原理:n-grams
缺点:
(1)对于长距离依赖关系,需要大量的n-gram来捕捉语义信息
(2)需要大量存储空间

1.2 基于RNN的语言模型
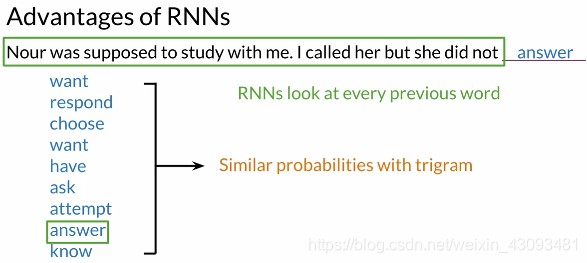
RNN优点:
(1)解决长距离依赖问题,能考虑之前全部单词
(2)共享参数,减少内存使用
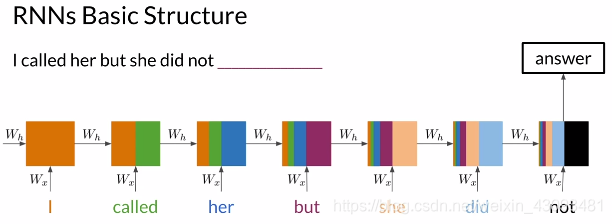
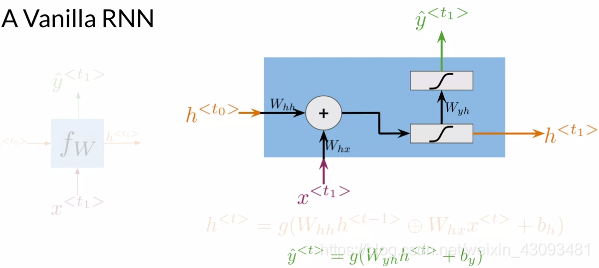
RNN基本结构:
2.循环神经网络(RNN)
2.1 基本原理
构成:
输入:上一层结果 和 当前输入
参数:所有结点共用三组参数、
、
,和偏置
输出:当前层显式输出;当前层隐式输出
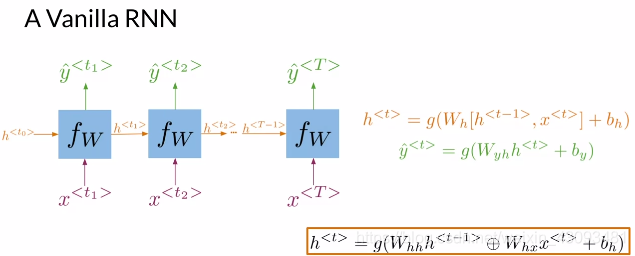
计算流程:
(1)首先将输入与入
分别乘相应的参数
和
,再经过激活函数g(),得到当前层隐式输出
,如下式:
![]()
(2)得到的再成参数
,经过激活函数g(),得到当前层显式输出
,如下式:
损失函数:
交叉熵损失函数:比较各层显式输出和真实结果的差异,再进行平均
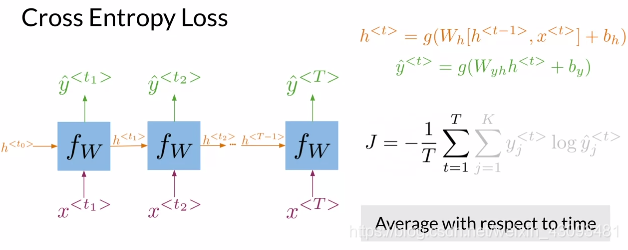
2.2 RNN的应用
一对一(One to One):
输入一个数据,输出一个结果;如冠军预测,输入比分,输出冠军人选

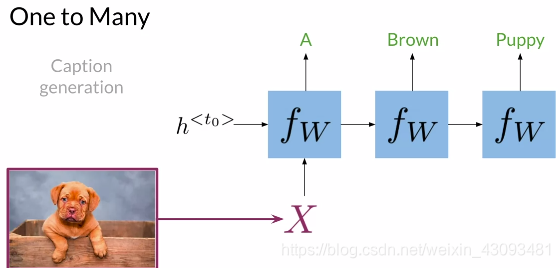
一对多(One to Many):
输入一个数据,输出多组结果;如图片注解,输入一个图片,输出其文字描述
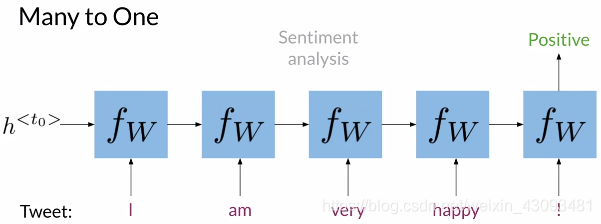
多对一(Many to One):
输入多组数据,输出一个结果;如情感分析,输入一段话,输出其情感
多对多(Many to Many):
输入多组数据,输出多组结果;如机器翻译,输入一段话,输出翻译后的一段话

2.3 常见RNN结构
2.3.1 门控循环单元(Gated Recurrent Units,GRU)
基本概念:
定义:每一单元内含两种门,即重置门(reset gate)和更新门(update gate),分别控制记忆和更新
重置门:计算有多少过去信息需要被遗忘,有助于保存重要内容,遗忘不重要内容
更新门:计算有多少信息需要被传递到下一步,决定如何更新隐式输出
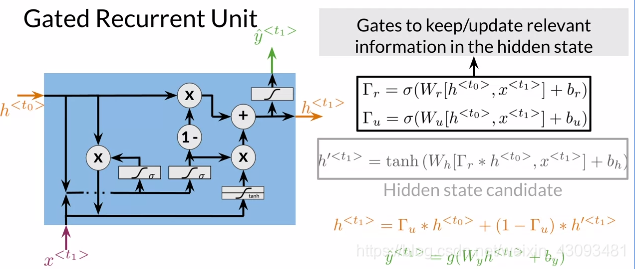
比较:RNN vs GRUs
GRU有更强的记忆力,能有效避免梯度消失问题
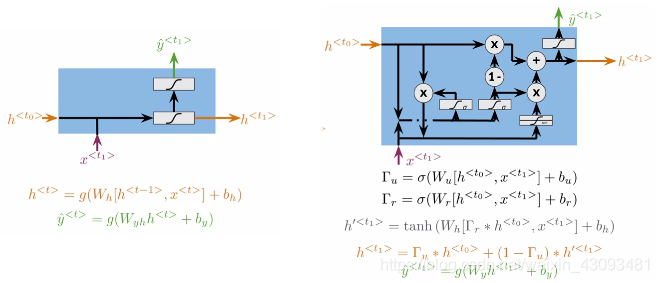
例子:可以看出,GRU能很好解决长距离依赖问题,记住了之前词是复数形式

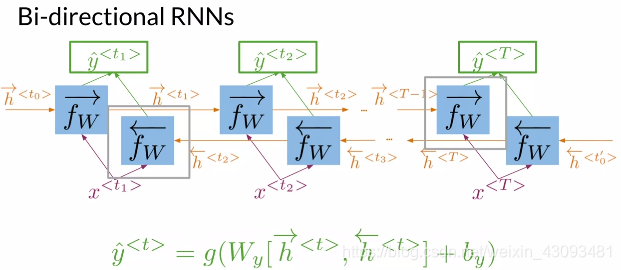
2.3.2 双向RNN(Bi-directional RNNs)
定义:从正反两个方向分别计算,各位置输出由两方向结果共同决定
功能:解决了普通RNN只考虑前向依赖,不考虑后向依赖的问题
注意:两个方向同时独立进行计算,相互之间没有顺序关系
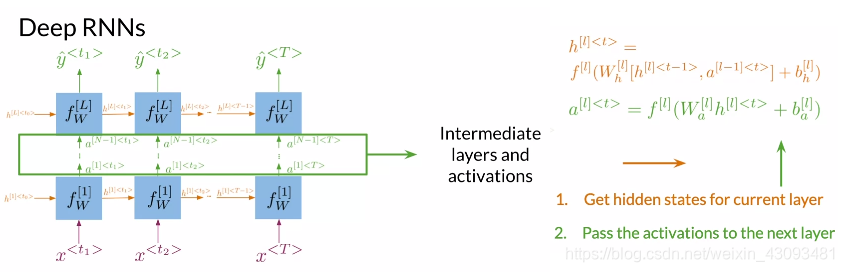
2.3.3 深度RNN(Deep RNNS)
定义:将多个RNN垂直堆叠,从下至上依次计算
功能:由于深度的加深,能更有效的处理复杂问题
项目代码:https://github.com/Ogmx/Natural-Language-Processing-Specialization
可将代码与数据下载至本地,使用jupyter notebook打开


















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











