







浅谈TD3:从算法原理到代码实现
引言
众所周知,在基于价值学习的强化学习算法中,如DQN,函数近似误差是导致Q值高估和次优策略的原因。我们表明这个问题依然在AC框架中存在,并提出了新的机制去最小化它对演员(策略函数)和评论家(估值函数)的影响。我们的算法建立在双Q学习的基础上,通过选取两个估值函数中的较小值,从而限制它对Q值的过高估计。(出自TD3论文摘要)
1. 什么是TD3
TD3是Twin Delayed Deep Deterministic policy gradient algorithm的全称。TD3全称中Deep Deterministic policy gradient algorithm就是DDPG的全称。那么DDPG和TD3有何渊源呢?其实简单的说,TD3是DDPG的一个优化版本。
1.1 TD3为什么被提出
在强化学习中,对于离散化的动作的学习,都是以DQN为基础的,DQN则是通过的 a r g M a x Q t a b l e argMaxQ_{table} argMaxQtable的方式去选择动作,往往都会过大的估计价值函数,从而造成误差。在连续的动作控制的AC框架中,如果每一步都采用这种方式去估计,导致误差一步一步的累加,导致不能找到最优策略,最终使算法不能得到收敛。
1.2 TD3在DDPG的基础上都做了些什么
-
使用两个Critic网络。使用两个网络对动作价值函数进行估计,(这Double DQN 的思想差不多)。在训练的时候选择 m i n ( Q θ 1 ( s , a ) , Q θ 2 ( s , a ) ) min(Q^{\theta1}(s,a),Q^{\theta2}(s,a)) min(Qθ1(s,a),Qθ2(s,a))作为估计值。
-
使用软更新的方式 。不再采用直接复制,而是使用 θ = τ θ ′ + ( 1 − τ ) θ \theta = \tau\theta^′ + (1 - \tau)\theta θ=τθ′+(1−τ)θ的方式更新网络参数。
-
使用策略噪音。使用Epsilon-Greedy在探索的时候使用了探索噪音。(还是用了策略噪声,在更新参数的时候,用于平滑策略期望)
-
使用延迟学习。Critic网络更新的频率要比Actor网络更新的频率要大。
-
使用梯度截取。将Actor的参数更新的梯度截取到某个范围内。
2. TD3算法思路

图1. TD3算法流程
TD3算法的大致思路,首先初始化3个网络,分别为 Q θ 1 , Q θ 2 , π ϕ Q_{\theta1},Q_{\theta2},\pi_\phi Qθ1,Qθ2,πϕ ,参数为 θ 1 , θ 2 , ϕ \theta_1,\theta_2,\phi θ1,θ2,ϕ,在初始化3个Target网络,分别将开始初始化的3个网络参数分别对应的复制给target网络。 θ 1 ′ ← θ 1 , θ 2 ′ ← θ 2 , ϕ ′ ← ϕ \theta{_1^′}\leftarrow\theta_1,\theta{_2^′}\leftarrow\theta_2,\phi_′\leftarrow\phi θ1′←θ1,θ2′←θ2,ϕ′←ϕ 。初始化Replay Buffer β \beta β 。
然后通过循环迭代,一次次找到最优策略。每次迭代,在选择action的值的时候加入了噪音,使 a π ϕ ( s ) + ϵ a~\pi_\phi(s) + \epsilon a πϕ(s)+ϵ, ϵ ∼ N ( 0 , σ ) \epsilon \sim N(0,\sigma) ϵ∼N(0,σ),然后将 ( s , a , r , s ′ ) (s,a,r,s^′) (s,a,r,s′)放入 β \beta β,当 β \beta β达到一定的值时候。
然后随机从 β \beta β中Sample出Mini-Batch个数据,通过 a ~ ∼ π ϕ ′ ( s ′ ) + ϵ \tilde{a} \sim\pi_{\phi^′}(s^′) + \epsilon a~∼πϕ′(s′)+ϵ, ϵ ∼ c l i p ( N ( 0 , σ ~ ) , − c , c ) \epsilon \sim clip(N(0,\tilde\sigma),-c,c) ϵ∼clip(N(0,σ~),−c,c),计算出 s ′ s^′ s′状态下对应的Action的值 a ~ \tilde a a~,通过 s ′ , a ~ s^′,\tilde a s′,a~,计算出 t a r g e t Q 1 , t a r g e t Q 2 targetQ1,targetQ2 targetQ1,targetQ2,获取 m i n ( t a r g e t Q 1 , t a r g e t Q ) min(targetQ1,targetQ) min(targetQ1,targetQ),为 s ′ s^′ s′的 t a r g e t Q targetQ targetQ值。
通过贝尔曼方程计算 s s s的 t a r g e t Q targetQ targetQ值,通过两个Current网络根据 s , a s,a s,a分别计算出当前的 Q Q Q值,在将两个当前网络的 Q Q Q值和 t a r g e t Q targetQ targetQ值通过MSE计算Loss,更新参数。
Critic网络更新之后,Actor网络则采用了延时更新,(一般采用Critic更新2次,Actor更新1次)。通过梯度上升的方式更新Actor网络。通过软更新的方式,更新target网络。
-
为什么在更新Critic网络时,在计算Action值的时候加入噪音,是为了平滑前面加入的噪音。
-
贝尔曼方程:针对一个连续的MRP(Markov Reward Process)的过程(连续的状态奖励过程),状态 s s s转移到下一个状态 s ′ s^′ s′ 的概率的固定的,与前面的几轮状态无关。其中, v v v表示一个对当前状态state 进行估值的函数。 γ \gamma γ一般为趋近于1,但是小于1。

图2. 贝尔曼方程
3. 代码实现
代码主要是根据DDPG的代码以及TD3的论文复现的,使用的是Pytorch1.7实现的。
3.1 搭建网络结构
Q1网络结构主要是用于更新Actor网络
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.f1 = nn.Linear(state_dim, 256)
self.f2 = nn.Linear(256, 128)
self.f3 = nn.Linear(128, action_dim)
self.max_action = max_action
def forward(self,x):
x = self.f1(x)
x = F.relu(x)
x = self.f2(x)
x = F.relu(x)
x = self.f3(x)
return torch.tanh(x) * self.max_action
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic,self).__init__()
self.f11 = nn.Linear(state_dim+action_dim, 256)
self.f12 = nn.Linear(256, 128)
self.f13 = nn.Linear(128, 1)
self.f21 = nn.Linear(state_dim + action_dim, 256)
self.f22 = nn.Linear(256, 128)
self.f23 = nn.Linear(128, 1)
def forward(self, state, action):
sa = torch.cat([state, action], 1)
x = self.f11(sa)
x = F.relu(x)
x = self.f12(x)
x = F.relu(x)
Q1 = self.f13(x)
x = self.f21(sa)
x = F.relu(x)
x = self.f22(x)
x = F.relu(x)
Q2 = self.f23(x)
return Q1, Q2
3.2 定义网络
self.actor = Actor(self.state_dim, self.action_dim, self.max_action)
self.target_actor = copy.deepcopy(self.actor)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=3e-4)
#定义critic网络
self.critic = Critic(self.state_dim, self.action_dim)
self.target_critic = copy.deepcopy(self.critic)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=3e-4)
3.3 更新网络
更新网络采用软更新,延迟更新等方式
def learn(self):
self.total_it += 1
data = self.buffer.smaple(size=128)
state, action, done, state_next, reward = data
with torch.no_grad:
noise = (torch.rand_like(action) * self.policy_noise).clamp(-self.noise_clip, self.noise_clip)
next_action = (self.target_actor(state_next) + noise).clamp(-self.max_action, self.max_action)
target_Q1,target_Q2 = self.target_critic(state_next, next_action)
target_Q = torch.min(target_Q1, target_Q2)
target_Q = reward + done * self.discount * target_Q
current_Q1, current_Q2 = self.critic(state, action)
critic_loss = F.mse_loss(current_Q1, target_Q) + F.mse_loss(current_Q2, target_Q)
critic_loss.backward()
self.critic_optimizer.step()
if self.total_it % self.policy_freq == 0:
q1,q2 = self.critic(state, self.actor(state))
actor_loss = -torch.min(q1, q2).mean()
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
for param, target_param in zip(self.critic.parameters(), self.target_critic.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
for param, target_param in zip(self.actor.parameters(), self.target_actor.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
4. 总结
TD3是DDPG的一个升级版,在解决很多的问题上,效果要比DDPG的效果好的多,无论是训练速度,还是结果都有显著的提高。
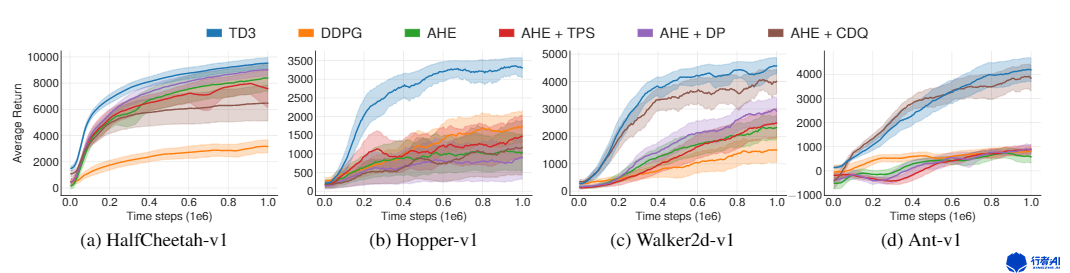
图3. 算法效果对比
5. 资料
- http://proceedings.mlr.press/v80/fujimoto18a/fujimoto18a.pdf















 5647
5647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









