







 本文介绍了一种基于R语言实现的电力负荷预测方法,包括数据预处理、时间序列分析及季节ARIMA模型建立等步骤。此外,还进行了聚类分析以揭示不同电力线路的特性。
本文介绍了一种基于R语言实现的电力负荷预测方法,包括数据预处理、时间序列分析及季节ARIMA模型建立等步骤。此外,还进行了聚类分析以揭示不同电力线路的特性。
基于负荷曲线的聚类分析与预测
数据预处理
# 安装库专用
# 通过如下命令设定镜像
options(repos = 'http://mirrors.ustc.edu.cn/CRAN/')
# 查看镜像是否修改
getOption('repos')
# 尝试下载R包
#若有需要,进行安装
#install.packages('forecast')
‘http://mirrors.ustc.edu.cn/CRAN/’
#设置工作路径
setwd("D:/LengPY")
#导入数据
library(readxl)
data<-read_excel("电力.xlsx")
head(data)
| 时间 | 东城站10kV广源线F10有功值 | 东城站10kV工业园甲线F09有功值 | 东城站10kV两报线F08有功值 | 东城站10kV中惠甲线F07有功值 | 东城站10kV奕垌线F06有功值 | 东城站10kV东城线F05有功值 | 东城站10kV碧桂园甲线F04有功值 | 东城站10kV县府线F03有功值 | 东城站10kV工业园乙线F11有功值 | ... | 东城站10kV中惠乙线F22有功值 | 东城站10kV佰利线F30有功值 | 东城站10kV东轩线F29有功值 | 东城站10kV大道线F28有功值 | 东城站10kV华科乙线F27有功值 | 东城站10kV华科甲线F26有功值 | 东城站10kV金桂线F25有功值 | 东城站10kV福兴线F24有功值 | 东城站10kV龙塘线F23有功值 | 汇总 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | ... | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
| 2021-03-01 | 0 | 0.812 | 1.383 | 1.015 | 0.250 | 1.222 | 0.622 | 1.467 | 0.364 | ... | 0.828 | 0.381 | 1.127 | 0.789 | 0.061 | 0 | 0.822 | 1.596 | 0 | 19.089 |
| 2021-03-01T00:14:59.99999979045242400 | 0 | 0.736 | 1.307 | 0.909 | 0.254 | 1.184 | 0.575 | 1.358 | 0.351 | ... | 0.783 | 0.338 | 1.099 | 0.795 | 0.076 | 0 | 0.722 | 1.532 | 0 | 18.389 |
| 2021-03-01T00:30:00.00000020954757600 | 0 | 0.753 | 1.197 | 0.854 | 0.228 | 1.087 | 0.571 | 1.328 | 0.326 | ... | 0.749 | 0.365 | 1.041 | 0.676 | 0.064 | 0 | 0.682 | 1.462 | 0 | 18.181 |
| 2021-03-01T00:45:00.000 | 0 | 0.436 | 1.138 | 0.723 | 0.211 | 1.002 | 0.524 | 1.277 | 0.321 | ... | 0.713 | 0.359 | 1.020 | 0.679 | 0.000 | 0 | 0.658 | 1.410 | 0 | 17.341 |
| 2021-03-01T00:59:59.99999979045242400 | 0 | 0.431 | 1.070 | 0.782 | 0.178 | 0.930 | 0.592 | 1.218 | 0.148 | ... | 0.673 | 0.362 | 0.987 | 0.621 | 0.067 | 0 | 0.603 | 1.349 | 0 | 16.424 |
| 2021-03-01T01:15:00.00000020954757600 | 0 | 0.423 | 0.981 | 0.727 | 0.165 | 0.926 | 0.575 | 1.197 | 0.144 | ... | 0.621 | 0.365 | 0.968 | 0.606 | 0.000 | 0 | 0.569 | 1.282 | 0 | 15.888 |
时间序列初步分析
白噪声检验
如果时间序列数据没有通过白噪声检验,则说明该序列为随机数序列,则没有建立时间序列模型进行分析的必要。
单位根检验 用来判断时间序列是否为平稳序列
协整检验和Granger因果检验
library(dplyr)
library(tidyr)
library(zoo)
library(tseries)
library(ggfortify)library(gridExtra)library(forecast)
Warning message:"package 'ggfortify' was built under R version 4.0.4"Loading required package: ggplot2Warning message:"package 'ggplot2' was built under R version 4.0.4"Warning message:"package 'gridExtra' was built under R version 4.0.4"Attaching package: 'gridExtra'
The following object is masked from 'package:dplyr': combine
Warning message:"package 'forecast' was built under R version 4.0.4"Registered S3 methods overwritten by 'forecast': method from autoplot.Arima ggfortify autoplot.acf ggfortify autoplot.ar ggfortify autoplot.bats ggfortify autoplot.decomposed.ts ggfortify autoplot.ets ggfortify autoplot.forecast ggfortify autoplot.stl ggfortify autoplot.ts ggfortify fitted.ar ggfortify fortify.ts ggfortify residuals.ar ggfortify
#将汇总数据转换为时间ts格式ARMAdata <- ts(data$汇总)#绘制时序图plot.ts(ARMAdata)
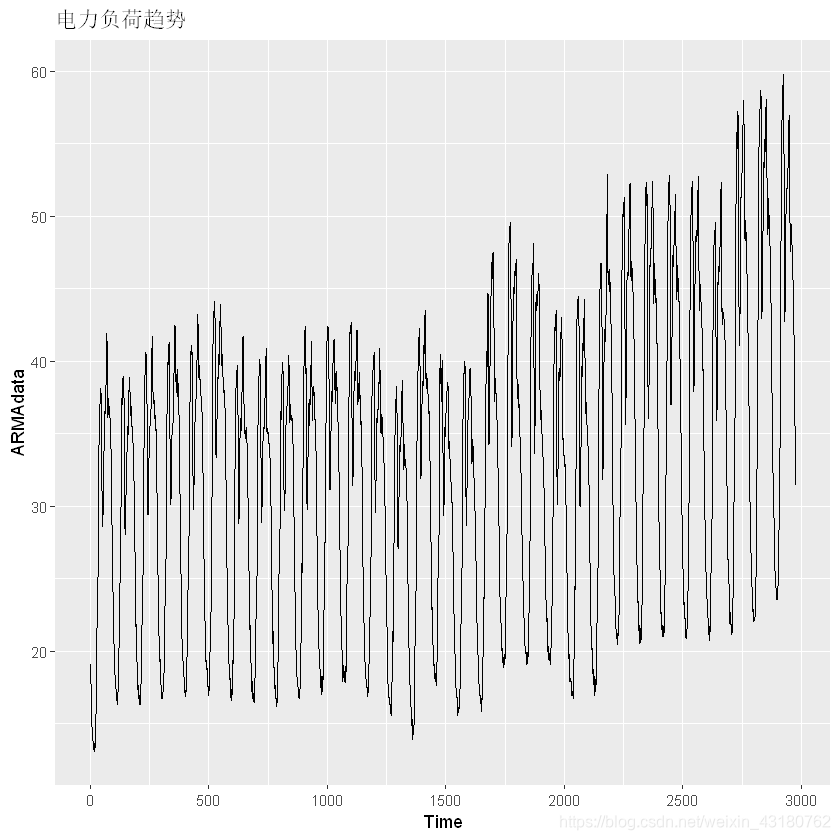
可发现,存在明显的周期性,同时也有一定的趋势性,可能和气候转暖,导致电器使用率提高导致用电较多
## 白噪声检验Box.test(ARMAdata,type ="Ljung-Box")
Box-Ljung testdata: ARMAdataX-squared = 2927.2, df = 1, p-value < 2.2e-16
p-value < 2.2e-16 说明该序列为非随机数据,可以进行预测分析
## 平稳性检验,单位根检验adf.test(ARMAdata)
Warning message in adf.test(ARMAdata):"p-value smaller than printed p-value"
Augmented Dickey-Fuller Test
data: ARMAdata
Dickey-Fuller = -8.9703, Lag order = 14, p-value = 0.01
alternative hypothesis: stationary
p-value = 0.01,说明数据是平稳的
## 分析序列的自相关系数和偏自相关系数确定参数p和q
p1 <- autoplot(acf(ARMAdata,lag.max =300,plot = F))+
ggtitle("序列自相关图")
p2 <- autoplot(pacf(ARMAdata,lag.max = 50,plot = F))+
ggtitle("序列偏自相关图")
gridExtra::grid.arrange(p1,p2,nrow=2)
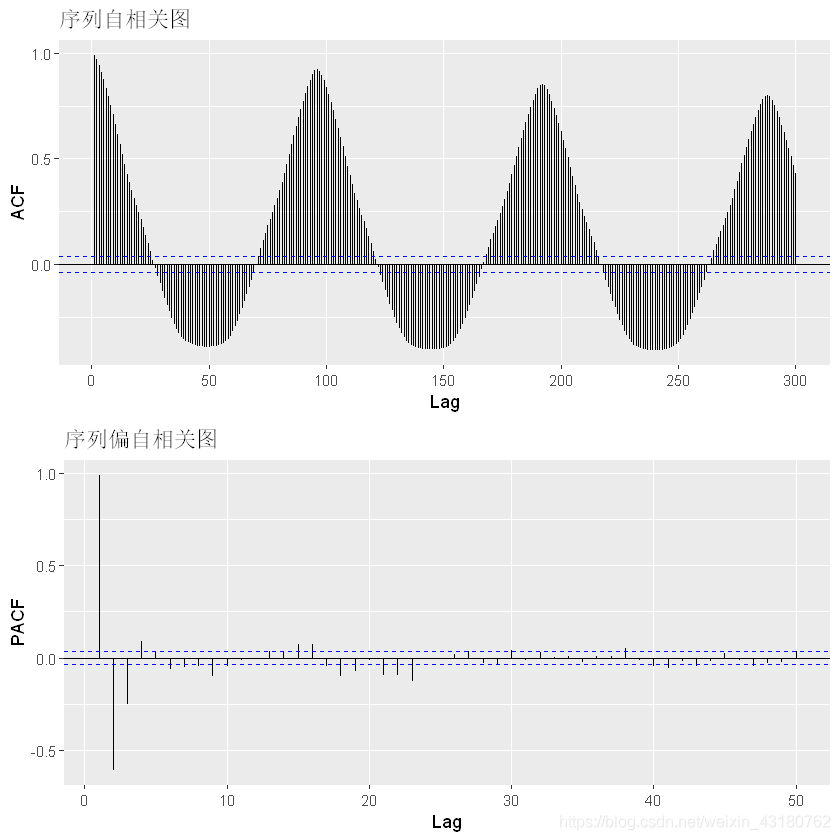
可发现,存在一定周期性,其中周期大概为96(即每天有多少记录),定阶不太熟,可用autoarima确定模型
## 偏自相关图3阶后截尾,可以认为p的取值为5左右,
## 通过观察自相关系数和偏自相关系数虽然可以确定p和q,但是这不是最好的方法,
## R提供了自动寻找序列合适的参数的函数
#利用函数自动定阶,确定合适的参数
auto.arima(ARMAdata)
Series: ARMAdata
ARIMA(1,1,2)
Coefficients:
ar1 ma1 ma2
0.5867 -0.0739 0.2721
s.e. 0.0285 0.0309 0.0218
sigma^2 estimated as 1.034: log likelihood=-4270.49
AIC=8548.98 AICc=8548.99 BIC=8572.97
## 可以发现较好的ARMA模型为ARIMA(1,1,2)
## 对数据建立ARIMA(1,1,2)模型,并预测后面的数据
ARMAmod <- arima(ARMAdata,order = c(1,1,2))
summary(ARMAmod)
Call:
arima(x = ARMAdata, order = c(1, 1, 2))
Coefficients:
ar1 ma1 ma2
0.5867 -0.0739 0.2721
s.e. 0.0285 0.0309 0.0218
sigma^2 estimated as 1.033: log likelihood = -4270.49, aic = 8548.98
Training set error measures:
ME RMSE MAE MPE MAPE MASE
Training set 0.001126811 1.01637 0.7583642 0.04113165 2.411178 0.7871583
ACF1
Training set -0.003829314
## 对拟合残差进行白噪声检验
Box.test(ARMAmod$residuals,type ="Ljung-Box")
Box-Ljung testdata: ARMAmod$residualsX-squared = 0.043683, df = 1, p-value = 0.8344
## p-value = 0.8344,说明是白噪声 信息提取完成,模型残差检验通过
## 可视化模型未来的预测值par(family = "STKaiti")plot(forecast(ARMAmod,h=500))
Warning message in title(main = main, xlab = xlab, ylab = ylab, ...):"Windows字体数据库里没有这样的字体系列"Warning message in axis(1, ...):"Windows字体数据库里没有这样的字体系列"Warning message in axis(2, ...):"Windows字体数据库里没有这样的字体系列"Warning message in axis(2, ...):"Windows字体数据库里没有这样的字体系列"Warning message in axis(2, ...):"Windows字体数据库里没有这样的字体系列"Warning message in axis(2, ...):"Windows字体数据库里没有这样的字体系列"Warning message in axis(2, ...):"Windows字体数据库里没有这样的字体系列"Warning message in axis(2, ...):"Windows字体数据库里没有这样的字体系列"Warning message in axis(2, ...):"Windows字体数据库里没有这样的字体系列"Warning message in axis(2, ...):"Windows字体数据库里没有这样的字体系列"Warning message in axis(2, ...):"Windows字体数据库里没有这样的字体系列"Warning message in axis(2, ...):"Windows字体数据库里没有这样的字体系列"Warning message in axis(2, ...):"Windows字体数据库里没有这样的字体系列"
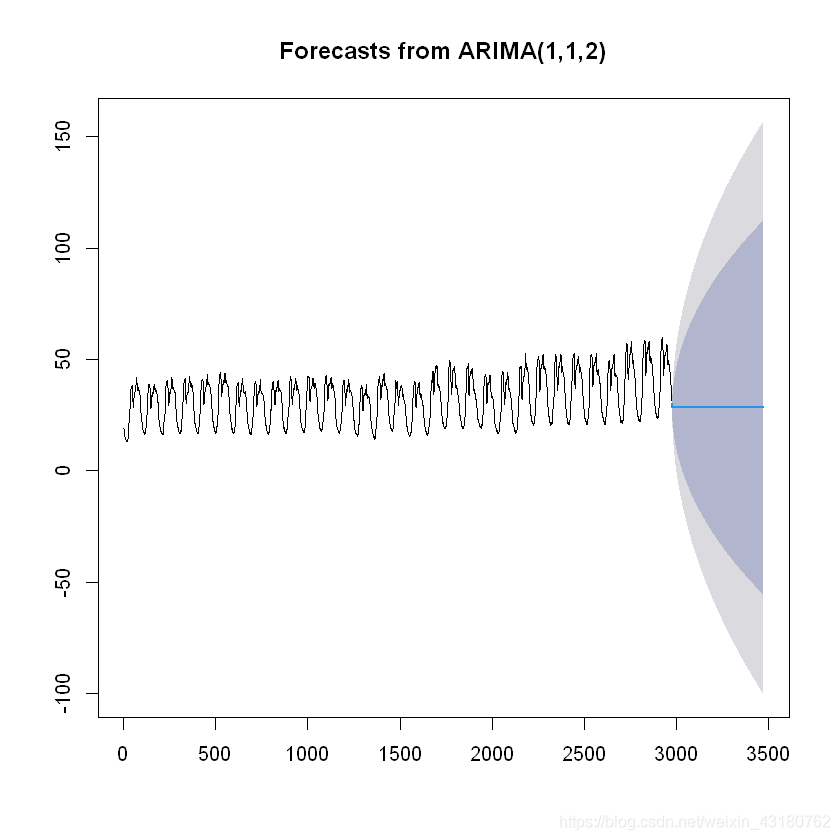
效果不好,体现不出季节性,故不选取推荐的模型,采取季节性ARIMA模型
季节ARIMA模型(划分测试集训练集)
## 可视化序列
autoplot(ARMAdata)+ggtitle("电力负荷趋势")
length(ARMAdata)
2976
## 将数据即切分位两个部分,一部分用于训练模型,一部分用于查看预测效果
AirPas_train <- ARMAdata[1:2400]
AirPas_test <- ARMAdata[2401:2976]
adf.test(AirPas_train)
Augmented Dickey-Fuller Test
data: AirPas_train
Dickey-Fuller = -9.0554, Lag order = 13, p-value = 0.01
alternative hypothesis: stationary
## p-value = 0.01,说明数据是平稳的
## 分析序列的自相关系数和偏自相关系数分析参数p和q
p1 <- autoplot(acf(AirPas_train,lag.max = 400,plot = F))+
ggtitle("序列自相关图")
p2 <- autoplot(pacf(AirPas_train,lag.max = 40,plot = F))+
ggtitle("序列偏自相关图")
gridExtra::grid.arrange(p1,p2,nrow=2)
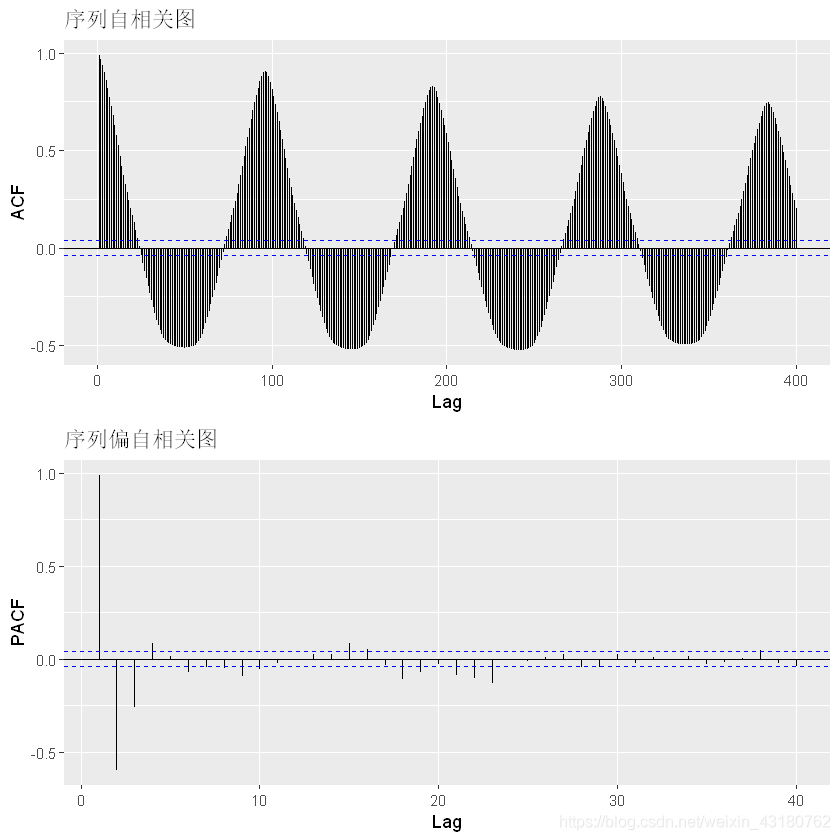
## 从自相关图和偏自相关图可以很明显的发现数据可能具有周期性,## 不能很好的确定参数p和q的取值,根据图可知,序列可能具有年周期性,周期为96## 使用auto.arima()函数确定模型的参数auto.arima(AirPas_train)#仅供参考,最后没用推荐的模型
Series: AirPas_train ARIMA(1,1,3) Coefficients: ar1 ma1 ma2 ma3 0.6696 -0.1713 0.2363 -0.0821s.e. 0.0507 0.0561 0.0296 0.0378sigma^2 estimated as 0.9471: log likelihood=-3337.17AIC=6684.35 AICc=6684.37 BIC=6713.26
#选取ARIMA(1,1,3)(0,1,0)[96] 模型ARIMA <- arima(AirPas_train, c(1, 1, 3), seasonal = list(order = c(0, 1, 0),period =96))summary(ARIMA)
Call:arima(x = AirPas_train, order = c(1, 1, 3), seasonal = list(order = c(0, 1, 0), period = 96))Coefficients: ar1 ma1 ma2 ma3 -0.350 -0.0117 -0.0333 -0.0587s.e. 0.158 0.1571 0.0608 0.0267sigma^2 estimated as 0.518: log likelihood = -2510.54, aic = 5031.07Training set error measures: ME RMSE MAE MPE MAPE MASETraining set -0.001661054 0.7050728 0.5206022 -0.01890399 1.760693 0.5634299 ACF1Training set -0.001149915
Box.test(ARIMA$residuals,type ="Ljung-Box")
Box-Ljung testdata: ARIMA$residualsX-squared = 0.00054543, df = 1, p-value = 0.9814
## p-value = 0.9814,此时,模型的残差已经是白噪声数据,数据中的信息已经充分的提取出来了
## 可视化模型的预测值和这是值之间的差距
par(family = "STKaiti")
plot(forecast(ARIMA,h=576),shadecols="oldstyle")
points(AirPas_train,col = "red")
lines(AirPas_train,col = "red")
#输出未来预测值,与测试集相比较,可得预测精度情况。
forecast(ARIMA,h=576)
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
2401 26.53587 25.61347540 27.45826 25.1251900 27.94655
2402 26.68160 25.58732655 27.77588 25.0080522 28.35515
2403 25.93017 24.64455145 27.21578 23.9639871 27.89635
2404 24.79712 23.38237500 26.21187 22.6334537 26.96079
2972 36.23935 -20.60310520 93.08181 -50.6936851 123.17239
2973 34.63735 -22.32372708 91.59843 -52.4771016 121.75181
2974 32.88335 -24.19610245 89.96281 -54.4121411 120.17885
2975 31.09935 -26.09823282 88.29694 -56.3768060 118.57551
2976 30.55535 -26.76011973 87.87083 -57.1010984 118.21181
#将预测结果转换为dataframe格式,便于提取fore<-as.data.frame(forecast(ARIMA,h=576))
#修改列名colnames(fore)<-c('fore','L80','H80','L95','H95')
#对测试集进行验证#测试集是最后6天的数据,训练集是前25天数据
library(e1071)library(caret)library(Metrics)library(readr)test_mape <- mape(fore$fore,AirPas_test)sprintf("测试集上的绝对值误差: %f",test_mape)
Warning message:"package 'e1071' was built under R version 4.0.4"Warning message:"package 'caret' was built under R version 4.0.4"Loading required package: latticeWarning message:"package 'Metrics' was built under R version 4.0.4"Attaching package: 'Metrics'
The following objects are masked from 'package:caret': precision, recall
The following object is masked from 'package:forecast':
accuracy
Warning message:
"package 'readr' was built under R version 4.0.4"
‘测试集上的绝对值误差: 0.046793’
测试集误差为4.67%,模型效果良好,故可选取该模型进行预测
#再预测未来一天,即4/1的情况如下(1天有96步)
forecast(ARIMA,h=672)
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
2401 26.53587 25.61347540 27.45826 25.1251900 27.94655
2402 26.68160 25.58732655 27.77588 25.0080522 28.35515
2403 25.93017 24.64455145 27.21578 23.9639871 27.89635
2404 24.79712 23.38237500 26.21187 22.6334537 26.96079
3069 34.94508 -35.74324936 105.63341 -73.1633900 143.05355
3070 33.19108 -37.62709810 104.00926 -75.1159765 141.49813
3071 31.40708 -39.54070920 102.35487 -77.0981996 139.91236
3072 30.86308 -40.21408394 101.94024 -77.8400612 139.56622
### 将预测结果转换为dataframe格式,便于提取
fore<-as.data.frame(forecast(ARIMA,h=672))
#修改列名
colnames(fore)<-c('fore','L80','H80','L95','H95')
#提取出最后的4/1的数据
data4_1<-fore[577:672,]
data4_1
<tr><th scope=row>3066</th><td>39.91908</td><td>-30.37826</td><td>110.2164</td><td>-67.59143</td><td>147.4296</td></tr>
<tr><th scope=row>3067</th><td>38.46808</td><td>-31.95983</td><td>108.8960</td><td>-69.24212</td><td>146.1783</td></tr>
<tr><th scope=row>3068</th><td>36.54708</td><td>-34.01116</td><td>107.1053</td><td>-71.36244</td><td>144.4566</td></tr>
<tr><th scope=row>3069</th><td>34.94508</td><td>-35.74325</td><td>105.6334</td><td>-73.16339</td><td>143.0535</td></tr>
<tr><th scope=row>3070</th><td>33.19108</td><td>-37.62710</td><td>104.0093</td><td>-75.11598</td><td>141.4981</td></tr>
<tr><th scope=row>3071</th><td>31.40708</td><td>-39.54071</td><td>102.3549</td><td>-77.09820</td><td>139.9124</td></tr>
<tr><th scope=row>3072</th><td>30.86308</td><td>-40.21408</td><td>101.9402</td><td>-77.84006</td><td>139.5662</td></tr>
| fore | L80 | H80 | L95 | H95 | |
|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| 2977 | 28.38222 | -29.11727 | 85.88172 | -59.55567 | 116.3201 |
| 2978 | 28.52796 | -29.12935 | 86.18526 | -59.65128 | 116.7072 |
聚类分析部分
指标数据在EXCEL中计算可得:
#导入数据
library(readxl)
dataclus<-read_excel("电力.xlsx",sheet=3)
#指标用EXCEL处理得到
dataclus<-as.data.frame(dataclus)rownames(dataclus)<-dataclus$时间
head(dataclus)
| 时间 | PAVE | PMIN | PMAX | K1 | K2 | K3 | TOTAL | |
|---|---|---|---|---|---|---|---|---|
| <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| 东城站10kV广源线F10有功值 | 东城站10kV广源线F10有功值 | 1.2967500 | 0.000 | 5.130 | 0.2527778 | 1.0000000 | 188.0667 | 3859.128 |
| 东城站10kV工业园甲线F09有功值 | 东城站10kV工业园甲线F09有功值 | 1.4396468 | 0.304 | 3.032 | 0.4748176 | 0.8997361 | 353.2643 | 4284.389 |
| 东城站10kV两报线F08有功值 | 东城站10kV两报线F08有功值 | 1.4852127 | 0.685 | 2.783 | 0.5336733 | 0.7538627 | 397.0529 | 4419.993 |
| 东城站10kV中惠甲线F07有功值 | 东城站10kV中惠甲线F07有功值 | 1.4884728 | 0.541 | 2.719 | 0.5474339 | 0.8010298 | 407.2908 | 4429.695 |
| 东城站10kV奕垌线F06有功值 | 东城站10kV奕垌线F06有功值 | 0.9472083 | 0.144 | 2.326 | 0.4072263 | 0.9380911 | 302.9764 | 2818.892 |
| 东城站10kV东城线F05有功值 | 东城站10kV东城线F05有功值 | 1.4619106 | 0.639 | 2.580 | 0.5666320 | 0.7523256 | 421.5742 | 4350.646 |
cludata<-dataclus[,c(5:7)]
library(RSNNS)## 数据max-min归一化到0-1之间cludata[,1:3] <- normalizeData(cludata[,1:3],"0_1")
Warning message:"package 'RSNNS' was built under R version 4.0.5"Loading required package: Rcpp
## 计算组内平方和 组间平方和
tot_withinss <- vector()
betweenss <- vector()
for(ii in 1:8){
k1 <- kmeans(cludata[,c(1:3)],ii)
tot_withinss[ii] <- k1$tot.withinss
betweenss[ii] <- k1$betweenss
}
kmeanvalue <- data.frame(kk = 1:8,
tot_withinss = tot_withinss,
betweenss = betweenss)
library(ggplot2)
library(gridExtra)
library(ggdendro)
library(cluster)
library(ggfortify)
p1 <- ggplot(kmeanvalue,aes(x = kk,y = tot_withinss))+
theme_bw()+
geom_point() + geom_line() +labs(y = "value") +
ggtitle("Total within-cluster sum of squares")+
theme(plot.title = element_text(hjust = 0.5))+
scale_x_continuous("kmean 聚类个数",kmeanvalue$kk)
p2 <- ggplot(kmeanvalue,aes(x = kk,y = betweenss))+
theme_bw()+
geom_point() +geom_line() +labs(y = "value") +
ggtitle("The between-cluster sum of squares") +
theme(plot.title = element_text(hjust = 0.5))+
scale_x_continuous("kmean 聚类个数",kmeanvalue$kk)
grid.arrange(p1,p2,nrow=2)
Warning message:"package 'ggplot2' was built under R version 4.0.4"Warning message:"package 'gridExtra' was built under R version 4.0.4"Warning message:"package 'ggdendro' was built under R version 4.0.4"Warning message:"package 'ggfortify' was built under R version 4.0.4"
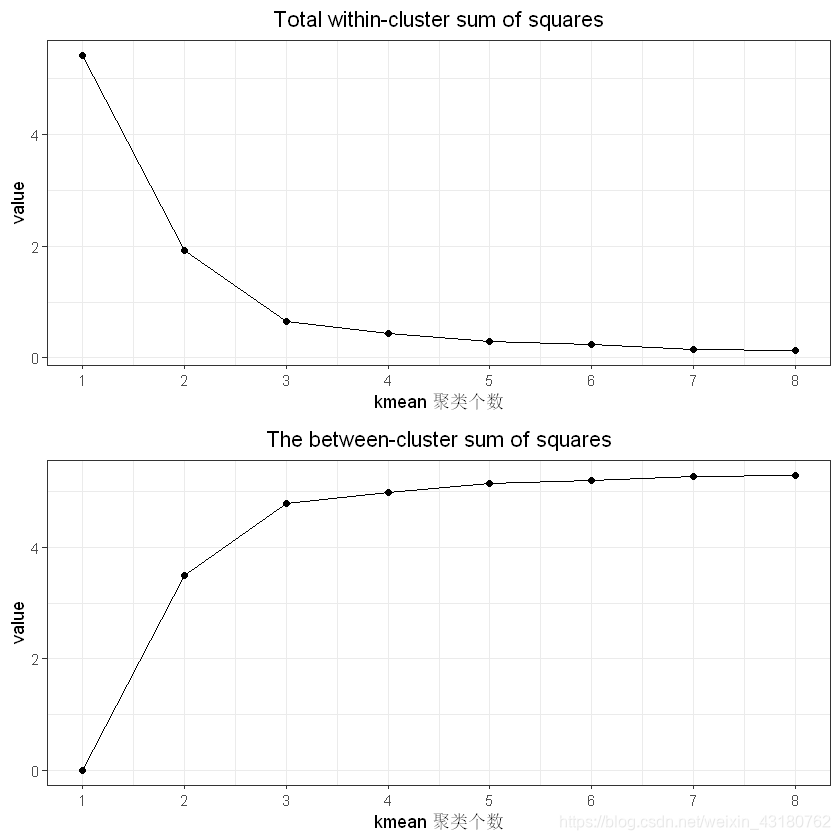
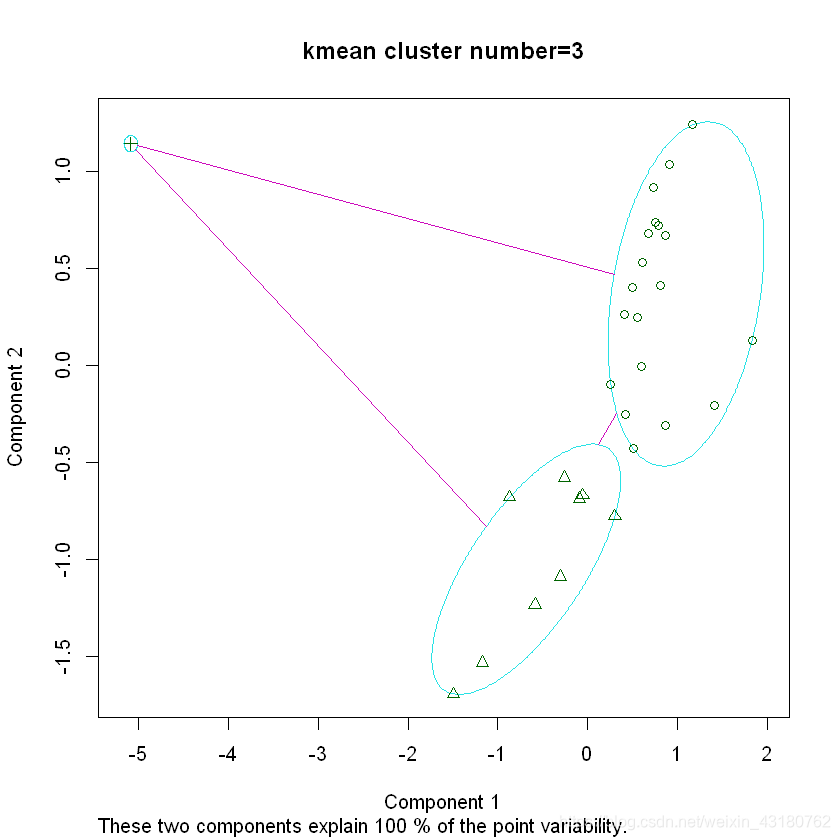
set.seed(245)k3 <- kmeans(cludata[,c(1:3)],3)summary(k3)
Length Class Mode cluster 30 -none- numericcenters 9 -none- numerictotss 1 -none- numericwithinss 3 -none- numerictot.withinss 1 -none- numericbetweenss 1 -none- numericsize 3 -none- numericiter 1 -none- numericifault 1 -none- numeric
## 对聚类结果可视化clusplot(cludata[,c(1:3)],k3$cluster,main = "kmean cluster number=3")
## 可视化轮廓图,表示聚类效果sis1 <- silhouette(k3$cluster,dist(cludata[,c(1:3)],method = "euclidean"))plot(sis1,main = " kmean silhouette", col = c("red", "green", "blue"))

#将标签写入
cludata$bzcluster<-k3$cluster
#标准化数据版本
cludata
| K1 | K2 | K3 | bzcluster | |
|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <int> | |
| 东城站10kV广源线F10有功值 | 0.3986848 | 1.0000000 | 0.3986848 | 2 |
| 东城站10kV工业园甲线F09有功值 | 0.7488892 | 0.8997361 | 0.7488892 | 1 |
| 东城站10kV两报线F08有功值 | 0.8417172 | 0.7538627 | 0.8417172 | 1 |
| 东城站10kV中惠甲线F07有功值 | 0.8634207 | 0.8010298 | 0.8634207 | 1 |
| 东城站10kV奕垌线F06有功值 | 0.6422832 | 0.9380911 | 0.6422832 | 2 |
| 东城站10kV东城线F05有功值 | 0.8937003 | 0.7523256 | 0.8937003 | 1 |
| 东城站10kV碧桂园甲线F04有功值 | 0.9282365 | 0.6783961 | 0.9282365 | 1 |
| 东城站10kV县府线F03有功值 | 0.8807823 | 0.7262639 | 0.8807823 | 1 |
| 东城站10kV工业园乙线F11有功值 | 0.7496690 | 0.9485219 | 0.7496690 | 1 |
| 东城站10kV工业南线F12有功值 | 0.6354980 | 0.9377328 | 0.6354980 | 2 |
| 东城站10kV喜之郎甲线F13有功值 | 0.8147030 | 0.9619663 | 0.8147030 | 1 |
| 东城站10kV喜之郎乙线F14有功值 | 1.0000000 | 0.9737654 | 1.0000000 | 1 |
| 东城站10kV丹载线F15有功值 | 0.0000000 | 0.0000000 | 0.0000000 | 3 |
| 东城站10kV永民线F16有功值 | 0.6166640 | 0.8958105 | 0.6166640 | 2 |
| 东城站10kV兴中线F17有功值 | 0.7362025 | 0.8496281 | 0.7362025 | 1 |
| 东城站10KV龙日线F18有功值 | 0.5142506 | 0.8512881 | 0.5142506 | 2 |
| 东城站10kV碧桂园乙线F19有功值 | 0.9850771 | 0.6629902 | 0.9850771 | 1 |
| 东城站10kV石仑线F20有功值 | 0.8110076 | 0.8084220 | 0.8110076 | 1 |
| 东城站10KV东泰线F32有功值 | 0.8136237 | 0.7685460 | 0.8136237 | 1 |
| 东城站10kV环山线F31有功值 | 0.7980173 | 0.8675737 | 0.7980173 | 1 |
| 东城站10kV东供线F21有功值 | 0.5690338 | 1.0000000 | 0.5690338 | 2 |
| 东城站10kV中惠乙线F22有功值 | 0.8914599 | 0.6840640 | 0.8914599 | 1 |
| 东城站10kV佰利线F30有功值 | 0.8843735 | 0.7326007 | 0.8843735 | 1 |
| 东城站10kV东轩线F29有功值 | 0.8633316 | 0.7284010 | 0.8633316 | 1 |
| 东城站10kV大道线F28有功值 | 0.9083081 | 1.0000000 | 0.9083081 | 1 |
| 东城站10kV华科乙线F27有功值 | 0.5140382 | 1.0000000 | 0.5140382 | 2 |
| 东城站10kV华科甲线F26有功值 | 0.3354361 | 1.0000000 | 0.3354361 | 2 |
| 东城站10kV金桂线F25有功值 | 0.7886029 | 0.7896907 | 0.7886029 | 1 |
| 东城站10kV福兴线F24有功值 | 0.6894732 | 1.0000000 | 0.6894732 | 2 |
| 东城站10kV龙塘线F23有功值 | 0.0000000 | 0.0000000 | 0.0000000 | 3 |
aggregate(cludata[,c(1:3)],list(cludata$bzcluster),mean)
| Group.1 | K1 | K2 | K3 |
|---|---|---|---|
| <int> | <dbl> | <dbl> | <dbl> |
| 1 | 0.8526907 | 0.8098834 | 0.8526907 |
| 2 | 0.5461513 | 0.9581025 | 0.5461513 |
| 3 | 0.0000000 | 0.0000000 | 0.0000000 |
#将标签写入(原始数据版本)dataclus$bzcluster<-k3$cluster
dataclus
<tr><th scope=row>东城站10kV碧桂园甲线F04有功值</th><td>东城站10kV碧桂园甲线F04有功值</td><td>0.7191825</td><td>0.393</td><td>1.222</td><td>0.5885290</td><td>0.6783961</td><td>437.8656</td><td>2140.287</td><td>1</td></tr>
<tr><th scope=row>东城站10kV县府线F03有功值</th><td>东城站10kV县府线F03有功值 </td><td>1.8115847</td><td>0.888</td><td>3.244</td><td>0.5584416</td><td>0.7262639</td><td>415.4806</td><td>5391.276</td><td>1</td></tr>
<tr><th scope=row>东城站10kV工业园乙线F11有功值</th><td>东城站10kV工业园乙线F11有功值</td><td>0.9325622</td><td>0.101</td><td>1.962</td><td>0.4753120</td><td>0.9485219</td><td>353.6321</td><td>2775.305</td><td>1</td></tr>
<tr><th scope=row>东城站10kV工业南线F12有功值</th><td>东城站10kV工业南线F12有功值 </td><td>2.2712839</td><td>0.351</td><td>5.637</td><td>0.4029242</td><td>0.9377328</td><td>299.7756</td><td>6759.341</td><td>2</td></tr>
<tr><th scope=row>东城站10kV喜之郎甲线F13有功值</th><td>东城站10kV喜之郎甲线F13有功值</td><td>1.4396122</td><td>0.106</td><td>2.787</td><td>0.5165455</td><td>0.9619663</td><td>384.3098</td><td>4284.286</td><td>1</td></tr>
<tr><th scope=row>东城站10kV福兴线F24有功值</th><td>东城站10kV福兴线F24有功值 </td><td>1.3485958</td><td>0.000</td><td>3.085</td><td>0.4371461</td><td>1.0000000</td><td>325.2367</td><td>4013.421</td><td>2</td></tr>
<tr><th scope=row>东城站10kV龙塘线F23有功值</th><td>东城站10kV龙塘线F23有功值 </td><td>0.0000000</td><td>0.000</td><td>0.000</td><td>0.0000000</td><td>0.0000000</td><td> 0.0000</td><td> 0.000</td><td>3</td></tr>
| 时间 | PAVE | PMIN | PMAX | K1 | K2 | K3 | TOTAL | bzcluster | |
|---|---|---|---|---|---|---|---|---|---|
| <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <int> | |
| 东城站10kV广源线F10有功值 | 东城站10kV广源线F10有功值 | 1.2967500 | 0.000 | 5.130 | 0.2527778 | 1.0000000 | 188.0667 | 3859.128 | 2 |
| 东城站10kV工业园甲线F09有功值 | 东城站10kV工业园甲线F09有功值 | 1.4396468 | 0.304 | 3.032 | 0.4748176 | 0.8997361 | 353.2643 | 4284.389 | 1 |
| 东城站10kV两报线F08有功值 | 东城站10kV两报线F08有功值 | 1.4852127 | 0.685 | 2.783 | 0.5336733 | 0.7538627 | 397.0529 | 4419.993 | 1 |
#各类比分类统计平均值,得到不同类别之间的差异
aggregate(dataclus[,c(5:8)],list(dataclus$bzcluster),mean)
| Group.1 | K1 | K2 | K3 | TOTAL |
|---|---|---|---|---|
| <int> | <dbl> | <dbl> | <dbl> | <dbl> |
| 1 | 0.5406307 | 0.8098834 | 402.2293 | 3361.270 |
| 2 | 0.3462759 | 0.9581025 | 257.6292 | 3786.549 |
| 3 | 0.0000000 | 0.0000000 | 0.0000 | 0.000 |

















 2724
2724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









