






本文以LinkedList的源码为基础来详解双向链表的建立和移除元素。
双向链表要求一个节点不仅能指向它的后继节点,还能指向它的前驱节点,这样任意一个节点都能很快速地找到它的前驱节点,这是单向链表所不具备的。如下图所示:
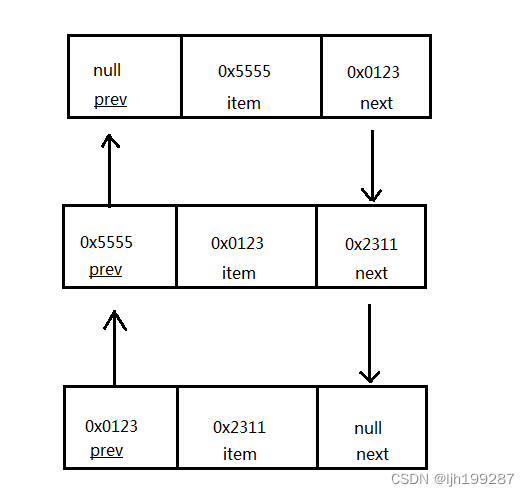
可知,一个节点包含了三部分的数据:指向前驱节点的引用“prev”、指向自己的引用“item”和指向后继节点的引用“next”,如下:
private static class Node<E> {
E item;
LinkedList.Node<E>next;
LinkedList.Node<E>prev;
Node(LinkedList.Node<E> prev, E element, LinkedList.Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
当然还有两个成员变量分别指向链表的头节点和末尾节点:
transient LinkedList.Node<E> first;
transient LinkedList.Node<E> last;
1.添加元素的方法
public boolean offer(E e) {
return this.add(e);
}
它调用add(E e)方法:
public boolean add(E e) {
this.linkLast(e);
return true;
}
add(E e)方法里面调用linkLast(E e)方法,从这个方法名可以看出应该是在链表的尾部添加e:
void linkLast(E e) {
LinkedList.Node<E> l = this.last;
LinkedList.Node<E> newNode = new LinkedList.Node(l, e, (LinkedList.Node)null);
this.last = newNode;
if (l == null) {
this.first = newNode;
} else {
l.next = newNode;
}
++this.size;
++this.modCount;
}
Node first是指向第一个节点的,Node last是指向最后一个节点的,因last刚开始为null,所以l为null。这里使用变量l的目的是用于指向原链表的最后一个节点(即新的元素e添加到链表后的上一个节点)
Node newNode=new Node(l,e,null),所以只要实例化newNode对象了,则newNode对象就天然向前指向了原链表的最后一个节点。然后last=newNode,这样的话last的值等于newNode的值即newNode对象的内存地址,所以last指向了newNode对象。接下来l.next=newNode,因为l.next的l对象表示原链表的最后一个节点对象,这样原链表的最后一个节点对象向后指向newNode对象,从而做到了将新节点添加到链表尾部。
2.移除元素的方法:
2.1 pool()方法:
public E poll() {
LinkedList.Node<E> f = this.first;
return f == null ? null : this.unlinkFirst(f);
}
从代码初步看,应该是把链表的头节点从链表里移除并且返回该头节点。看unlinkFirst(f)方法:
private E unlinkFirst(LinkedList.Node<E> f) {
E element = f.item;
LinkedList.Node<E> next = f.next;
f.item = null;
f.next = null;
this.first = next;
if (next == null) {
this.last = null;
} else {
next.prev = null;
}
--this.size;
++this.modCount;
return element;
}
其中,f是指向头结点对象的,声明E element变量并且指向头结点对象,LinkedList.Node next指向了第二个节点。首先f.next = null;让头节点向后不指向任何节点。接着还需要让原第二节点向前不指向任何节点,下面的if判断
if (next == null) {
this.last = null;
} else {
next.prev = null;
}
就是做到了让原第二节点向前不指向任何节点。最后返回element,从而做到了把链表的头节点从链表里移除并且返回该头节点。
2.2remove(Object o)方法
public boolean remove(Object o) {
LinkedList.Node x;
if (o == null) {
for(x = this.first; x != null; x = x.next) {
if (x.item == null) {
this.unlink(x);
return true;
}
}
} else {
for(x = this.first; x != null; x = x.next) {
if (o.equals(x.item)) {
this.unlink(x);
return true;
}
}
}
return false;
}
如果要移除的o为空,那么从头节点开始向后遍历,直到找到一个item变量为空的节点x(但该节点的next变量有值),然后对这个对象执行unlink函数;
如果要移除的o不为空,那么就从头节点开始向后遍历,直到找到与o同一个对象,然后对这个对象执行unlink函数。
现在研究unlink函数:
E unlink(LinkedList.Node<E> x) {
E element = x.item;
LinkedList.Node<E> next = x.next;
LinkedList.Node<E> prev = x.prev;
if (prev == null) {
this.first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
this.last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item= null;
--this.size;
++this.modCount;
return element;
}
这个逻辑很简单,element 指向要要移除的节点对象。prev指向要删除的x节点的前一个节点,next指向x的后一个节点。
首先让X的上一个节点向后指向X的下一个节点,同时让x向前不指向任何节点:
if (prev == null) {
this.first = next;
} else {
prev.next = next;
x.prev = null;
}
接着要让x原来的下一个节点向前指向x原来的上一个节点,同时让x向后不指向任何节点:
if (next == null) {
this.last = prev;
} else {
next.prev = prev;
x.next = null;
}
最后返回element。
2.2 remove(int index)方法:
public E remove(int index) {
this.checkElementIndex(index);
return this.unlink(this.node(index));
}
调用unlink(this.node(index))来实现。现在看node(index)方法,看方法名和入参可知该方法应该是找到并且返回第index个元素,现在详解node(index)方法的源码:
LinkedList.Node<E>node(int index) {
LinkedList.Node x;
int i;
if (index <this.size >>1) {
x = this.first;
for(i = 0; i < index; ++i) {
x = x.next;
}
return x;
} else {
x = this.last;
for(i = this.size - 1; i > index; --i) {
x = x.prev;
}
return x;
}
}
这里不是从链表头节点从到末尾节点遍历找到index位置的元素,而是采用二分法来减少遍历的次数:
其中“if (index < this.size >> 1)” 判断index是否小于链表长度右移一位,即index是否小于链表长度的一半。
所以如果indext小于链表长度的一半,则从链表的头部开始遍历到index位到最后得到对应的元素,否则,从链表尾部开始向index位遍历到最后得到对应的元素。
这样,node(int index方法就做到了“找到并且返回第index个元素”。














 2208
2208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









