







卷积神经网络(CNN)基础
卷积神经网络(CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,它仿造生物的视觉神经元机制构建,能够进行监督学习和非监督学习,是深度学习网络的代表之一。卷积神经网络具有特征学习能力,能够按其阶层结构对输入信息进行平移不变分类,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的参数来进行特征处理。
一个卷积神经网络主要由以下5种结构组成:
输入层:输入层是整个神经网络的输入,在处理图像的卷积神经网络中,它一般代表了一张图片的像素矩阵。
卷积层:卷积层试图将神经网络中的每一个小块进行更加深入的分析从而得到抽象程度更高的特征。
池化层:池化操作可以认为是将一张分辨率较高的图片转化为分辨率较低的图片。通过池化层,可以进一步缩小最后全连接层中节点的个数,从而达到减少整个神经网络中的参数的目的。
线性整流层(激活层):激活层把卷积、池化层的输出结果做非线性映射。卷积神经网络采用的激活函数一般为ReLU,它的特点是收敛快,求取梯度较为简单。
全连接层:全连接层在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的特征映射到样本标记空间的作用。
图片检索系统设计与实现
图片检索系统结构共分为三部分,第一部分为网络训练部分,第二部分为特征提取部分,第三部分则是特征对比结果输出部分。以上三部分实现步骤如下图所示。

基于AlexNet的图像检索
AlexNet网络结构在整体上类似于LeNet,都是先卷积然后再全连接,但与LeNet相比,AlexNet更为复杂。AlexNet使用了GPU进行运算加速,并在卷积神经网络中成功应用了ReLU、dropout和LRN等结构。总的来说,AlexNet网络包括5个卷积层和3个全连接层,在每一个卷积层中包含了激活函数RELU以及局部响应归一化(LRN)处理,然后再经过下采样(pool处理)。AlexNet网络结构如图所示。
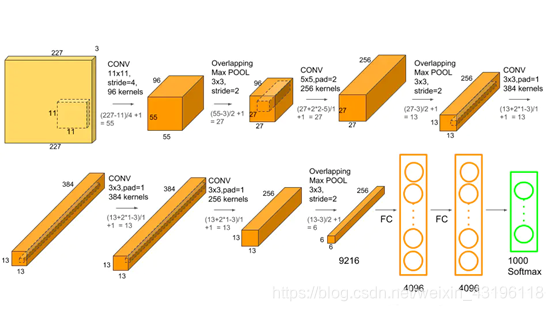
使用Keras实现AlexNet网络架构,源码如下。
# AlexNet网络结构
model = Sequential()
model.add(Conv2D(96, (11, 11), strides=(4, 4),
input_shape=(227, 227, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Conv2D(256, (5, 5), strides=(1, 1), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000, activation='softmax'))
sgd = optimizers.Adam(lr=0.00001)
model.compile(loss='sparse_categorical_crossentropy',
optimizer=sgd, metrics=['accuracy'])
在AlexNet网络训练结束并生成alexModel.h5模型后,使用命令
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1345
1345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









