







 本文介绍了对数几率回归模型,通过单位阶跃函数和Sigmoid函数,将线性回归的预测值转换为分类。重点讲解了如何通过最大化对数似然估计参数,以及在实际应用中的梯度下降求解方法。
本文介绍了对数几率回归模型,通过单位阶跃函数和Sigmoid函数,将线性回归的预测值转换为分类。重点讲解了如何通过最大化对数似然估计参数,以及在实际应用中的梯度下降求解方法。
前言
本篇文章是笔者在学习周志华老师《机器学习》第三章节对数几率回归部分过程中,结合各方参考资料,记录下的对数几率回归模型的重点知识与内容,并加以自己的理解详细讲述。
以下是本篇文章正文内容
一、对数几率回归模型
在线性回归模型中,预测值y往往是一个具体的实值,而在分类预测场景当中,一个具体的预测实值不足以形成最终的分类预测。因此我们可以考虑将线性回归模型产生的预测实值,转换为0/1等分类值。
单位阶跃函数(unit-step function)就是一种比较理想的分类函数:
y
=
{
0
,
z
<
0
0.5
,
z
=
0
1
,
z
>
0
(1.1)
y = \left\{\begin{aligned}0,z<0 \\0.5,z=0\\1,z>0\end{aligned}\right. \tag{1.1}
y=⎩⎪⎨⎪⎧0,z<00.5,z=01,z>0(1.1)
单位阶跃函数图像如图所示:
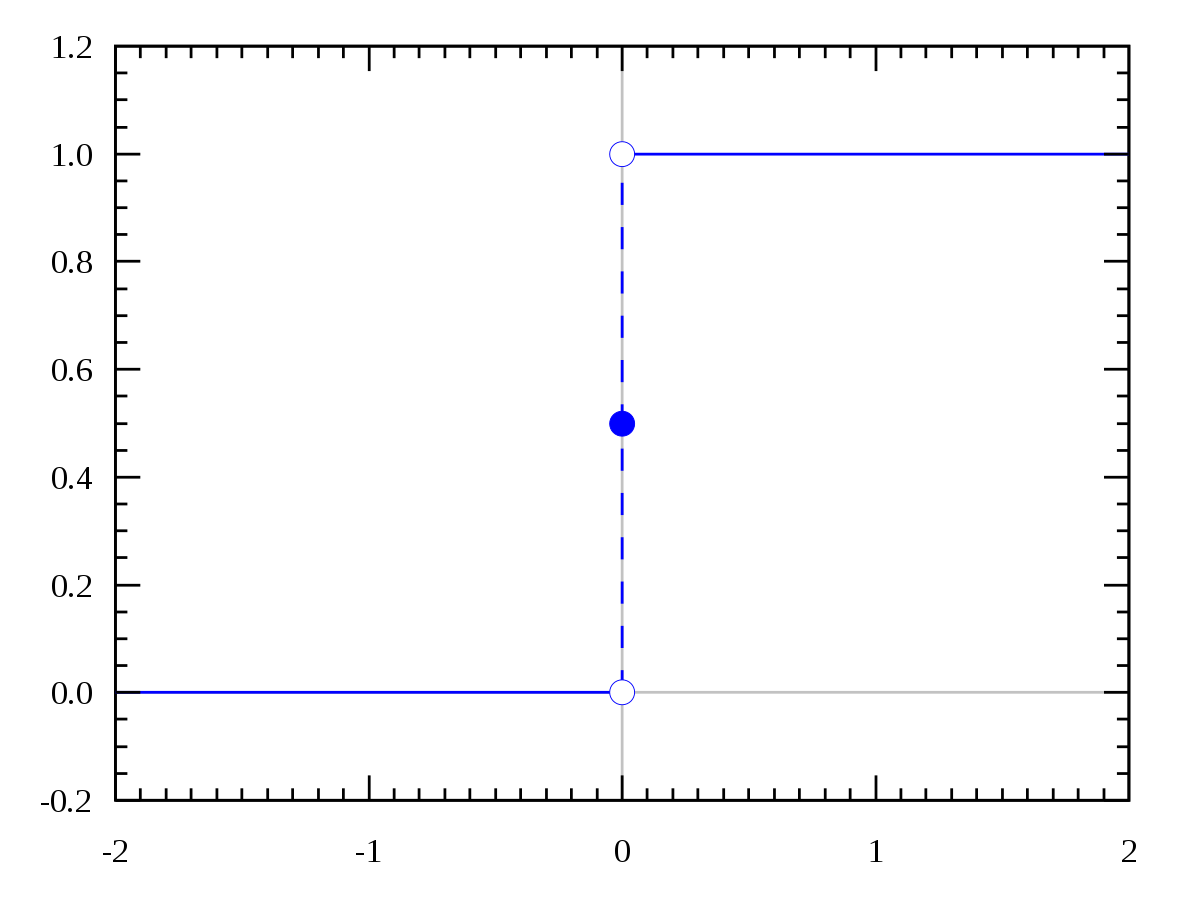
单位阶跃函数即表示当预测值z大于零就判为正例,小于零则判为反例,预测值为临界值零则可任意判别。但是由于单位阶跃函数不连续,不能作为广义线性回归模型的联系函数
y
=
g
−
1
(
ω
T
x
+
b
)
(1.2)
y = g^{-1}(\omega^{T}x+b) \tag{1.2}
y=g−1(ωTx+b)(1.2)
即 g ( ⋅ ) g(·) g(⋅)函数的连续性需与 ω T x + b \omega^{T}x+b ωTx+b保持一致
在这里考虑用一个无限接近单位近阶跃函数的连续函数来代替单位阶跃函数,并希望它单调可微(与线性回归模型保持一致)。而对数几率函数(logistic function)正是这样一个常用的替代函数。
y
=
1
1
+
e
−
z
(1.3)
y = \frac{1}{1+e^{-z}} \tag{1.3}
y=1+e−z1(1.3)
对数几率函数图像如图所示:
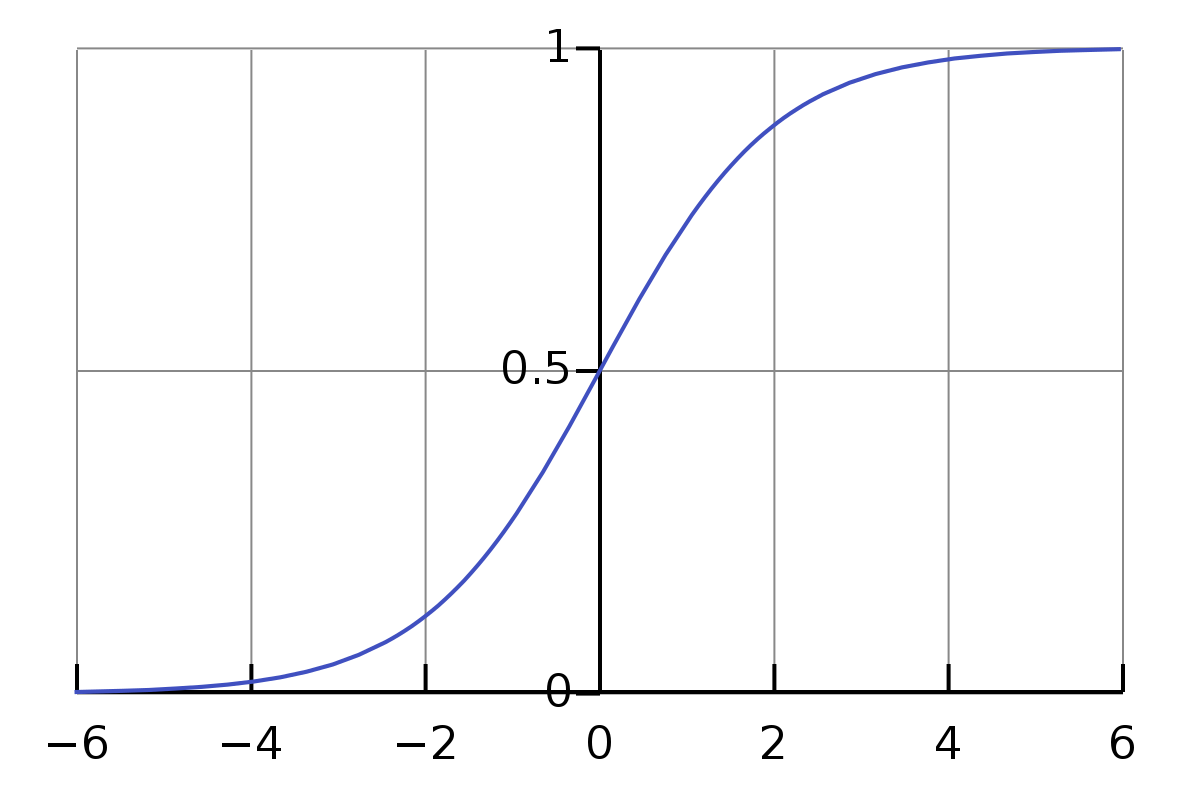
对数几率函数是一种Sigmoid函数,它将z值转化为一个接近0或者1的y值。将对数几率函数代入广义线性模型得到
y
=
1
1
+
e
−
(
ω
T
x
+
b
)
(1.4)
y = \frac{1}{1+e^{-(\omega^Tx+b)}} \tag{1.4}
y=1+e−(ωTx+b)1(1.4)
该式可变化为
l
n
y
1
−
y
=
ω
T
x
+
b
(1.5)
ln\frac{y}{1-y}= \omega^Tx+b \tag{1.5}
ln1−yy=ωTx+b(1.5)
若将y视为样本作为正例的可能性,则1-y是其反例的可能性,两者的比值称为“几率”,反映了样本作为正例的相对可能性.
y
1
−
y
(1.6)
\frac{y}{1-y} \tag{1.6}
1−yy(1.6)
对几率取对数则可得到“对数几率”
l
n
y
1
−
y
(1.7)
ln\frac{y}{1-y} \tag{1.7}
ln1−yy(1.7)
对数几率回归实际上是在用线性回归模型的预测结果去逼近真实标记的对数几率,特别需要注意到,虽然它的名字是“回归”,但实际上是一种分类学习方法。对数回归求解的目标函数是任意阶可导的凸函数。
要确定线性回归模型中的
ω
\omega
ω和
b
b
b,将式(1.5)中的y视为后验概率估计
p
(
y
=
1
∣
x
)
p(y=1 | x)
p(y=1∣x), 即式子可重写为
l
n
p
(
y
=
1
∣
x
)
p
(
y
=
0
∣
x
)
=
ω
T
x
+
b
(1.8)
ln\frac{p(y=1|x)}{p(y=0|x)}=\omega^{T}x + b\tag{1.8}
lnp(y=0∣x)p(y=1∣x)=ωTx+b(1.8)
后验概率在这里可以理解为已知样本x,其为正例或者反例的概率
对式子1.8进行变式
e
l
n
p
(
y
=
1
∣
x
)
1
−
p
(
y
=
1
∣
x
)
=
e
ω
T
x
+
b
p
(
y
=
1
∣
x
)
1
−
p
(
y
=
1
∣
x
)
=
e
ω
T
x
+
b
\begin{aligned} e^{ln\frac{p(y=1|x)}{1-p(y=1|x)}}&=e^{\omega^{T}x+b}\\ \frac{p(y = 1| x)}{1-p(y=1|x)}&=e^{\omega^Tx+b} \end{aligned}
eln1−p(y=1∣x)p(y=1∣x)1−p(y=1∣x)p(y=1∣x)=eωTx+b=eωTx+b
最终得到
p
(
y
=
1
∣
x
)
=
e
ω
T
x
+
b
1
+
e
ω
T
x
+
b
(1.9)
\begin{aligned} p(y=1|x)&=\frac{e^{\omega^{T}x+b}}{1+e^{\omega^{T}x+b}} \tag{1.9} \end{aligned}
p(y=1∣x)=1+eωTx+beωTx+b(1.9)
p
(
y
=
0
∣
x
)
=
1
1
+
e
ω
T
x
+
b
(1.10)
\begin{aligned} p(y=0|x)&=\frac{1}{1+e^{\omega^{T}x+b}} \tag{1.10} \end{aligned}
p(y=0∣x)=1+eωTx+b1(1.10)
二、对率回归模型最大化“对数似然”
最大似然估计的基本思想为:在已知实验结果以及模型分布的情况下,找出让该实验结果发生概率最大时的参数值。
应用到对率回归模型中,给定的数据集即为已知的实验结果,而每一个样本发生的概率也由式1.9和式1.10给出,对该对率回归模型作最大化似然估计,其中m为数据集中样本的个数:
l
(
ω
,
b
)
=
∑
i
=
1
m
p
(
y
i
∣
x
i
;
ω
,
b
)
(2.1)
l(\omega,b)=\sum_{i=1}^{m}p(y_i|x_i;\omega,b)\tag{2.1}
l(ω,b)=i=1∑mp(yi∣xi;ω,b)(2.1)
式1.9和式1.10中涉及指数运算,为了让运算过程变得简单且不影响其单调性,对最大似然函数取对数,实现“对数似然”
l
(
ω
,
b
)
=
∑
i
=
1
m
ln
p
(
y
i
∣
x
i
;
ω
,
b
)
(2.2)
l(\omega,b)=\sum_{i=1}^{m}\ln p(y_i|x_i;\omega,b)\tag{2.2}
l(ω,b)=i=1∑mlnp(yi∣xi;ω,b)(2.2)
对率回归模型中的参数
ω
\omega
ω和
b
b
b的取值要使式2.2中的值达到最大值,即令每个样本属于其真实标记的概率越大越好
为了便于讨论,令
β
=
(
ω
;
b
)
\beta=(\omega;b)
β=(ω;b),
x
^
=
(
x
;
1
)
\hat{x}=\left(x;1\right)
x^=(x;1),则
ω
x
+
b
\omega x+b
ωx+b可简写为
β
T
x
^
\beta^{T}\hat{x}
βTx^. 再令
p
1
(
x
^
;
β
)
=
p
(
y
=
1
∣
x
^
;
β
)
p_{1}\left(\hat{x};\beta\right)=p(y=1|\hat{x};\beta)
p1(x^;β)=p(y=1∣x^;β),
p
0
(
x
^
;
β
)
=
1
−
p
(
y
=
1
∣
x
^
;
β
)
p_{0}\left(\hat{x};\beta\right)=1 - p(y=1|\hat{x};\beta)
p0(x^;β)=1−p(y=1∣x^;β),则式2.2中的似然项可重写为
p
(
y
i
∣
x
i
;
ω
,
b
)
=
y
i
p
1
(
x
^
i
;
β
)
+
(
1
−
y
i
)
p
0
(
x
^
i
;
β
)
(2.3)
p(y_i|x_i;\omega,b)=y_{i}p_{1}(\hat{x}_{i};\beta) + (1-y_{i})p_{0}(\hat{x}_{i};\beta)\tag{2.3}
p(yi∣xi;ω,b)=yip1(x^i;β)+(1−yi)p0(x^i;β)(2.3)
将式2.3代入式2.2,并根据式1.9和式1.10,推导出演算过程
ln
p
(
y
i
∣
x
i
;
ω
,
b
)
=
l
n
(
y
i
⋅
e
β
T
x
1
+
e
β
T
x
^
+
(
1
−
y
i
)
⋅
1
1
+
e
β
T
x
^
)
=
l
n
(
y
i
⋅
e
β
T
x
^
+
(
1
−
y
i
)
1
+
e
β
T
x
^
)
=
y
i
⋅
l
n
(
e
β
T
x
^
)
−
l
n
(
1
+
e
β
T
x
^
)
=
y
i
⋅
β
T
x
^
−
l
n
(
1
+
e
β
T
x
^
)
(2.4)
\begin{aligned} \ln p(y_i|x_i;\omega,b)&=ln(\frac{y_{i}\cdot e^{\beta^{T}x}}{1+e^{\beta^{T}\hat{x}}}+(1-y_{i})\cdot\frac{1}{1+e^{\beta^{T}\hat{x}}})\\ &=ln(\frac{y_{i}\cdot e^{\beta^{T}\hat{x}}+(1-y_{i})}{1+e^{\beta^{T}\hat{x}}})\\ &=y_{i}\cdot ln(e^{\beta^{T}\hat{x}}) - ln(1+e^{\beta^{T}\hat{x}})\\ &=y_{i}\cdot\beta^{T}\hat{x} - ln(1+e^{\beta^{T}\hat{x}})\tag{2.4} \end{aligned}
lnp(yi∣xi;ω,b)=ln(1+eβTx^yi⋅eβTx+(1−yi)⋅1+eβTx^1)=ln(1+eβTx^yi⋅eβTx^+(1−yi))=yi⋅ln(eβTx^)−ln(1+eβTx^)=yi⋅βTx^−ln(1+eβTx^)(2.4)
需要对演算过程中注意的是对
1
−
y
i
1-y_{i}
1−yi的化简,对
y
i
y_{i}
yi考虑两种情况分别为0和1
当
y
i
=
1
y_{i}=1
yi=1时,
1
−
y
i
=
0
1-y_{i}=0
1−yi=0
y
i
⋅
e
β
T
x
^
+
(
1
−
y
i
)
=
y
i
⋅
e
β
T
x
^
(2.5)
y_{i}\cdot e^{\beta^{T}\hat{x}}+(1-y_{i})=y_{i}\cdot e^{\beta^{T}\hat{x}}\tag{2.5}
yi⋅eβTx^+(1−yi)=yi⋅eβTx^(2.5)
当
y
i
=
0
y_{i}=0
yi=0时,
y
i
⋅
e
β
T
x
^
+
(
1
−
y
i
)
y_{i}\cdot e^{\beta^{T}\hat{x}}+(1-y_{i})
yi⋅eβTx^+(1−yi)项整体为0, 即式2.5成立
已知求最大值即求其相反数的最小值,对算式2.4取相反数并代入式2.2可得:
l
(
β
)
=
∑
1
m
−
y
i
⋅
β
T
x
^
+
l
n
(
1
+
e
β
T
x
^
)
(2.6)
l(\beta)=\sum_{1}^{m}-y_{i}\cdot\beta^{T}\hat{x} + ln(1+e^{\beta^{T}\hat{x}})\tag{2.6}
l(β)=1∑m−yi⋅βTx^+ln(1+eβTx^)(2.6)
式2.6是关于
β
\beta
β的高阶可导连续凸函数,根据凸优化理论,经典的数值优化算法如梯度下降、牛顿法等都可求得其最优解。梯度下降法求解其最优值详看文章机器学习笔记(二)梯度下降法实现对数几率回归(Logistic Regression)
总结
本篇文章重点记录了对数几率回归(Logistic Regression)模型的主要内容和知识,其中包含笔者对该模型的主观认知和理解,若有错误之处,望读者指出。
参考文献
机器学习-周志华
单位阶跃函数-维基百科
Sigmoid函数-维基百科
对数几率函数(logistic function)-维基百科

















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









