







Python网络爬虫
三、实战豆瓣
目标
爬取豆瓣电影中排名前十的电影
获得其主要信息:影名,导演,编剧,演员,简介,以及封面图
另外此处会用到多线程的技巧。
实战
导入库
import requests
from lxml import etree
import csv#保存为csv文件
from multiprocessing.dummy import Pool as pl#导入线程
定义函数
def spider(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
htm = requests.get(url,headers = headers)#发送请求
response = etree.HTML(htm.text)#对返回的网址进行编码
name = response.xpath('//*[@id="content"]/h1/span[1]/text()')
detector = response.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')
bianju = response.xpath('//*[@id="info"]/span[2]/span[2]/a/text()')
actor1 = response.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')
dicbre = response.xpath('//*[@id="link-report"]/span/text()')
actor = ['']
for q in actor1:
if actor1.index(q) == 0:
actor[0] = q
else:
actor[0] = actor[0] + ','+ q
all1 = [name[0],detector[0],bianju[0],actor[0],dicbre[0]]
towriete(all1)
print('正在爬取:',name[0])
tupian = response.xpath('//*[@id="mainpic"]/a/img/@src')
b_tupian = requests.get(tupian[0],headers = headers)
with open('./douban photo/'+ name[0] + '.jpg','wb') as ph:
ph.write(b_tupian.content)
print('正在下载图片:',name[0])
部分详解:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
进入豆瓣网->电影->排行榜后,信息如下图:

按下F12进入检查,进入Network(注意要先刷新一次(F5)),任选一个查看Headers,如下:

复制‘user-agent’内容,作为爬虫headers。
name = response.xpath('//*[@id="content"]/h1/span[1]/text()')
detector = response.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')
bianju = response.xpath('//*[@id="info"]/span[2]/span[2]/a/text()')
actor1 = response.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')
dicbre = response.xpath('//*[@id="link-report"]/span/text()')
首先进入任一电影中:

按下Ctrl+Shift+C,点击影名:
![- [ ] List item](https://img-blog.csdnimg.cn/20190825213012100.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzIxNjI0OQ==,size_16,color_FFFFFF,t_70)
则会出现对应的信息,选中后右键->Copy->Copy XPath,
放入代码中查看(注意观察上图,影名是放在text中,因此需要在粘贴之后加上’/text()’),其他信息以此类推。另外,需要特别注意,在此时的储存空间name中是一个列表含有字符串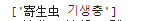
而在actor中得到的是如下图:列表中含有许多字符串
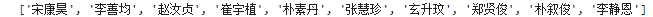
特别要注意csv的写入机制,否则会出现乱序问题,因此写了一个简单的循环,将其全部放入一个字符串中:
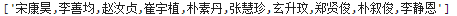
注意两者的区别。
之后,将提取到的信息全部放入一个列表中,

一个列表中存放了5个字符串,分别对应相应的信息。之后进行写入:
在此,又定义了一个写入函数:
def towriete(item):
with open('douban2.csv','a') as f:
writer = csv.DictWriter(f,fieldnames=['影名','导演','编剧','演员','简介'])#编写开头
writer.writeheader()
writer = csv.writer(f)
try:
writer.writerow(item)#将传入的列表以行的方式写入
except:
print('error!')
在此,就完成了信息的爬取,接下来是图片的下载:
tupian = response.xpath('//*[@id="mainpic"]/a/img/@src')
b_tupian = requests.get(tupian[0],headers = headers)
with open('./douban photo/'+ name[0] + '.jpg','wb') as ph:
ph.write(b_tupian.content)
print('正在下载图片:',name[0])
同上操作后可以得到图片的储存网址:

进入该网址,可以查看到对应的图片

因此,可以想到,需要再次进行网页的请求,因此执行以上操作,之后进行图片的保存(自行选择合适的目录)。至此,信息的爬取工作结束。接下来进行主函数以及线程池的定义。
if __name__ == '__main__':
url1 = 'https://movie.douban.com/chart'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
html = requests.get(url1,headers = headers)
selector = etree.HTML(html.text)
url = selector.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td[2]/div/a/@href')
pool = pl()#申请线程,括号中可写入整数,代表应用的CPU个数,如无,则默认当前电脑CPU个数。
pool.map(spider,url)#对url中的网址依次进行spider函数
pool.close#关闭线程
pool.join#进行合并
注意,此时申请的是排行榜页面的网址:


自习观察代码,可以发现,这10行并列对应的就是排行榜前十的影片。因此,大概思路便出来了。通过得到该页面的请求后,依次进行迭代,通过线程同时进行。
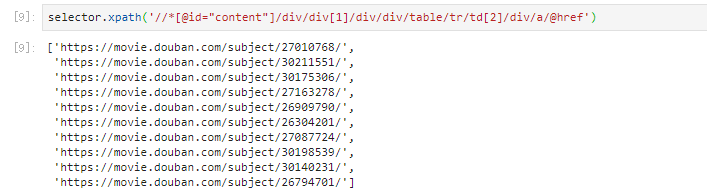
结束及展示


这之中,出现了些问题,重复多次,有两张图片始终无法提取。问题还在查证。先进行此次的分享。
















 2191
2191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











