







一、输入和输出
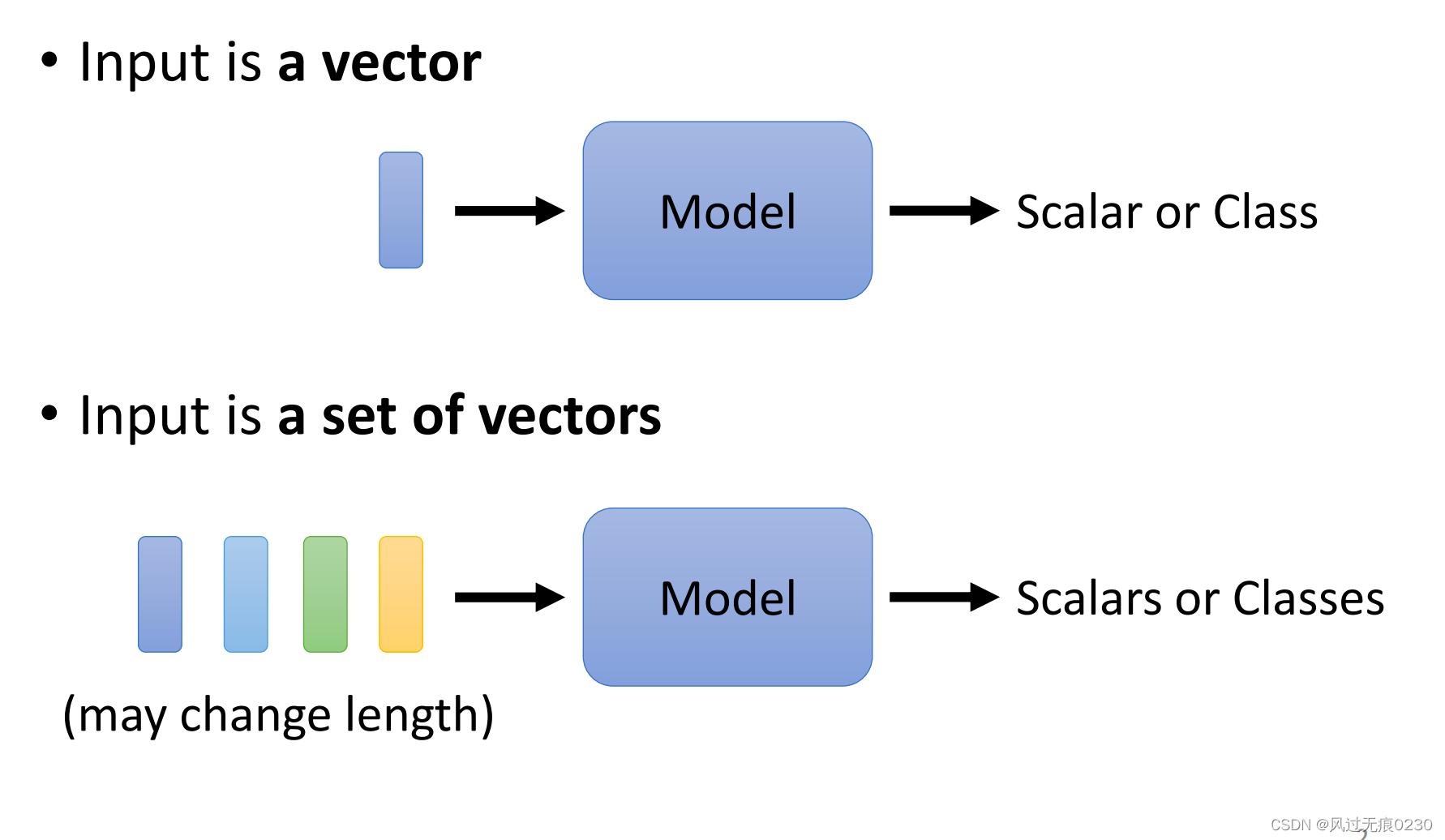
输入
普通的神经网络输入是一个向量,自注意力机制的输入是向量的集合,每个向量代表序列的一个元素,并且输入长度可以不固定。
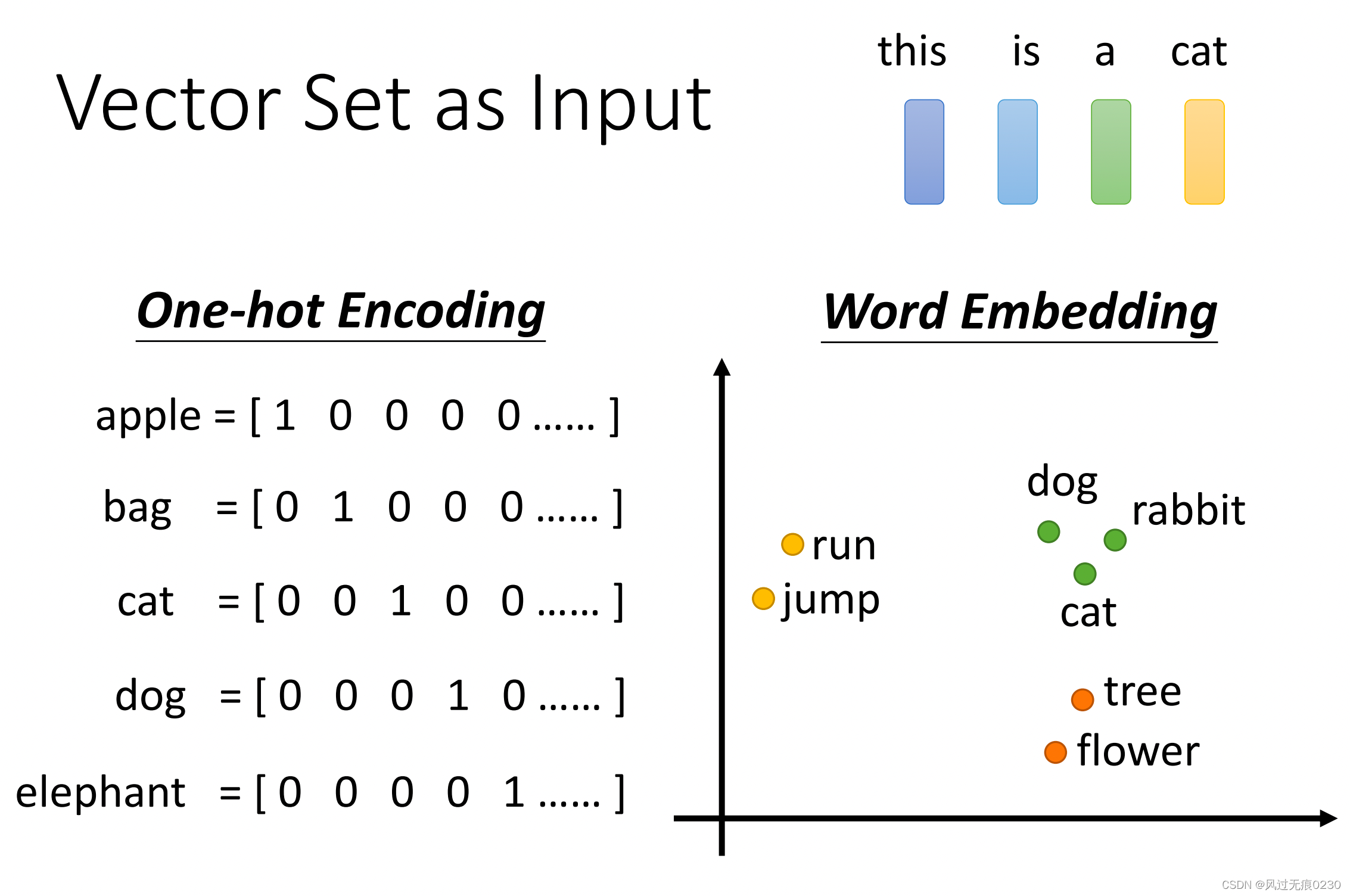
**一个输入的例子是句子,每个单词用一个向量表示。**单词用下图的Word Embedding(词嵌入)向量表示,词嵌入有现成的向量可以套用。之所以不用独热向量表示单词,是因为它没办法体现词汇间的关系,而词嵌入向量具备语义信息,比如同类词(苹果和梨)的向量距离会比较近。
其他的序列比如语音和图也可以作为输入。
输出
- 每个向量输出一个标签,比如词性标注(POS tagging)、音素识别等
- 整个序列输出一个标签,比如情感分析(sentiment analysis)、语者识别等
- 模型自己决定输出的标签数量(seq2seq),比如机器翻译
二、Self-attention的计算过程
输入一定长度的向量序列,输出同样数量的向量,并且输出的向量包含了该位置上下文的语义信息。
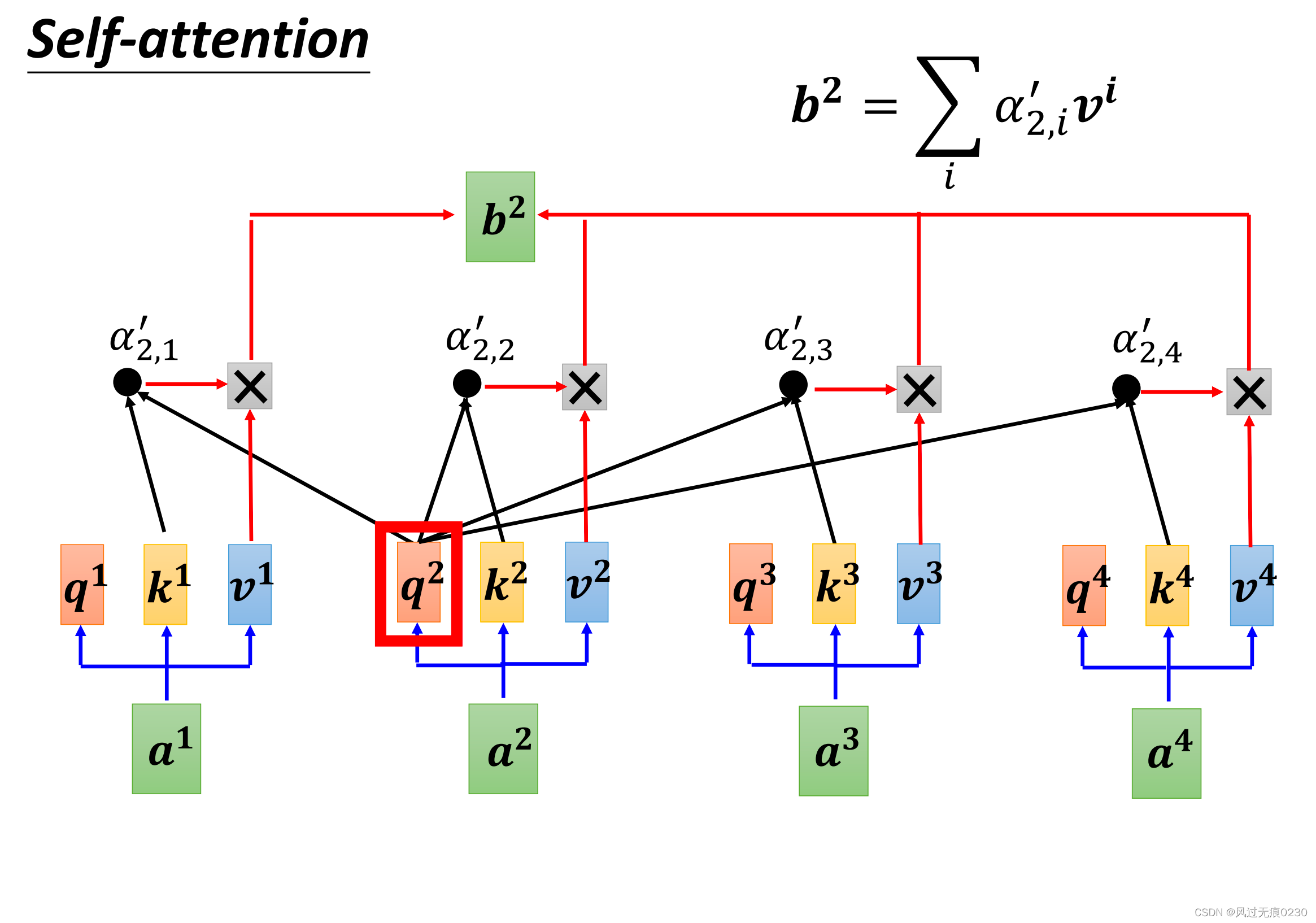
单个输出向量的计算
先计算每个节点的q、k、v,然后再计算α、α’,最后算出b。
α(attention score)为k和q的内积,α’是该节点的所有α值对应的softmax值,b是所有节点v值的加权平均。
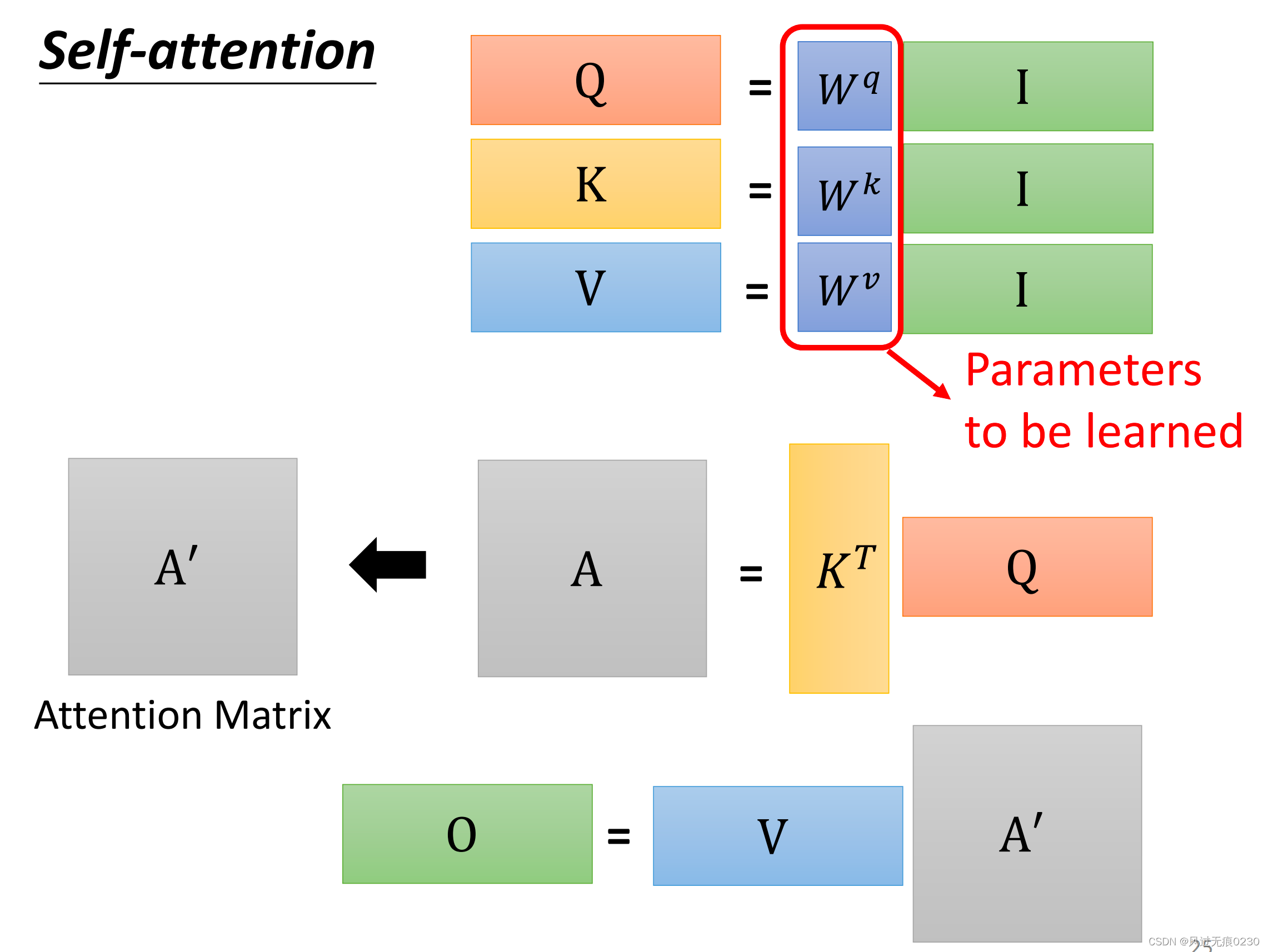
整体输入和输出的矩阵化表示
𝑊𝑞、𝑊k、𝑊v是需要学习的参数。
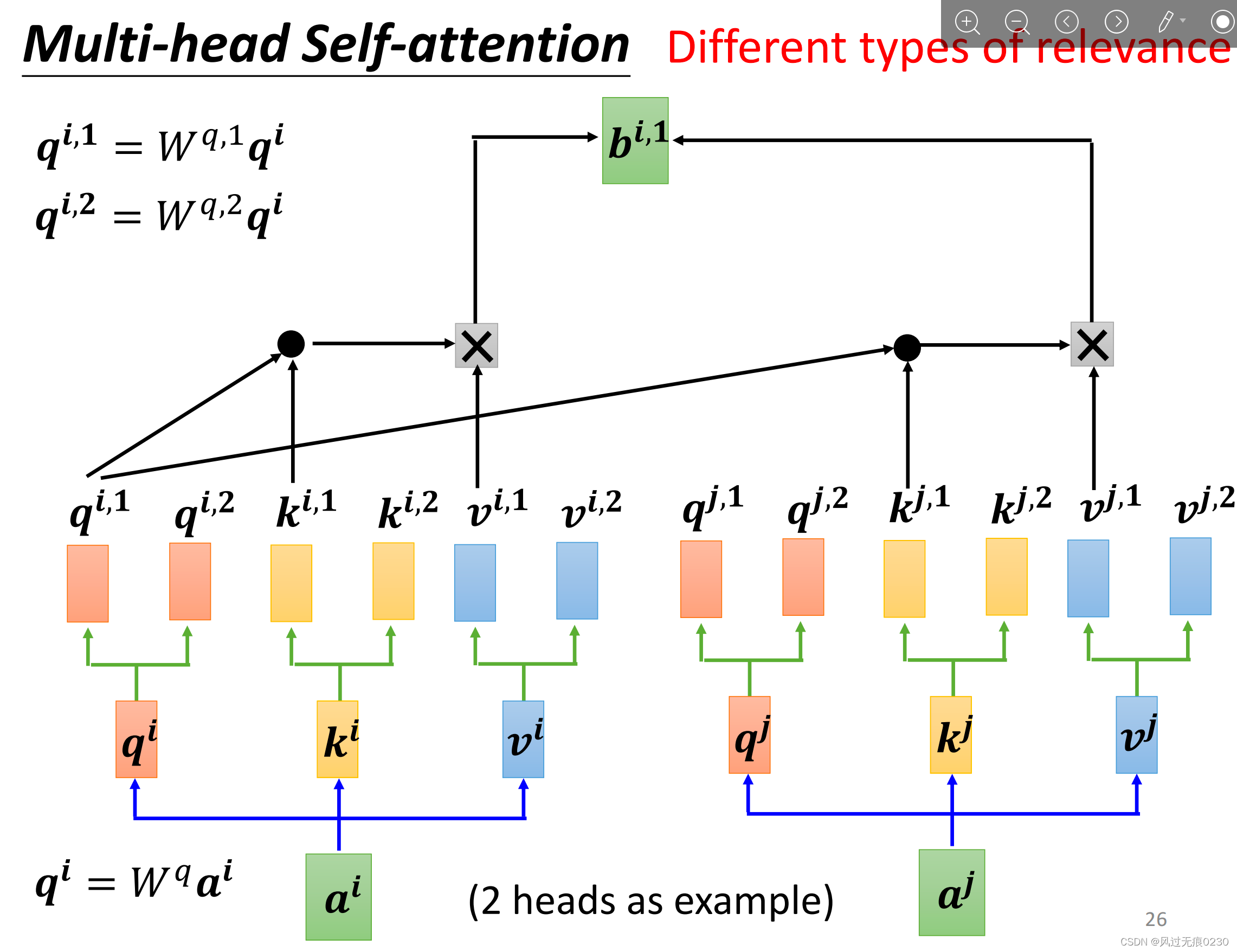
多头自注意力机制
通过多头可以发现不同的相关性类型,原理是下面三张图。
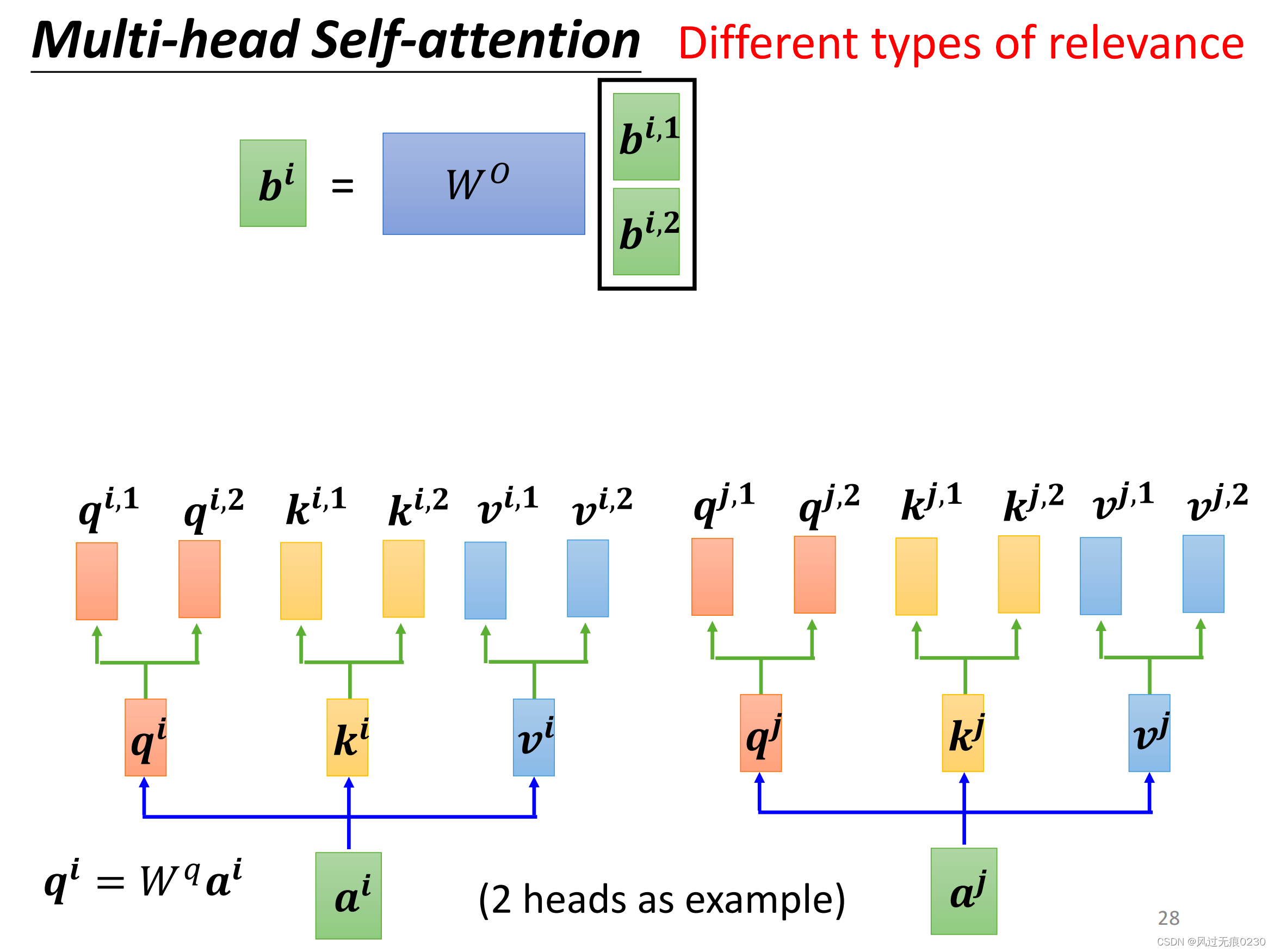
与单头相比每个输入向量产生q、k、v后,会分别进一步生成n组,然后每一组分别生成一个b;把n个b纵向拼接;用一个新的矩阵W0去乘以上一步拼接后的向量,得到一个输出向量。

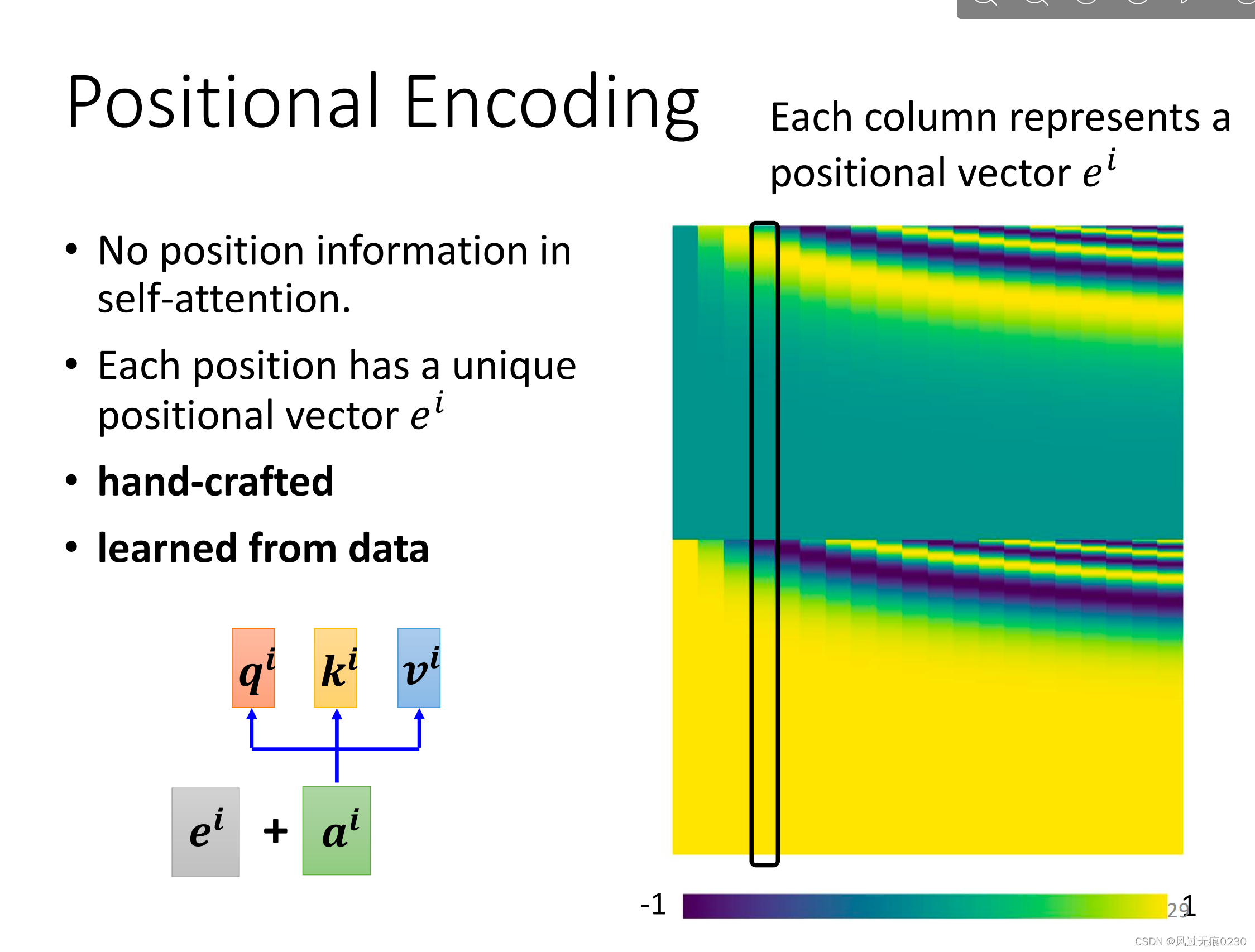
位置编码(Positional Encoding)
自注意力机制只体现了不同向量之间的关系,而没有先后顺序的信息。有一些人工设计的位置编码,每个向量加上该位置的位置编码,从而把位置的信息也包含进去。
三、自注意力机制与传统网络的对比
对比CNN
CNN可以看成自注意力机制的特例。
在CNN中,自注意力机制只在感受野内发挥作用,所以说CNN是简化版的Self-attention。

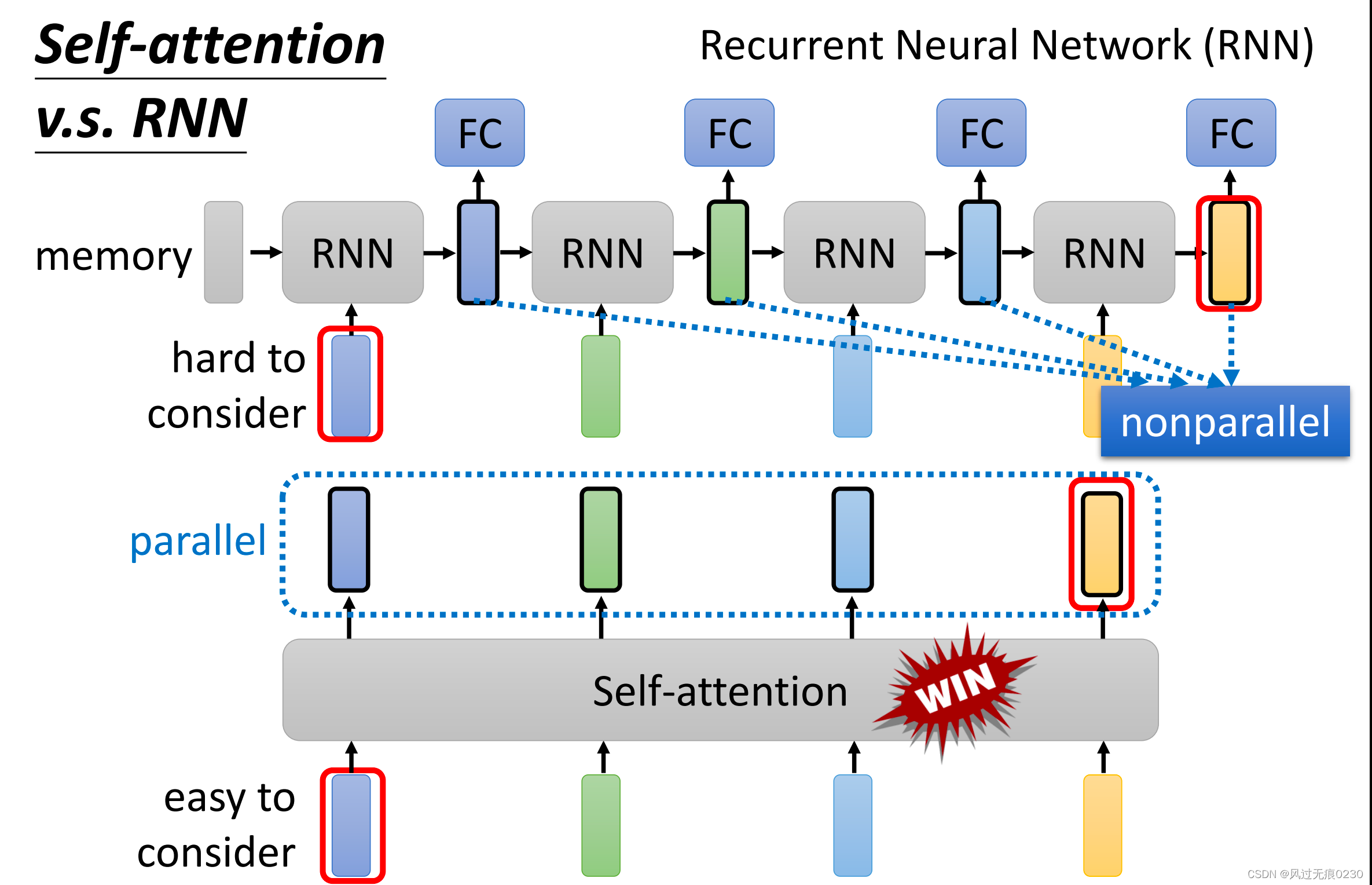
对比RNN
相对RNN来说,自注意力机制可以更好地捕捉输入向量之间的关系,特别是距离比较远的优势更加明显。同时,自注意机制的输出向量是并行计算的,不像RNN前后依赖,所以训练速度快。














 95
95











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









