







1、基于特征值分解协方差矩阵实现PCA算法
输入:数据集 ,需要降到k维。
1) 去平均值(即去中心化),即每一位特征减去各自的平均值。、
2) 计算协方差矩阵
3) 用特征值分解方法求协方差矩阵的特征值与特征向量。
4) 对特征值从大到小排序,选择其中最大的k个。然后将其对应的k个特征向量分别作为行向量组成特征向量矩阵P。
5) 将数据转换到k个特征向量构建的新空间中,即Y=PX。
2、基于SVD分解协方差矩阵实现PCA算法
输入:数据集 ,需要降到k维。
1) 去平均值,即每一位特征减去各自的平均值。
2) 计算协方差矩阵。
3) 通过SVD计算协方差矩阵的特征值与特征向量。
SVD分解矩阵A的步骤:
(1) 求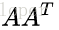
(2) 求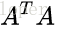
(3) 将
4) 对特征值从大到小排序,选择其中最大的k个。然后将其对应的k个特征向量分别作为列向量组成特征向量矩阵。
5) 将数据转换到k个特征向量构建的新空间中。
3、实例中用到的一些函数及意义
1) StandardScaler()、 fit_transform()
# 从sklearn.preprocessing导入StandardScaler
from sklearn.preprocessing import StandardScaler
# 标准化数据,保证每个维度的特征数据方差为1,均值为0,使得预测结果不会被某些维度过大的特征值而主导
ss = StandardScaler()
# fit_transform()先拟合数据,再标准化
X_train = ss.fit_transform(X_train)
# transform()数据标准化
X_test = ss.transform(X_test)
- transform()和fit_transform()的区别:
transform()是通过找中心和缩放来实现标准化 ;
而fit_transform()是为了数据归一化,是特征数据均值为0,方差为1 ;训练数据并返回降维后的数据。
2) explained_variance_ratio_.cumsum() #显示各特征的累计方差贡献率
3)plt.subplots()是一个函数,返回一个包含figure和axes对象的元组。
因此,使用fig,ax = plt.subplots()将元组分解为fig和ax两个变量。
4)bar(x, height, width=0.8, bottom=None, ***, align='center', data=None, **kwargs) #条形图
默认是竖直条形图,orientation:默认是"vertical";如果要改成水平条形图,需要修改以下属性 orientation="horizontal"
4、实例pca不要步骤代码
#取数据
test = pd.read_csv('../input/data_set_ALL_AML_independent.csv')
test.head(3)
#数据预处理
test1 = [col for col in test.columns if "call" not in col] # 删除call列
test = test[test1]
test = test.T #数据表转置
test2 = test.drop(['Gene Description','Gene Accession Number'],axis=0) #删除这两列
test2.index = pd.to_numeric(test2.index) #将索引转型
test2.sort_index(inplace=True)
#标准化数据
from sklearn.preprocessing import StandardScaler
Y_std = StandardScaler().fit_transform(test2) #先拟合数据,再标准化
#PCA
from sklearn.decomposition import PCA as sklearnPCA
sklearn_pca = sklearnPCA(n_components=30) #PCA降维后保留的特征维度的数目30
test_reduced = sklearn_pca.fit_transform(Y_std) #训练并返回降维后的数据
#
test_set = pd.DataFrame(test_reduced)
test_set.head(3)














 1244
1244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









