







可以这么认为。
如图1,今天在使用self-attention去处理一张图片的时候,1的那个pixel产生query,其他的各个pixel产生key。在做inner-product的时候,考虑的不是一个小的范围,而是一整张图片。
但是在做CNN的时候是只考虑感受野红框里面的资讯,而不是图片的全局信息。所以CNN可以看作是一种简化版本的self-attention。
或者可以反过来说,self-attention是一种复杂化的CNN,在做CNN的时候是只考虑感受野红框里面的资讯,而感受野的范围和大小是由人决定的。但是self-attention由attention找到相关的pixel,就好像是感受野的范围和大小是自动被学出来的,所以CNN可以看做是self-attention的特例,如图2所示。
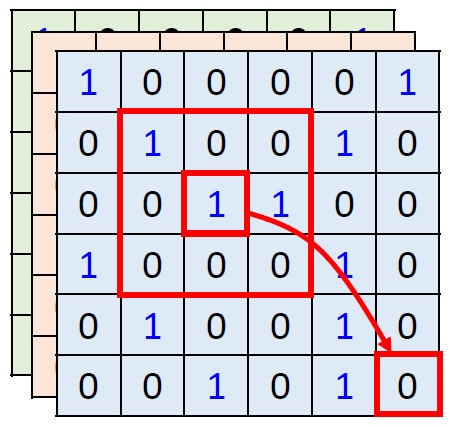
图1:CNN考虑感受野范围,而self-attention考虑的不是一个小的范围,而是一整张图片
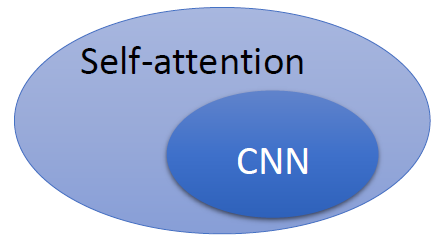
图2:CNN可以看做是self-attention的特例
既然self-attention是更广义的CNN,则这个模型更加flexible。而我们认为,一个模型越flexible,训练它所需要的数据量就越多,所以在训练self-attention模型时就需要更多的数据,这一点在论文 ViT 中有印证,它需要的数据集是有3亿张图片的私有数据集 JFT-300,性能超越了CNN。而如果不使用这么多数据而只使用ImageNet,则性能不如CNN。
2021.4.9 update
有幸与华为深圳语音语义实验室的NLP领域权威专家侯老师交流。老师提供了一种新的观点,个人觉得很有用,特此更新如下:
Self-attention的attention map其实是随着样本的变化而不断变化的,所以从这个意义上它可以看做是instance-wise的一个网络。那么attention map与value矩阵作用就相当于是矩阵乘法,也就相当于是value通过一层FFN,只是这个FFN的参数是动态变化的。所以这个意义上也可以看做是一种更广义的CNN。
总结
上面这个回答的意思是说:CNN是一种很特殊的Self-attention,它总是通过local receptive fields, shared weights, spatial subsampling等等的操作,考虑一张图片的空间上相邻的那些信息 (spatially neighboring pixels)。而正好这些信息是高度相关的 (highly correlated)。可是,基于Transformer的ViT模型就没有这种特性了,所以需要更多的数据来训练,这是第1个property。
另1个property是CNN的hierarchical structure可以考虑不同level的信息,不论是low-level的边缘特征还是high-level的语义特征。
那么一个自然而然的问题是:可否把CNN融入Transformer中,使得Transformer也具有CNN的这些适合图片的property呢?
其实从理论上来讲完全没必要这么做,因为从图2我们就知道Self-attention就是一种更复杂,更广泛的CNN。但是问题是要想把ViT训练得和CNN一样好需要很多的图片,甚至是JFT-300这样的私有数据集。所以,将CNN融入Transformer中的目的就是节约数据集。
以上就是CvT这个工作的motivation。(Vision Transformer 超详细解读 (原理分析+代码解读) (六) - 知乎本系列已授权极市平台,未经允许不得二次转载,如有需要请私信作者。考虑到每篇文章字数的限制, 每一篇文章将按照目录的编排包含两到三个小节,而且这个系列会随着Vision Transformer的发展而长期更新。专栏目录…![]() https://zhuanlan.zhihu.com/p/361112935)
https://zhuanlan.zhihu.com/p/361112935)
CvT具有CNN的一些优良的特征:局部感受野,共享卷积权重,空间下采样。
CvT具有Self-attention的一些优良的特征:动态的注意力机制,全局信息的融合。

















 658
658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











