






实验数据来自吴恩达L5W2课后作业。
任务描述:使用词向量表示来构建Emoijifier表情符号。例如:将文本“恭喜晋升!有机会喝杯咖啡聊天吧。爱你!”,Emojifier将其自动转换为“恭喜升职👍!有机会一起喝咖啡☕️聊天吧,爱你!❤️”。该任务所构造的模型将输入的句子转换成最适合与该句子搭配使用的表情符号。即构建从句子到表情符号的准确分类器映射。
基准模型:Emojifier-V1
数据集包含183个句子X,及其对应的表情符号(介于0到4之间整数标签),如下所示:
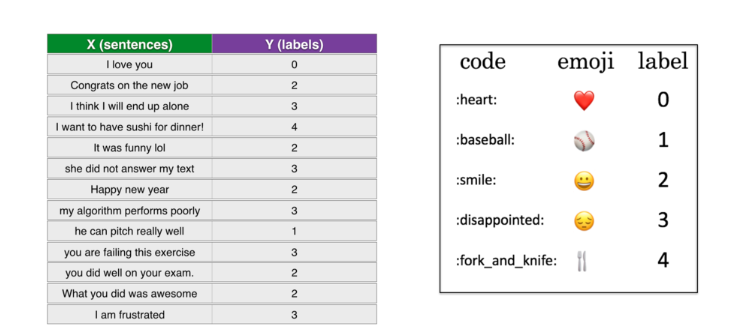
按照7:3的比例划分训练集,测试集。训练集包含127个句子及其对应的标签,测试集包含56个句子。
模型结构如下:
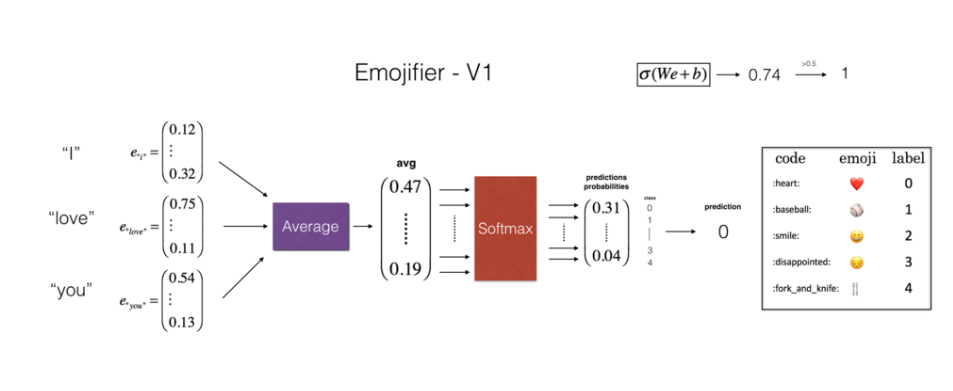
输入是与句子相对应的字符串,句子中的每个单词为50维的词向量(glove英文词向量),输出是维度为(1,5)的概率向量,然后将其传递到argmax层以此提取概率最大的表情符号。由于每个句子所对应的标签维度为1,为使标签适合训练的softmax格式,将标签转换为独热表示(1,5)
读取单词所对应的词向量:
def read_glove_vecs(glove_file):
"""
加载glove英文词向量
param: glove_file: 文件路径
word_to_vec_map:将单词映射到其GloVe向量表示的字典。
return:
"""
with open(glove_file, 'r', encoding="utf-8") as f:
words = set()
word_to_vec_map = {}
for line in f:
line = line.strip().split()
curr_word = line[0]
words.add(curr_word)
word_to_vec_map[curr_word] = np.array(line[1:], dtype=np.float64)
return words, word_to_vec_maphello所对应的词向量:
words, word_to_vec_map = read_glove_vecs('data/glove.6B.50d.txt')
print(word_to_vec_map["hello"])
#输出:
[-0.38497 0.80092 0.064106 -0.28355 -0.026759 -0.34532 -0.64253
-0.11729 -0.33257 0.55243 -0.087813 0.9035 0.47102 0.56657
0.6985 -0.35229 -0.86542 0.90573 0.03576 -0.071705 -0.12327
0.54923 0.47005 0.35572 1.2611 -0.67581 -0.94983 0.68666
0.3871 -1.3492 0.63512 0.46416 -0.48814 0.83827 -0.9246
-0.33722 0.53741 -1.0616 -0.081403 -0.67111 0.30923 -0.3923
-0.55002 -0.68827 0.58049 -0.11626 0.013139 -0.57654 0.048833
0.67204 ]由于词向量已预训练好,包含了单词之间的关系,因而可以用余弦相似度来衡量。
def cosine_similarity(u, v):
"""
计算两个词向量的余弦相似度
:param u:单词u的词向量
:param v:单词v的词向量
:return:
"""
dot = np.dot(u, v)
norm_u = np.sqrt(np.sum(np.power(u, 2)))
norm_v = np.sqrt(np.sum(np.power(v, 2)))
distance = np.divide(dot, norm_v * norm_u)
return distance
father = word_to_vec_map["father"]
mother = word_to_vec_map["mother"]
ball = word_to_vec_map["ball"]
crocodile = word_to_vec_map["crocodile"]
france = word_to_vec_map["france"]
italy = word_to_vec_map["italy"]
paris = word_to_vec_map["paris"]
rome = word_to_vec_map["rome"]
print("cosine_similarity(father, mother) = ", cosine_similarity(father, mother))
print("cosine_similarity(ball, crocodile) = ",cosine_similarity(ball, crocodile))
print("cosine_similarity(france - paris, rome - italy) = ",cosine_similarity(france - paris, rome - italy))
#输出:
cosine_similarity(father, mother) = 0.8909038442893615
cosine_similarity(ball, crocodile) = 0.2743924626137942
cosine_similarity(france - paris, rome - italy) = -0.6751479308174201词语类比问题:
def complete_analogy(word_a, word_b, word_c, word_to_vec_map):
"""
词类比问题:解决“A与B相比就类似于C与____相比一样”问题,比如“男人与女人相比就像国王与 女皇 相比一样”
其实就是在词库里面找到一个词word_d满足:word_b - word-a 与 word_d - word_c 近似相等
:param word_a:词a
:param word_b:词b
:param word_c:词c
:param word_to_vec_map:词典
:return:
"""
# 将单词转换为小写
word_a, word_b, word_c = word_a.lower(), word_b.lower(), word_c.lower()
# 找到单词的词向量
e_a, e_b, e_c = word_to_vec_map[word_a], word_to_vec_map[word_b], word_to_vec_map[word_c]
words = word_to_vec_map.keys()
max_cosine_similarity = -100
best_word = None
# 遍历整个词典
for word in words:
if word in [word_a, word_b, word_c]:
continue
cosine_sim = cosine_similarity((e_b - e_a), (word_to_vec_map[word] - e_c))
if cosine_sim > max_cosine_similarity:
max_cosine_similarity = cosine_sim
best_word = word
return best_word
triads_to_try = [('italy', 'italian', 'spain'), ('india', 'delhi', 'japan'), ('man', 'woman', 'boy'), ('small', 'smaller', 'large')]
for triad in triads_to_try:
print('{} -> {} <====> {} -> {}'.format(*triad, complete_analogy(*triad, word_to_vec_map)))
#输出:
italy -> italian <====> spain -> spanish
india -> delhi <====> japan -> tokyo
man -> woman <====> boy -> girl
small -> smaller <====> large -> larger
模型输入:需要将输入句子转换为词向量表示,然后平均在一起
def sentence_to_avg(sentence, word_to_vec_map):
"""
将句子转换为单词列表,提取Glove向量,取平均值
:param sentence: 输入的句子
:param word_to_vec_map: 词典
:return:
"""
# 将句子拆成单词列表
words = sentence.lower().split()
# 初始化均值向量
avg = np.zeros(50, )
for w in words:
avg = avg + word_to_vec_map[w]
avg = np.divide(avg, len(words))
return avg模型构造,线性层加softmax做分类
def model(X, Y, word_to_vec_map, learning_rate=0.01, num_iterations=400):
np.random.seed(1)
m = Y.shape[0]
n_y = 5
n_h = 50
W = np.random.randn(n_y, n_h) / np.sqrt(n_h)
b = np.zeros((n_y,))
Y_oh = emo_utils.convert_to_one_hot(Y, C=n_y)
for epoch in range(num_iterations):
for i in range(m):
avg = sentence_to_avg(X[i], word_to_vec_map)
# 前向传播
z = np.dot(W, avg) + b
a = emo_utils.softmax(z)
# 计算第i个句子训练的损失
cost = -np.sum(Y_oh[i] * np.log(a))
# 计算梯度
dz = a - Y_oh[i]
dW = np.dot(dz.reshape(n_y, 1), avg.reshape(1, n_h))
db = dz
# 更新参数
W = W - learning_rate * dW
b = b - learning_rate * db
if epoch % 100 == 0:
print("第{epoch}轮,损失为{cost}".format(epoch=epoch, cost=cost))
pred = emo_utils.predict(X, Y, W, b, word_to_vec_map)
return pred, W, b模型训练:
pred, W, b = model(X_train, Y_train, word_to_vec_map)
print("=====训练集====")
pred_train = emo_utils.predict(X_train, Y_train, W, b, word_to_vec_map)
print("=====测试集====")
pred_test = emo_utils.predict(X_test, Y_test, W, b, word_to_vec_map)
X_my_sentences = np.array(
["i adore you", "i love you", "funny lol", "lets play with a ball", "food is ready", "you are not happy"])
Y_my_labels = np.array([[0], [0], [2], [1], [4], [3]])
pred = emo_utils.predict(X_my_sentences, Y_my_labels, W, b, word_to_vec_map)
emo_utils.print_predictions(X_my_sentences, pred)第0轮,损失为1.9520498812810076 Accuracy: 0.3484848484848485
第100轮,损失为0.07971818726014794 Accuracy: 0.9318181818181818
第200轮,损失为0.04456369243681402 Accuracy: 0.9545454545454546
第300轮,损失为0.03432267378786059 Accuracy: 0.9696969696969697
=====训练集====
Accuracy: 0.9772727272727273
=====测试集====
Accuracy: 0.7678571428571429
Accuracy: 0.8333333333333334
i adore you ❤️
i love you ❤️
funny lol 😄
lets play with a ball ⚾
food is ready 🍴
you are not happy ❤️
模型不能对“you are not happy”输出正确的表情,该算法忽略单词顺序,因此不善于理解"not happy."之类的短语。

















 147
147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









