







【coze】故事卡片(图片、音频、文字)
1、创建智能体
从左侧找到工作空间,切换为个人空间,点击右上角创建
![[图片]](https://i-blog.csdnimg.cn/direct/be06e5a8dec144739cdf31573b3dbd16.png)
选择智能体进行创建
![[图片]](https://i-blog.csdnimg.cn/direct/7cb889e79cb941b2a10908a3004c54e4.png)
智能体名称:故事卡片生成
智能体功能介绍:根据提示词生成带图片、音频、文字的故事小卡片
![[图片]](https://i-blog.csdnimg.cn/direct/1a6b3879fccc4b36bd861a89d2ac4dee.png)
2、添加人设与回复逻辑
## 角色
你是一个音频故事生成助手,你可以按照用户的要求,生成最终的内容,你工作时请注意:
## 要求
1、生成故事文字,不低于100字,不超过200字,并将故事的文字进行输出
2、用故事文字生成音频,将音频文件原始链接输出,不需要输出成可点击的文字链接
#3、给故事的每一个场景生成图片,将图片输出,整个故事不超过3张图片,图片风格全部采用迪士尼风格
## 工具使用
你在完成用户任务的过程中可以使用story工作流
![[图片]](https://i-blog.csdnimg.cn/direct/cffb46d66ad04274aae0e60390b7a1b9.png)
3、添加工作流
(1)创建工作流
![[图片]](https://i-blog.csdnimg.cn/direct/6fdc5b4b667346c6995863ecfd78f41c.png)
工作流名称:story
工作流描述:故事生成工作流
![[图片]](https://i-blog.csdnimg.cn/direct/5cfad6bcf0794cc387683f1da1031875.png)
(2)添加大模型节点
![[图片]](https://i-blog.csdnimg.cn/direct/6f0276558867446881a6449b526908f7.png)
将大模型和开始节点相连
![[图片]](https://i-blog.csdnimg.cn/direct/0f500ac378644659a1bf07a094c37fb2.png)
配置模型为DeepSeek-V3
![[图片]](https://i-blog.csdnimg.cn/direct/256cee4b0fa34909b6fbdb80b698aa75.png)
大模型输入为开始节点的input
![[图片]](https://i-blog.csdnimg.cn/direct/228ef4cd0269427aab758f0fbfcd9260.png)
系统提示词如下:
你在完成用户任务的过程中可以输出以下内容:
1、故事内容story
2、故事配图提示词picture
![[图片]](https://i-blog.csdnimg.cn/direct/69a046cf805b4a43b1c32ea01c14f834.png)
用户提示词为:{{input}}
![[图片]](https://i-blog.csdnimg.cn/direct/69d243cec2294350a4a57649a6ff29fe.png)
添加两个输出变量,分别为story和picture
![****[图片]****](https://i-blog.csdnimg.cn/direct/841eaa560693466e9125d90cfaedc3be.png)
(3)添加提示词优化节点
为了让图片生成的效果更好,通常需要添加提示词优化
![[图片]](https://i-blog.csdnimg.cn/direct/718512e2d3e04e6cb19aeb64aff49719.png)
将大模型与提示词优化节点相连
![[图片]](https://i-blog.csdnimg.cn/direct/27317a22c2e147e780c0e1529a5a9840.png)
设置提示词为大模型节点的picture
![[图片]](https://i-blog.csdnimg.cn/direct/556f3cfb77104559a13923ba4a8ee3b0.png)
(4)添加豆包图像生成
![[图片]](https://i-blog.csdnimg.cn/direct/eebd51d8204e4a3490b7be118f67e04e.png)
搜索豆包图像生成,找到gen_image点击添加
![[图片]](https://i-blog.csdnimg.cn/direct/57c6dde5bb184b1e8af6693779f94f4a.png)
将图像生成节点和提示词优化节点相连
![[图片]](https://i-blog.csdnimg.cn/direct/fdf60a583b33400f81ccc3aef1ba47cd.png)
图像生成节点的prompt为提示词优化节点的data
![[图片]](https://i-blog.csdnimg.cn/direct/6b78775a270f4ceb846f938721e1fc9d.png)
req_schedule_conf为固定值general_v20_9B_pe
![[图片]](https://i-blog.csdnimg.cn/direct/b5d6954a6bab479a9de0094f1936fdb2.png)
(5)添加语音朗读插件
![[图片]](https://i-blog.csdnimg.cn/direct/94b50f1992284c0d8e0d2b582f5aae37.png)
搜索语音合成,点击添加
![[图片]](https://i-blog.csdnimg.cn/direct/6cce89353522415eac836afecebfd540.png)
将语音合成和大模型相连
![[图片]](https://i-blog.csdnimg.cn/direct/d6fae988de0c40a6b85ff0b36a5a5b79.png)
配置语音合成的text为大模型的story
![[图片]](https://i-blog.csdnimg.cn/direct/8f1c85054fad4aefb2762325544d5aa4.png)
speaker_id为爽快思思/Skye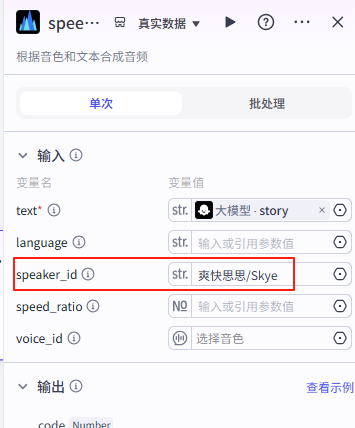
(6)添加输出节点
![[图片]](https://i-blog.csdnimg.cn/direct/f6814f8f78224e6c8ea696eb5c2c61be.png)
连接输出节点
![[图片]](https://i-blog.csdnimg.cn/direct/43824801453c43d9a40ea1092de89b8d.png)
添加输出节点参数,分别是story、picture、audio
![[图片]](https://i-blog.csdnimg.cn/direct/717849f1f735406abdf0598dee3c0c16.png)
设置story参数为大模型节点的story
![[图片]](https://i-blog.csdnimg.cn/direct/531c44dddb5e4daa9c928b1824fe1d8c.png)
设置picture参数为图片合成节点的image_urls
![[图片]](https://i-blog.csdnimg.cn/direct/f38393981e2c43c5a25b08bc25b07409.png)
设置audio参数为语音朗读节点的link
![[图片]](https://i-blog.csdnimg.cn/direct/d397f0b4f4e9469c9100f6a00e7d359d.png)
(7)结束节点设置
将输出节点与结束节点相连
![[图片]](https://i-blog.csdnimg.cn/direct/669fb241d42f4c6399da2f9960eace62.png)
删掉结束节点的输出,这里不需要输出内容
![[图片]](https://i-blog.csdnimg.cn/direct/97f1289b19c248888704293959b45b4b.png)
(8)工作流试运行
![[图片]](https://i-blog.csdnimg.cn/direct/86c760b2a3514c92b3b186e902e92261.png)
输入讲个故事,点击试运行
![[图片]](https://i-blog.csdnimg.cn/direct/9b1ee5d1161f4ceb8da69b024587ba6b.png)
我们可以看到,输出节点三个参数均有数据,如果显示失败,重新试运行即可
![[图片]](https://i-blog.csdnimg.cn/direct/1643c47bda0e42cab2a6ff9c3f63b542.png)
(9)发布并添加工作流
![[图片]](https://i-blog.csdnimg.cn/direct/5339f194eac24a6dad03677cee555b63.png)
版本描述就写工作流的描述就行:故事生成工作流
然后点击发布
![[图片]](https://i-blog.csdnimg.cn/direct/600b2bd9e0414148b7b22ee172b624df.png)
发布完成后,会弹窗提醒是否添加至智能体,点击确认
![[图片]](https://i-blog.csdnimg.cn/direct/d95082768d6e4858b8b1aa14b5edd1c5.png)
如果上一步不小心把弹窗关了,也可以手动添加刚刚创建的工作流
![[图片]](https://i-blog.csdnimg.cn/direct/20489c71c2034bf08c1c2750dd89b717.png)
![[图片]](https://i-blog.csdnimg.cn/direct/8be423d6317949d69dd49be54e1b57a0.png)
4、卡片设计
(1)新增卡片
在工作流上,点击绑定卡片数据
![[图片]](https://i-blog.csdnimg.cn/direct/f867e4dabdaa44b99f5f85f539f717c8.png)
选择输出下面的绑定卡片
![[图片]](https://i-blog.csdnimg.cn/direct/bf1f35bba73a4d5ab69ec8afc0b7dbb7.png)
新增一个卡片
![[图片]](https://i-blog.csdnimg.cn/direct/d4da3625a46a47218ea0caa6b6427090.png)
(2)设置图片
在组件中,找到图片控件,拖拽进编辑区
![[图片]](https://i-blog.csdnimg.cn/direct/ff0922fe63a04a5f93eae9e6c696bd1d.png)
点击图片区域,一定要点击图片,不要点击外框
![[图片]](https://i-blog.csdnimg.cn/direct/bc82f6b8ff45411e884acf12a67fb7c5.png)
设置图片为宽度铺满模式
![[图片]](https://i-blog.csdnimg.cn/direct/010bb7088dc94ff3a6c0db1cc9d19a26.png)
点击(x)图标,点击新建变量
![[图片]](https://i-blog.csdnimg.cn/direct/b32e4ec9b1014e38ae460792aa8514b0.png)
变量名:picture
默认值可以随便写,也可以设置系统默认图标链接
https://lf-card-builder.oceancloudapi.com/obj/bot-studio-builder/4004860678112580_1706003508909477605.png
![[图片]](https://i-blog.csdnimg.cn/direct/57737af67fe046a285a7fc018abc8d87.png)
再次点击(x)图标,绑定刚刚新建的picture变量
![[图片]](https://i-blog.csdnimg.cn/direct/5eb9463bd7604b6095a4536975dbea65.png)
(3)设置音频
在组件中,找到音频,拖拽进编辑区
![[图片]](https://i-blog.csdnimg.cn/direct/c2cf3178a50e4b88aab59aead5ac81bf.png)
在左侧选择变量,点击新建变量
![[图片]](https://i-blog.csdnimg.cn/direct/8c3450771c3a42be84ba2940fe1377ba.png)
变量名称:audio
变量默认值:随便写即可,我这里写了个mp3
![[图片]](https://i-blog.csdnimg.cn/direct/27c763a035c64f139fbcc5e3e27b1217.png)
点击音频播放条,选择变量,选择刚刚新建的audio变量
![[图片]](https://i-blog.csdnimg.cn/direct/0f4e72194bdd4e1babe8c95e979b84ca.png)
(4)设置故事文字内容
再新建一个变量
![[图片]](https://i-blog.csdnimg.cn/direct/a9a58c0da5e141b59eec62cc7ab97c9d.png)
变量名:story
变量默认值:随便敲个空格即可
![[图片]](https://i-blog.csdnimg.cn/direct/fe6df63787834f83b1c9dfea0e5aa426.png)
将文本组件拖拽进工作区
![[图片]](https://i-blog.csdnimg.cn/direct/96e7b8727d0d4587b0d1bd3e8b7572ae.png)
点击文本组件,点击右上角的(x)图标
![[图片]](https://i-blog.csdnimg.cn/direct/32af9b26857b43d8b31428bc68baacb5.png)
选择story变量
![[图片]](https://i-blog.csdnimg.cn/direct/ee92ee6339874c2d81ac5005be5397bd.png)
(5)卡片命名及发布
给卡片起个名字:故事小卡片
![[图片]](https://i-blog.csdnimg.cn/direct/a2461b9a68f74324964c62265e6da971.png)
点击右上角发布
![[图片]](https://i-blog.csdnimg.cn/direct/87249517cc2f4eb4b4de9c5bc4a882ef.png)
点击确定即可
![[图片]](https://i-blog.csdnimg.cn/direct/7564f3f9f5104001a5a0507a5ee69f8e.png)
(6)绑定数据
单击故事小卡片,把story、audio、picture按如下图所示进行配置,配置完成点击确认
![[图片]](https://i-blog.csdnimg.cn/direct/d74c7ed10cb6436da990fbc1fa7039db.png)
5、模型选择和设置
智能体支持多种大语言模型,点击下拉菜单,选择自己喜欢的大模型作为引擎进行回复。当然也可以添加多个模型,进行“模型对比调试”
![[图片]](https://i-blog.csdnimg.cn/direct/71a97c9de5fc4dd08f3e52a4519ce5dd.png)
这里我选择“DeepSeek-V3”模型。
![[图片]](https://i-blog.csdnimg.cn/direct/838337b7ef9e4f6eadfdfebb5d6ad68e.png)
6、测试智能体
测试之前,先优化一下提示词
把提示词中的story删掉,输入{会自动弹出窗口,添加story工作流
![[图片]](https://i-blog.csdnimg.cn/direct/50eee58076d0466f96b6d277028ff1c2.png)
添加完后如下图所示,这样做的目的是让系统更稳定的调用工作流
![[图片]](https://i-blog.csdnimg.cn/direct/ead2f676cf1145e9a56384d5d34bf42c.png)
发送测试问题:最近有什么节日,写一个故事给4岁小女孩
![[图片]](https://i-blog.csdnimg.cn/direct/0fc356351fe14a318ac12a300b081af6.png)
点击运行完毕图标,可以查看插件调用详细信息
![[图片]](https://i-blog.csdnimg.cn/direct/1efa6fa0565d452e89c8085bcace2408.png)
![[图片]](https://i-blog.csdnimg.cn/direct/c2bf9487f55e4a08bf5fc08136f6feff.png)
7、发布智能体
![[图片]](https://i-blog.csdnimg.cn/direct/58f73531c20d4c19a8a544415d010811.png)
默认为coze商店发布,如果有其他需求自行勾选
![[图片]](https://i-blog.csdnimg.cn/direct/23cc14a78df74bcc814102fe1c878cca.png)
发布成功可以对话,也可以复制链接发给别人
![[图片]](https://i-blog.csdnimg.cn/direct/811bb2ccfc684509a1df44e5f91eedf3.png)


















 133
133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}