







写在前面
个人觉得这个东西相对于一般的、简单的爬取还是比较好用的,上手也快。但是稍微复杂一点就不太好使了,其实还有很多傻瓜式的爬取工具,比如八爪鱼、火车采集器、神箭手云爬虫、后裔采集器等等等的软件。如果需要 特殊定制 还是学习python吧,爬虫还是蛮好玩的!当然下面介绍的这个东西,只适合简单的信息抓取。
安装
我是直接到谷歌应用商店下载安装,可能会需要科学上网,不会科学上网也没关系
请自行搜索Web Scraper 资源,对照一般的谷歌安装插件步骤流程走就是,相当的简单。在浏览器中,按F12可查看是否安装成功

如果不会?传送门搜索 Web scraper 下载到本地。
打开上图的扩展程序页面,
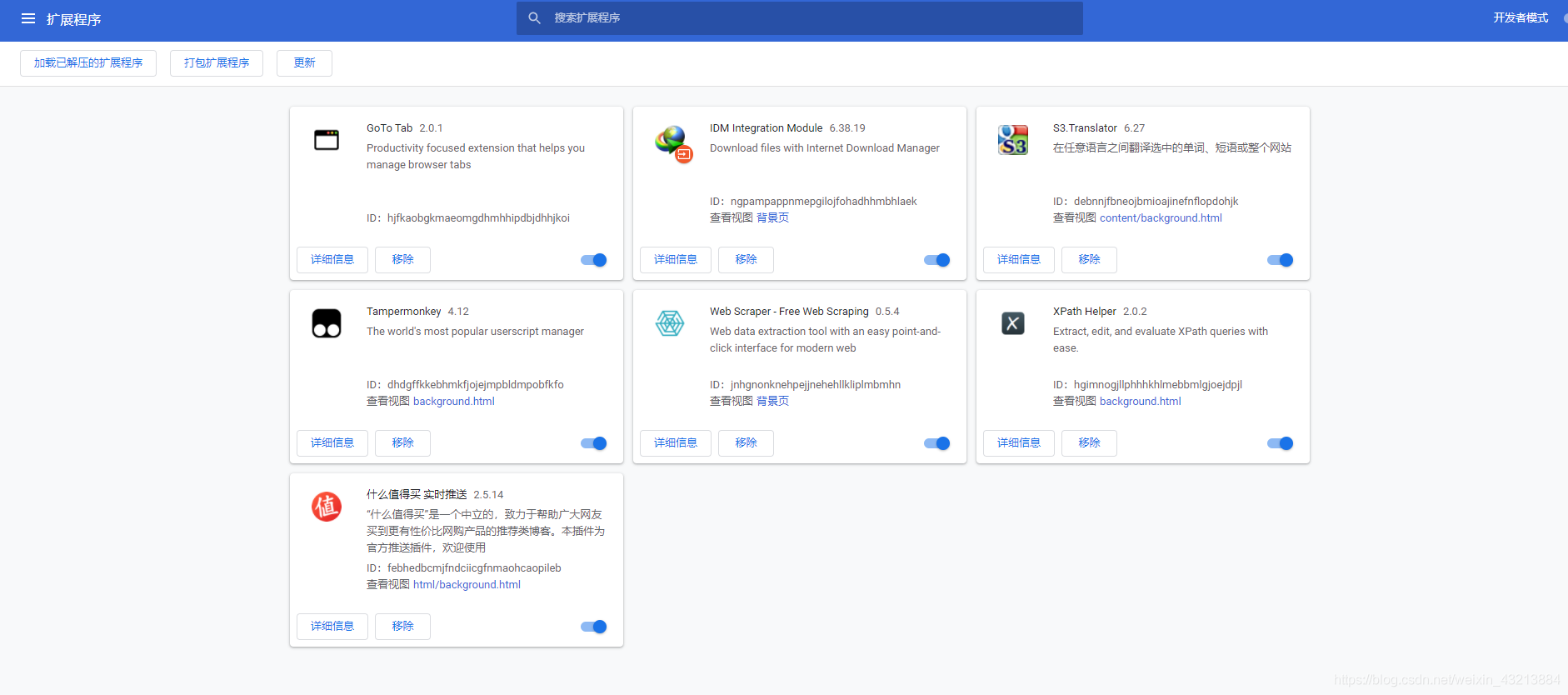
将下载好的插件,拖进进来即可。验证方法
如图所示!
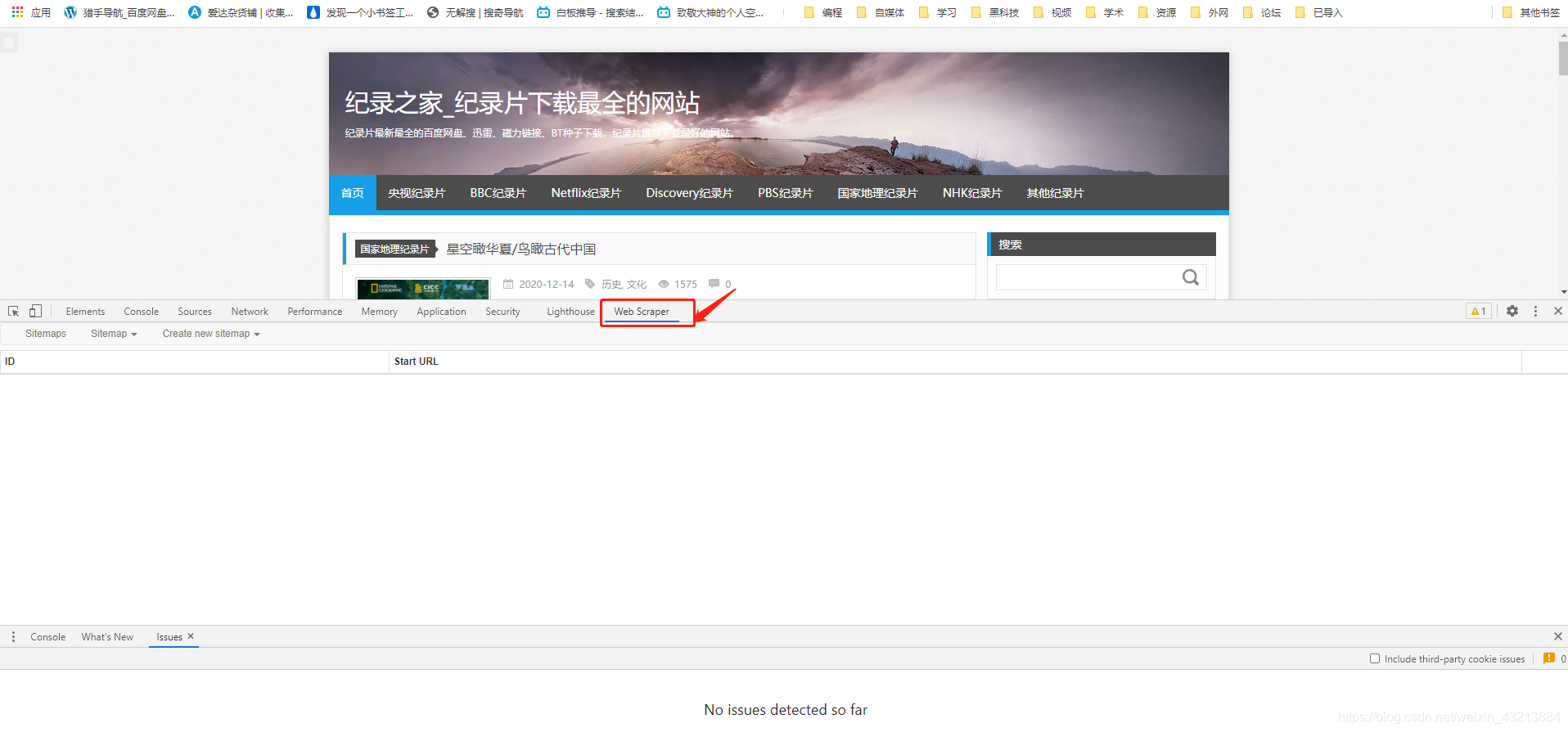
在开发者模式下,你看是否有web scraper这里选项卡。
使用
这里用一个案例来教学,我需要提取记录之家的class、title、date、观看数量、剧情简介
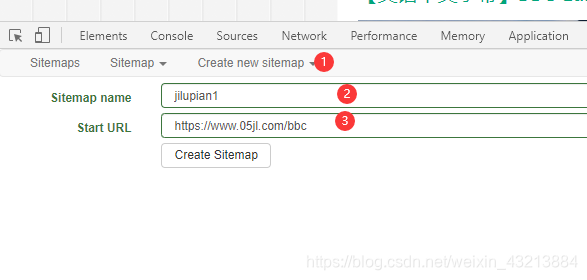
创建sitemap
在这里插入图片描述
- create new sitemap:创建新的爬取项目,必须是小写开头
- sitemap name:随便取一个名字即可,这里我们取jilupian1
添加选择器 add new selector
首先要创建一个选择框,即是框内的包含的所有数据
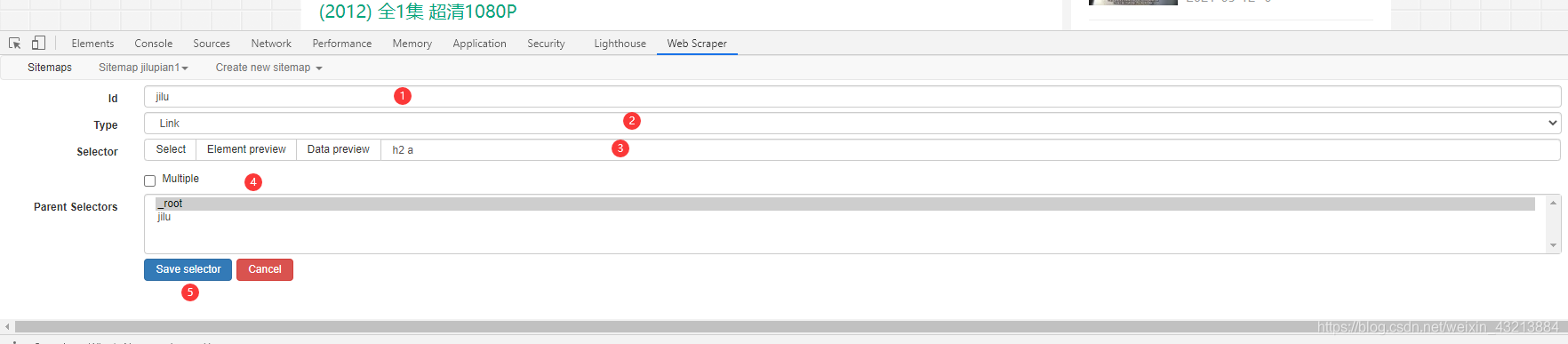
- id:随便取名字
- type:爬取的数据类型,这里勾选link
- selector:点击select,进行爬取的勾选,比如第一次点击,然后第二次点击下方的第二个数据,这时候你会发现全都被选取了。记得勾选multiple
点击save selector保存规则
准备爬取
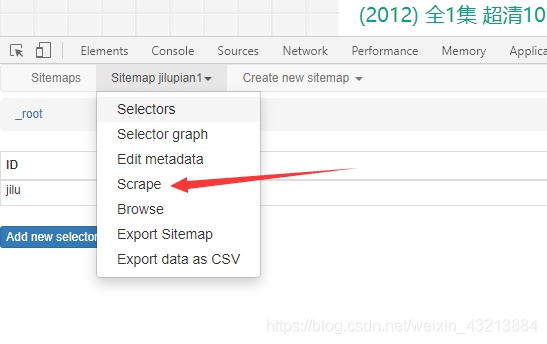
设置等待时间,这个跟网上有关系
默认就好

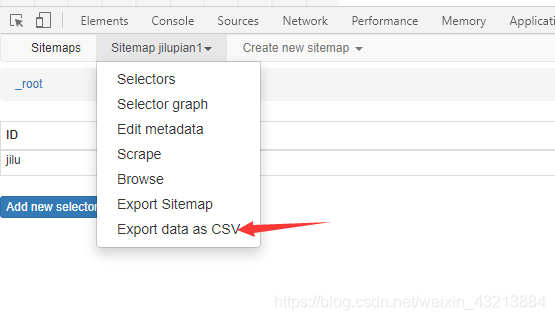
爬取文件导出
翻页实现
这里的翻页其实是找规律
这里的例子我们看看?
- https://www.05jl.com/bbc【第一页】
- https://www.05jl.com/bbc/page/2【第二页】
- https://www.05jl.com/bbc/page/3【第三页】
- ··················
- 最后页太多了!设置到11为止
可以发现,除了第一页外,其他的页面都是有规律的,其实第一页也可以是
https://www.05jl.com/bbc/page/1
不信你试一试
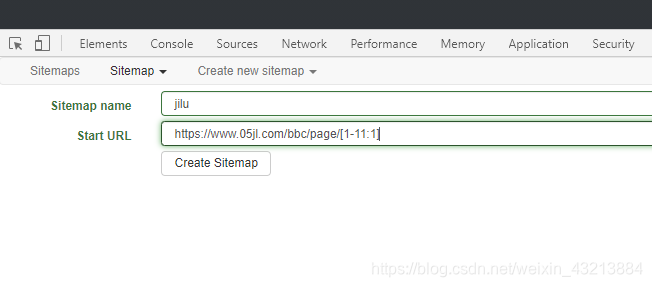
这是我们输入的url【网址】表达式可以为
url = https://www.05jl.com/bbc/page/[1-11:1]
记住这个方括号里面的表达其实是: [起始页-末尾页:间隔]
我们新建一下第一个url即可
后面的规则一样的

搞定
抓细节
这里先解构以下
比如
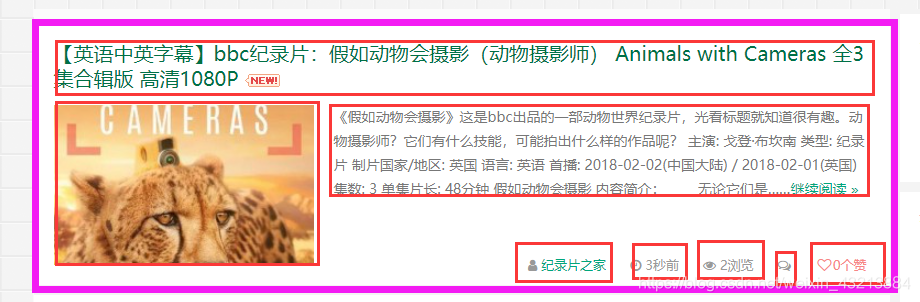
在紫色框下面是相当于我们抓取的整体,在各个红色框是我们需要抓取的内容,比如title、内容、图片、作者、浏览等等信息。
这里有一个大框架下包揽的小框架。
意思是:
我们要先抓取一级框架,再在一级框架下,抓取我们需求的二级信息。层层拨开。

抓鸭子?抓几只?先抓整体
那么整体来讲
有如下步骤:
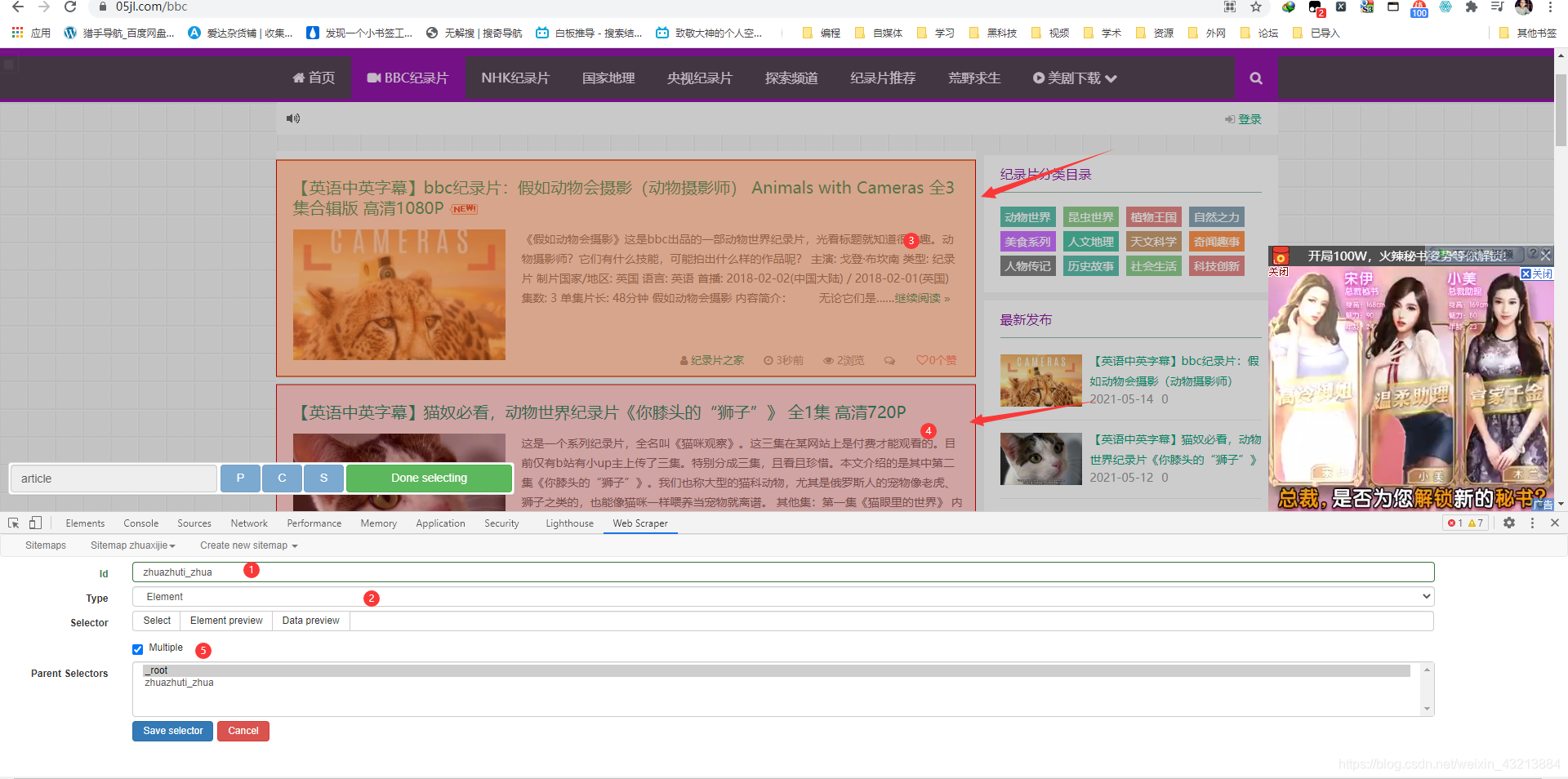
- 第一步:取名字随便取
- 第二步:注意这里的type只能选择element因为里面包含了其他的元素,我所需要的
- 第三步:选中这个大框架点击,第二次点击下方的第二个,这样就全部选中了。
- 第四步:勾选multiple
抓四只,抓到了?嘎嘎嘎嘎 抓组件信息
- 先进入整体
- 在add new select

- 这里实在_root下的xijie

里面添加,也就是进入到抓细节的add new select 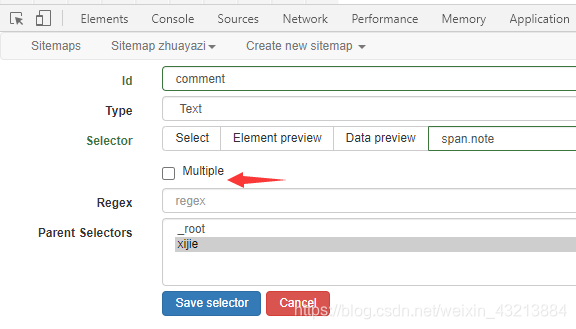
注意这里不需要多选,因为我们之前已经在主体中勾选了多选了
其余的设置也是一样的,我们这里爬取了title、图片、comment三种。
来吧展示!

导出成CSV就行
优缺点
优点:
Web Scraper 的优点就是不需要学习编程就可以爬取网页数据,对于非计算机专业的人可谓是爬虫不求人的利器。
即使是计算机专业的人,使用 Web Scraper 爬取一些网页的文本数据,也比自己写代码要高效,可以节省大量的编码及调试时间。
依赖环境相当简单,只需要谷歌浏览器和插件即可。
缺点:
只支持文本数据抓取,图片短视频等多媒体数据无法批量抓取。
不支持复杂网页抓取,比如说采取来反爬虫措施的,复杂的人机交互网页,Web Scraper 也无能为力,其实这种写代码爬取也挺难的。
导出的数据并不是按照爬取的顺序展示的,想排序就就要导出 Excel 再进行排序,这一点也很容易克服,大部分数据都是要导出 Excel 再进行数据分析的。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











