







目录
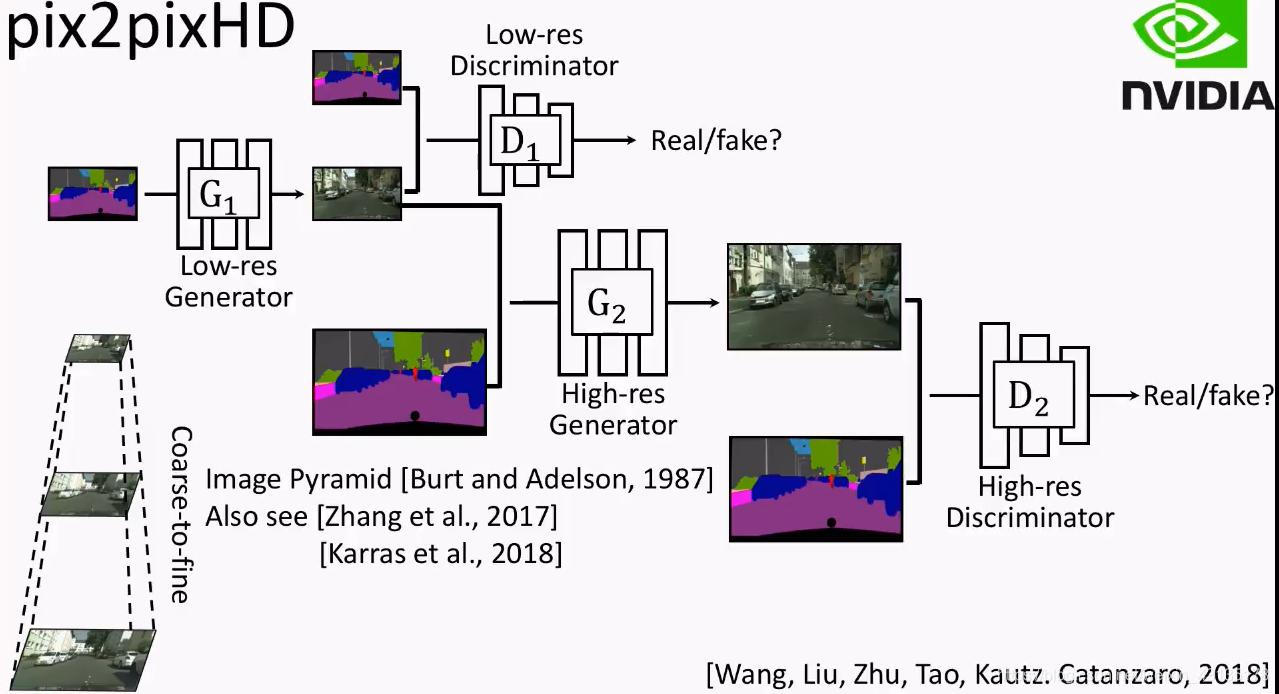
pix2pixHD took Pyramid Methods:
- First output low-resolution pictures.
- Use the previously output low-resolution picture as input to another network, and then generate a higher-resolution picture.
图一
pix2pixHD
如果用图形学的方法渲染真实场景的图像,需要对每个部分建模,非常昂贵、耗时。若能从数据中学习一个模型,即可将此过程转化为模型学习和推断,渲染新的场景只需要重新在数据集上训练;用户也可通过语义自定义,无需重新对几何形状、材质、光线建模。
pix2pix存在两个问题:1.用GAN很难生成高分辨率的图 2.高分辨率图中会损失细节
为支持交互语义操作,作者试图在两个方向上扩展模型:1.使用实例级别的目标分割信息,将相同类别的不同物体分为不同实例 2.为同一输入生成多种输出,方便改变物体的外观
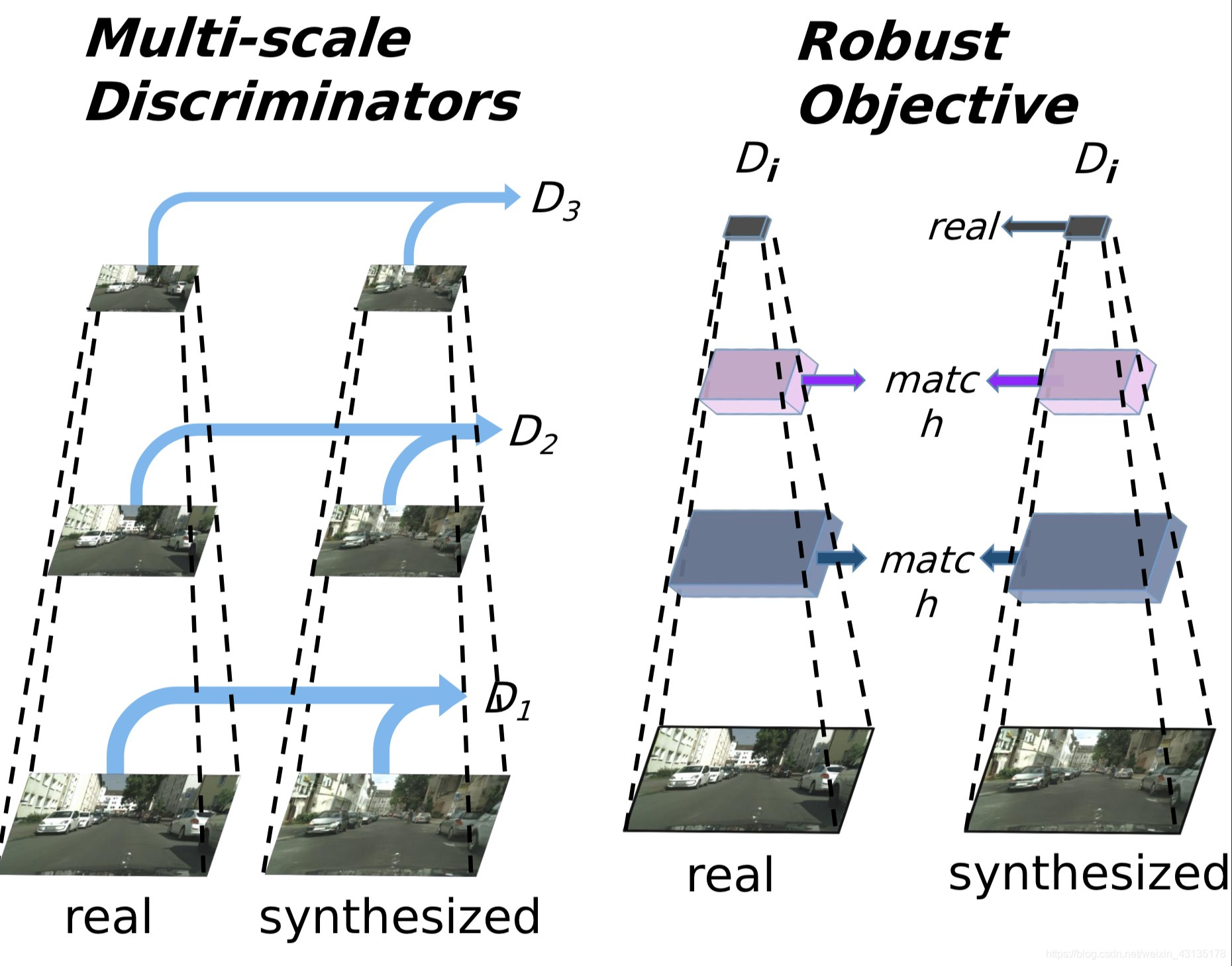
此外,作者提出了新的损失函数和新的多尺度G和D,不仅可以使用条件GAN训练高分辨率的图像的过程稳定下来,也可以得到更好的结果。
提高真实性和分辨率
具体来说,作者对结构做出了以下三个部分的改动:
1.不断进行提纯的G(Coarse-to-fine generator)
2.多尺度D(Multi-scale discriminators)
3.对抗学习目标函数
Generator
将G分为两个子模块:全局和局部增强
,全局
操作1024x512大小的图像,局部增强
输出与其接受的输入相比,在宽和高上各扩大两倍的图像。要合成更高分辨率的图像,再往上加局部增强
模块即可


训练时,先在低分辨率图像上训练残差网络,再和另一个残差网络
在高分辨率图像上一起fine-tune。
Discriminator
为生成高分辨率的真假图像,D必须有大的感知野。因此须有更深的网络或更大的感知野。但这两个选项都可能会造成过拟合,且需要大量内存。
作者就此提出多尺度D,使用三个有相同网络结构但对不同大小图像进行操作的D,对真假高分辨率图像进行2或4的下采样。对最粗糙的图像(分辨率最小的)进行操作的D有最大的感知野,对图像有更全局的认识,指导G产生全局上一致的图像对最细致的图像(分辨率最大的)进行操作的D专门指导G生成细节。
这让训练提纯G更容易,因为将低分辨率的模型扩大到高分辨率只需要在增加一个额外的D,而无需从头开始训练。若没有多尺度D,生成图中会出现很多重复的图案。
损失函数
D是多尺度的,因此修改GAN的loss部分为一个多任务问题:
在上述loss基础上,因为模型结构中存在多尺度,所以增加一个特征匹配loss,用于稳定GAN的训练。从D的多个层中提取特征,学习匹配真实图像和合成图像的中间表示:
其中,k表示第k个D网络,i表示D网络中的第i层。s表示待转换图片,x表示转换目标图片,G(s)表示G网络生成的目标图片。


最后的总loss如上式所示。
下面是对于从语义标签图生成逼真图像的两个优化
改进输入
现有的图像合成方法只利用语义标签图(semantic label map):每个像素值代表其归属的目标的类别的图,但无法区分同一类别的不同物体。而实例级的语义标签图通过赋予每个目标唯一的ID弥补这个不足。
如何实现呢?一般来说有三种方法:
- 直接传入网络
- 使用one-hot向量
- 为每个类预先分配固定数量的特征映射
但以上方法都有较明显的缺点,实施起来较为困难。作者分析,实例图提供的最重要的信息是物体的边界。为了提取该信息,首先计算出实例边界图(Instance boundary map,若某个像素的ID与周围四个像素中的任意一个不同则为1,否则为0)。
将实例边界图与用one-hot向量表示的语义标签图拼接作为G的输入。
D的输入是实例边界图,语义标签图,真/假图像在通道上的拼接。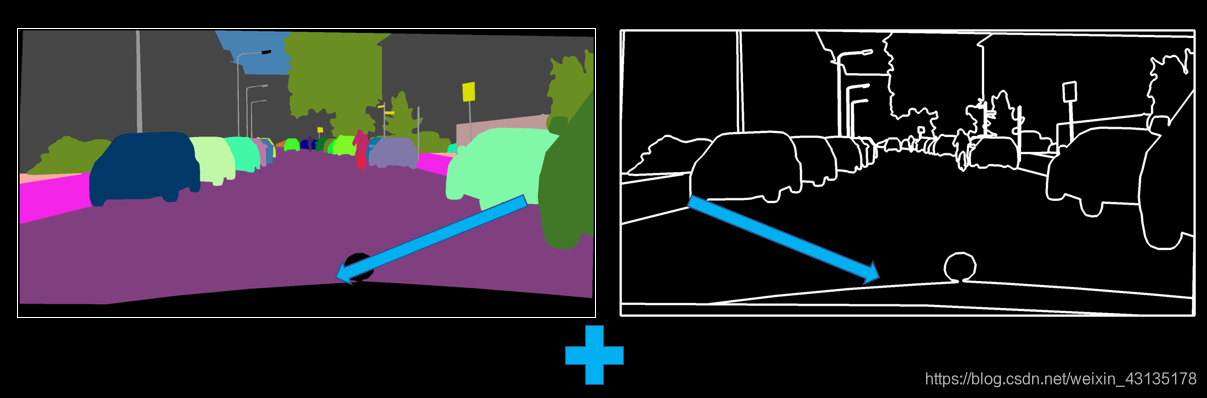
the instance map can be seen as the label map plus the boundary map, and these two are concatenated together to feed into the network.
学习实例级别的特征编码
图像合成是一个一对多映射问题(one-to-many)。现有的一对多模型关注图像的颜色、纹理的整体变化,无法解决对图像在物体级别上的控制。作者提出加入额外的低维特征通道作为G的输入。由于特征通道是连续量,理论上可以生成无限个图像。
为了得到低维特征,需要训练一个编码器E,为每个实例生成与ground truth中的目标相对应的低维特征。为了保证在每个实例范围内的特征是一致的,在编码器的输出处加入一个实例级的平均池化层,计算实例的平均特征,然后将平均特征向该实例的所有像素位置传播。
训练好编码器后,在训练图像上的每个实例上跑一遍,记录下得到的特征,接着为每个语义类别的特征进行K均值集簇,每个簇为每个特征编码一个特定的风格,如一条路的材质是沥青还是卵石,这样就给自定义风格提供了方案。在inference阶段,随机选择一个簇作为编码的特征,与标签图拼接,作为G的输入。
与其他模型生成的高分辨率图像比较,该模型生成的图像细节更真实,更清晰。
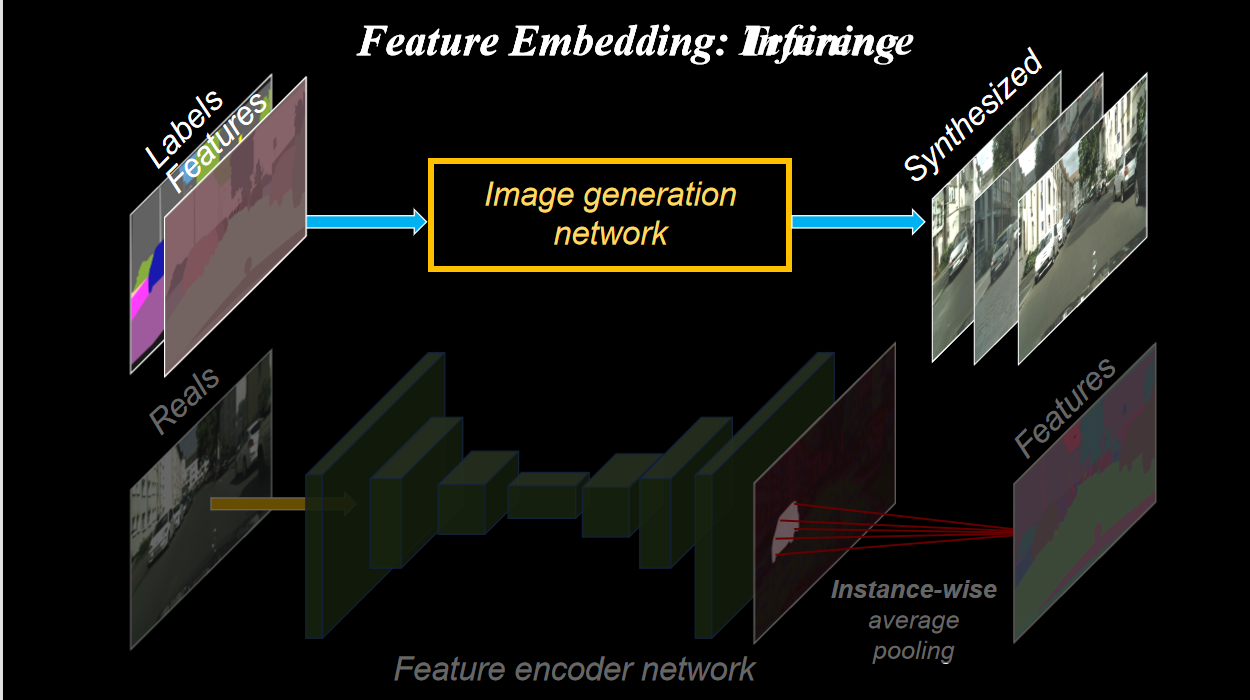
To generate different outputs, we use a feature embedding scheme. First, during training, the original image is put into a feature encoder network to generate a feature map. Then we run instance-wise pooling on the output map. For each instance in the image(例如图中的一个小汽车), we average the features, then broadcast the averaged value to the entire instance(剩余的小汽车). We repeat the step for all the instances. This feature map is then concatenated with the label map, and go through the generation network to generate the final image. This whole process is trained end-to-end, so the feature map should encode appearances in the original image, like the color of a car or the texture of a road. Then, at inference time, we can just change the feature maps, and we are able to get different output images.



















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











