






Huggingface国内开源镜像
https://hf-mirror.com/
上面总结了多种从Huggingface上下载模型的方法,如下图。
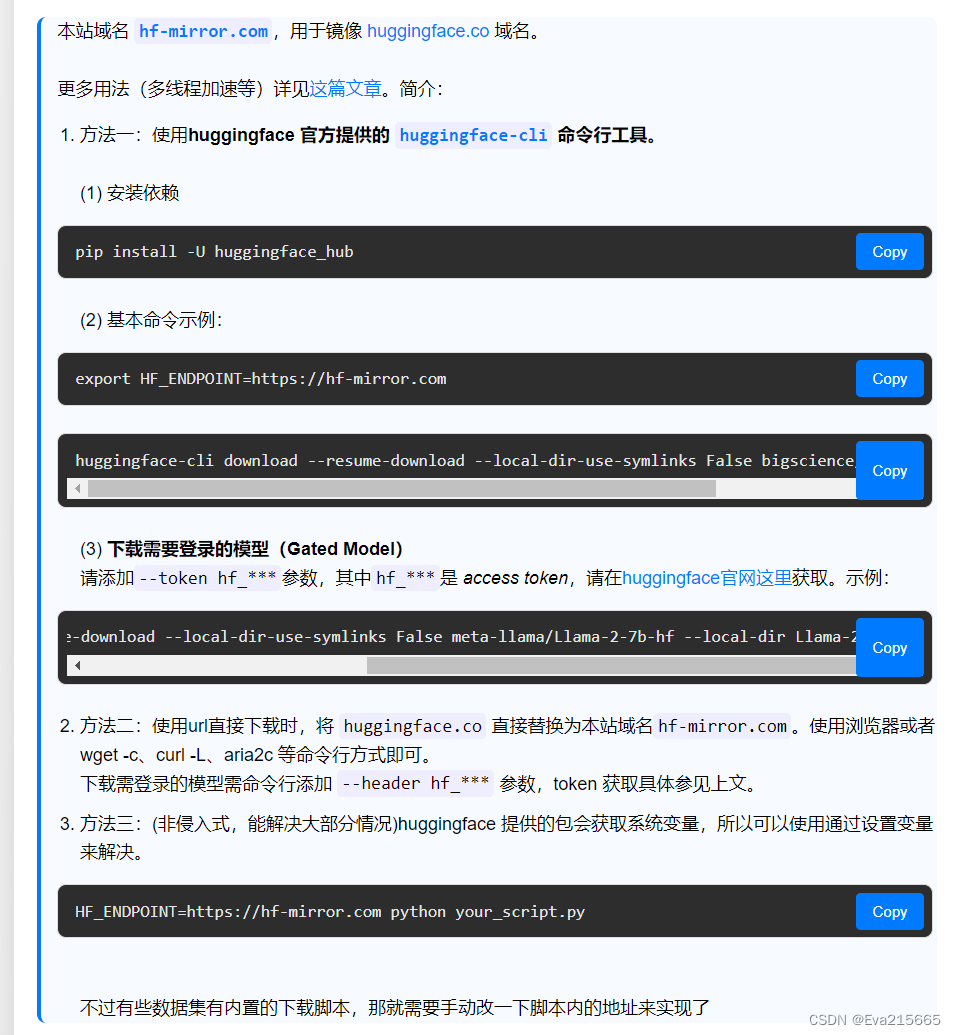
方法一:使用huggingface官网提供的huggingface-cli工具
官方详解地址https://huggingface.co/docs/huggingface_hub/guides/download
1. 安装依赖
创建项目的虚拟环境后,激活该环境,并执行:
pip install -U huggingface_hub
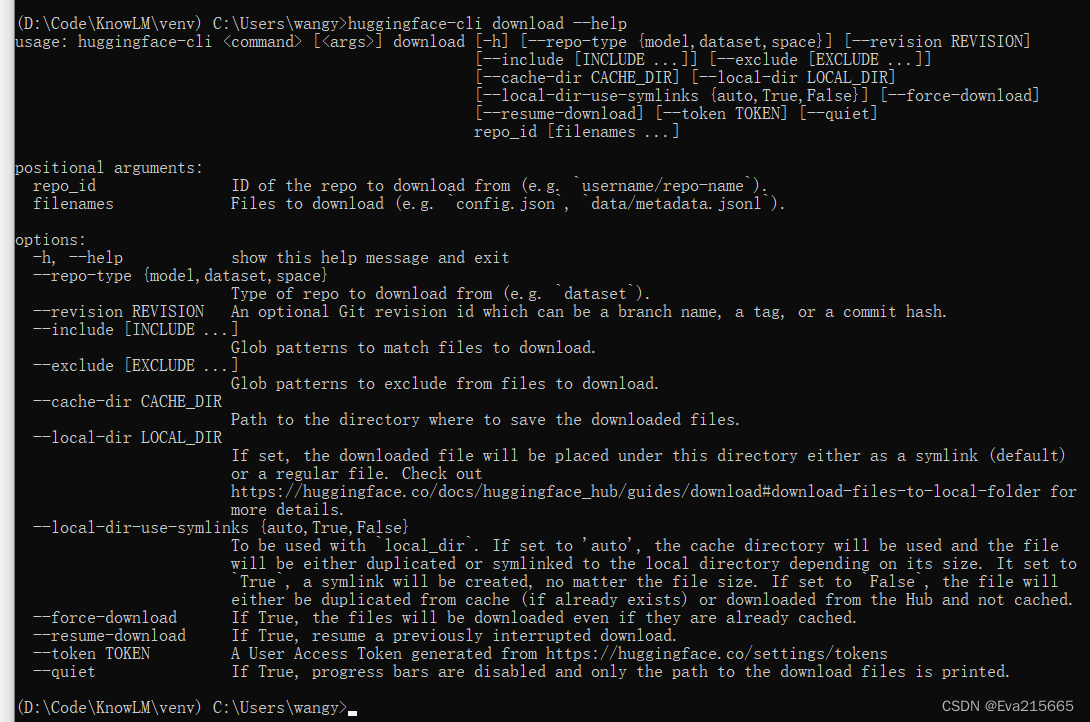
可以运行huggingface-cli download --helps命令来查看download功能的参数,如下图
以下载zjunlp/knowlm-13b-ie模型为例,模型地址:https://huggingface.co/zjunlp/knowlm-13b-ie/tree/main,运行以下命令
huggingface-cli download --resume-download --local-dir-use-symlinks False zjunlp/knowlm-13b-ie --local-dir D:\Code\KnowLM\knowlm-13b-ie
或者以下命令
huggingface-cli download --resume-download zjunlp/knowlm-13b-ie --local-dir D:\Code\KnowLM\knowlm-13b-ie --local-dir-use-symlinks False --token hf_*****
这条命令会将zjunlp/knowlm-13b-ie模型下载到本地的D:\Code\KnowLM\test路径下
支持多线程下载,如图

比直接从项目地址网页https://huggingface.co/zjunlp/knowlm-13b-ie/tree/main下载方便快捷得多!
方法一本质上还是从huggingface官网上下载,因此需要科学上网。
2. 基本命令示例
export HF_ENDPOINT=https://hf-mirror.com
3. 下载需要登录的模型
方法二:从镜像网站下载
方法二的本质是从huggingface的国内开源镜像下载,需要关闭科学上网才能达到理想的速度
1. 直接从镜像网站手动下载
在搜素栏里搜索想要的模型,例如knowlm-13b-ie,确定以后会转到相应的镜像网站
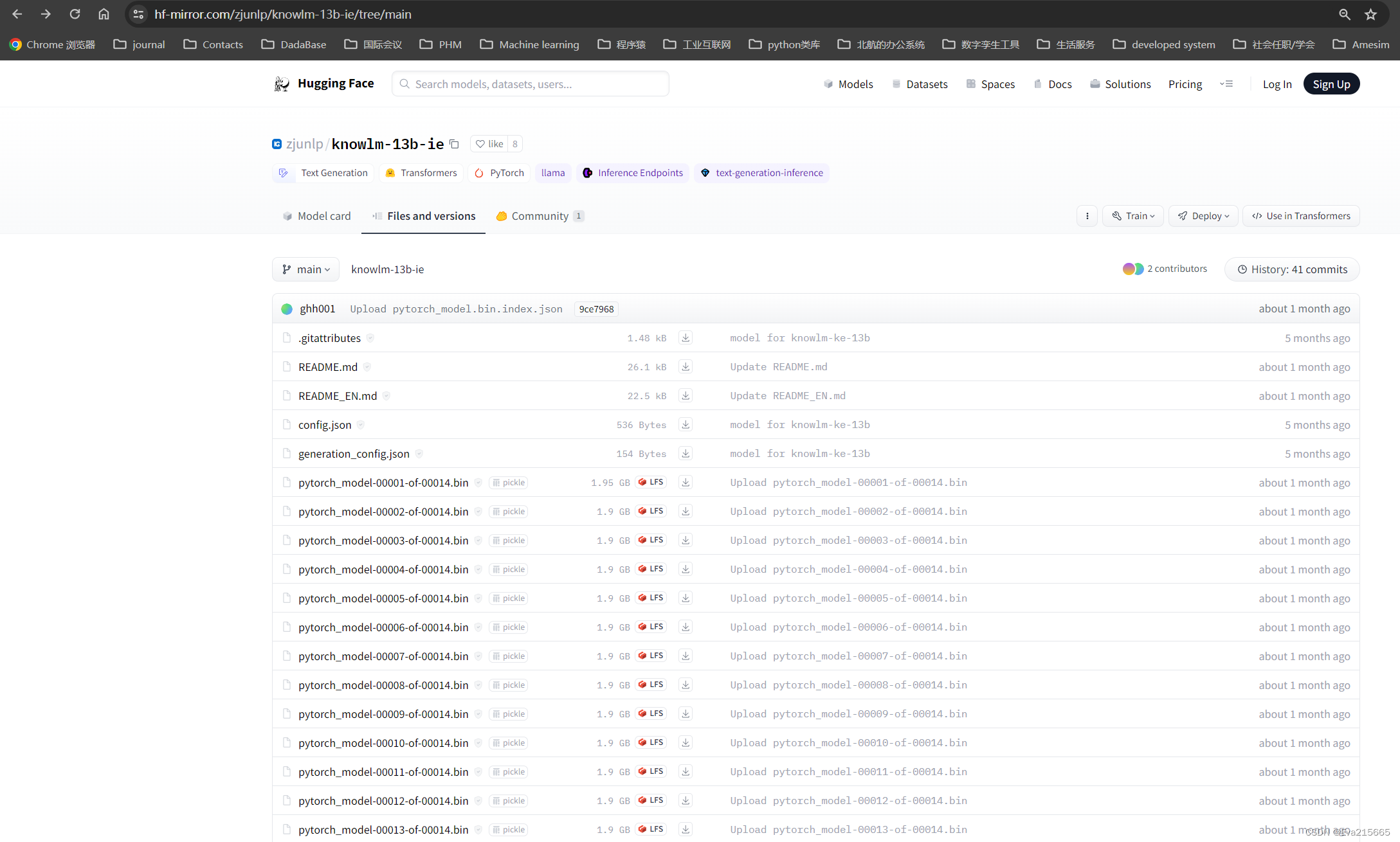
结构目录和huggingface上一样,只是域名已经变成了https://hf-mirror.com/zjunlp/knowlm-13b-ie/tree/main
仍然可以手动使用浏览器下载每个文件,速度可达1.5MB/s,巅峰时可6-7MB/s且不中断!,困扰快一周的问题终于解决
2. 用wget等工具下载
例如想要下载openvla-7b模型到本地,从hugging face镜像网站https://hf-mirror.com上下载
(1)安装工具huggingface-cli
pip install -U huggingface_hub
(2)创建python脚本
import os
// 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
// 下载模型
os.system('huggingface-cli download --resume-download HF上的模型名称 --local-dir 本地存放路径')
// 下载数据集
os.system('huggingface-cli download --repo-type dataset --resume-download HF上的数据集名称 --local-dir 本地存放路径')
例如,我只想下载openvla-7b这个模型,脚本如下
import os
# // 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# // 下载模型
os.system('huggingface-cli download --resume-download openvla/openvla-7b --local-dir /root/openvla/openvla7b')

















 1242
1242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









